论文:《InstructDiffusion: A Generalist Modeling Interface for Vision Tasks》
github:https://github.com/cientgu/InstructDiffusion
InstructPix2Pix:参考
摘要
作者提出InstructDiffusion,一个统一通用框架用于对齐cv任务与instruction,将不同视觉任务映射为人工引导的图像处理任务。InstructDiffusion可处理各种视觉任务,包括理解任务(分割、关键点检测)、生成类任务(编辑和增强)。InstructDiffusion迈向视觉任务通用模型接口重要一步。
引言
难点:
1、计算机视觉任务的多样性使得其很难找到一个适用于所有任务的统一的表征;
2、不同的任务需要不同的方法,作为对比,NLP任务基于更一致的方法;
3、视觉任务输入输出是连续性的,通过VQ-VAE量化时容易产生量化误差;
本文中作者利用DDPM优势,提出一种新方法将所有视觉任务看做图像生成,解决所提到挑战。
输出格式有三种:RGB图、二进制图、关键点;
算法
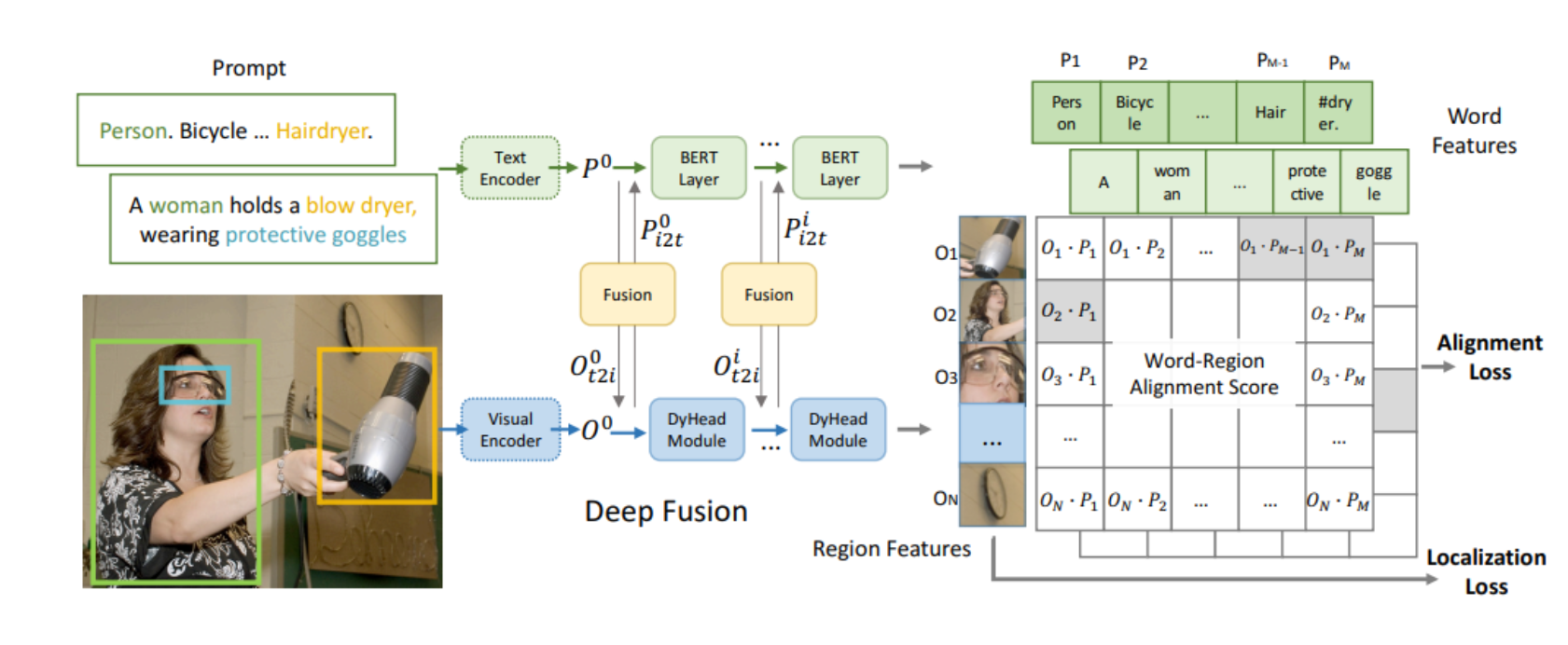
作者提出InstructDiffusion,一种通用模型接口适用于各种视觉任务。利用DDPM,将所有视觉任务看做人类引导的图像处理过程,输出在一个灵活和交互的像素空间。
输出为三种格式:3通道RGB图、二进制mask、关键点
视觉任务统一引导
训练集
训练集重构
统一框架
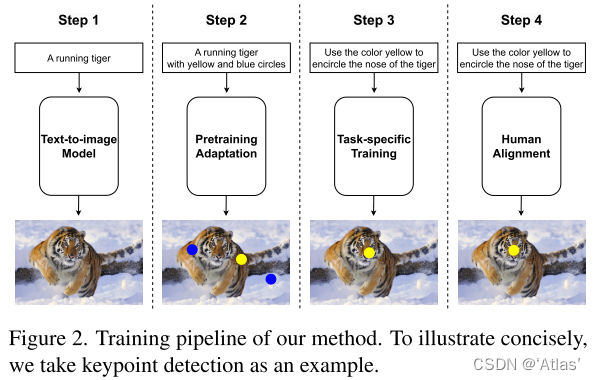

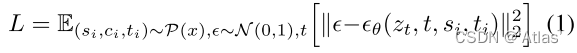
实验
训练集
关键点检测
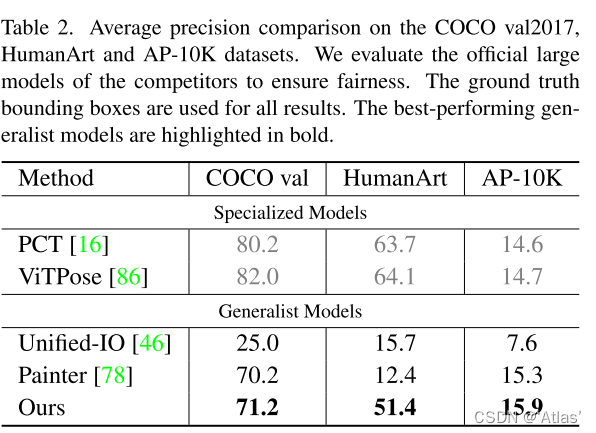

分割
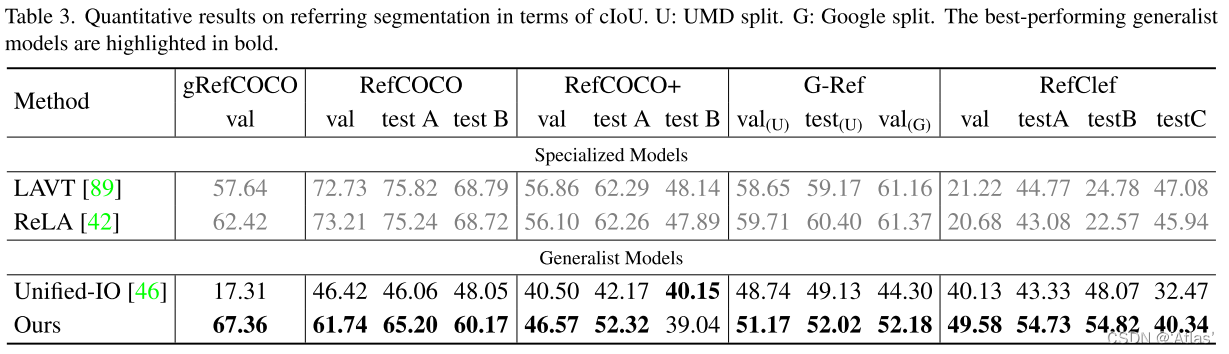
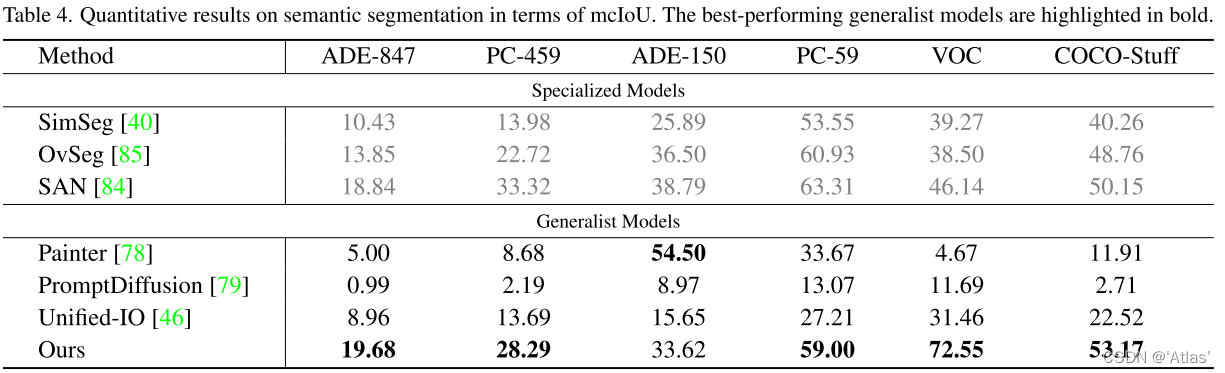
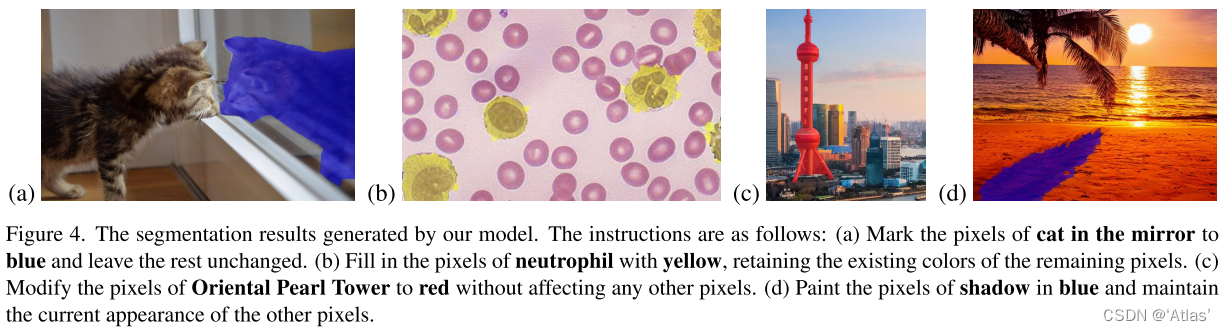
图像增强
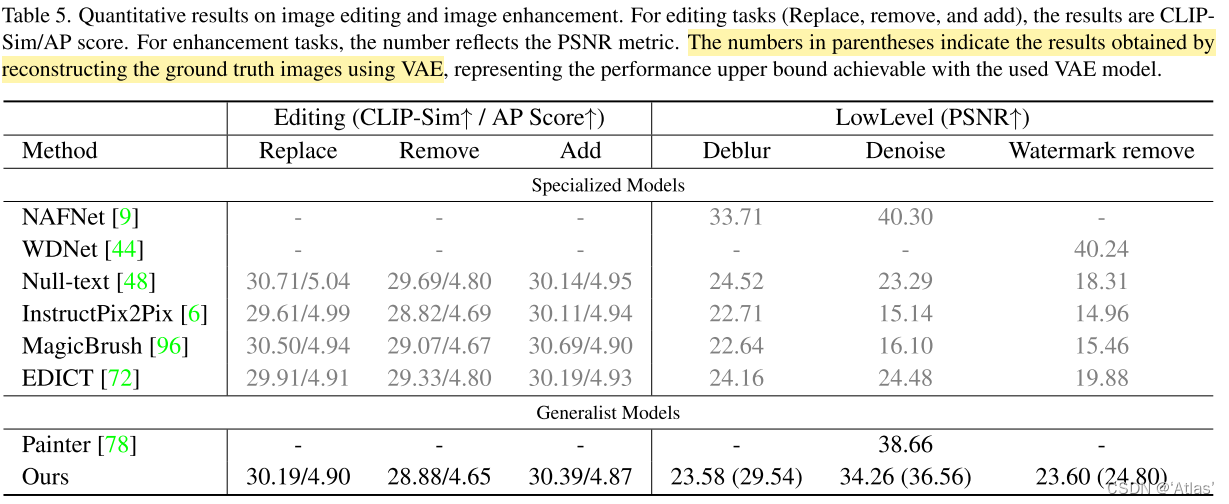

图像编辑


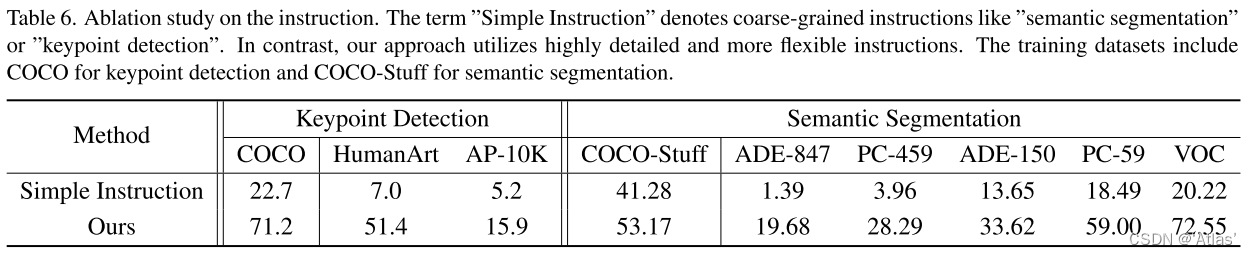
详细instruction的优势
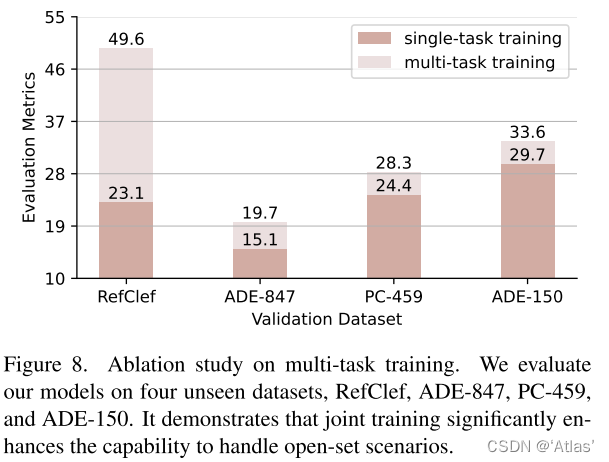
多任务训练优势

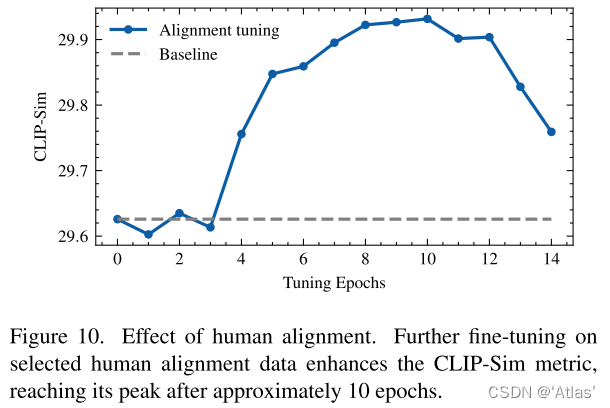
人工校准数据集影响
对未见任务的泛化性

讨论与结论
个人理解
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。