导入和处理数据是数据分析的重要一环。Pandas是一个强大且流行的Python库,用于数据处理和分析。在本篇博客中,我们将介绍如何使用Pandas库导入Excel表格,以及一些常用并且实用的操作技巧。
一:安装Pandas库
首先,确保你已经安装了Pandas库。如果没有安装,可以使用以下命令来安装:
二:导入所需库和文件
import pandas as pd三:读取Excel表格数据
假设我们有一个名为”鸢尾花训练数据.xlsx“(提取码:6666)的Excel表格,其中包含我们要导入的数据。使用Pandas的read_excel()函数读取Excel文件并将数据用data接收。注意:numpy是以数组形式来读取数据,而pandas是以表格的形式来读取数据。
data = pd.read_excel('鸢尾花训练数据.xlsx')四:查看数据
数据接收了,我们现在想查看数据就可以使用Pandas的一些基本函数和属性,可以有效地查看数据。下面是一些常用的函数和属性:
head():查看前几行数据,默认为前5行。tail():查看后几行数据,默认为后5行。shape:获取数据的维度,即行数和列数。info():显示数据的基本信息,如列名、数据类型、非空值数量等。
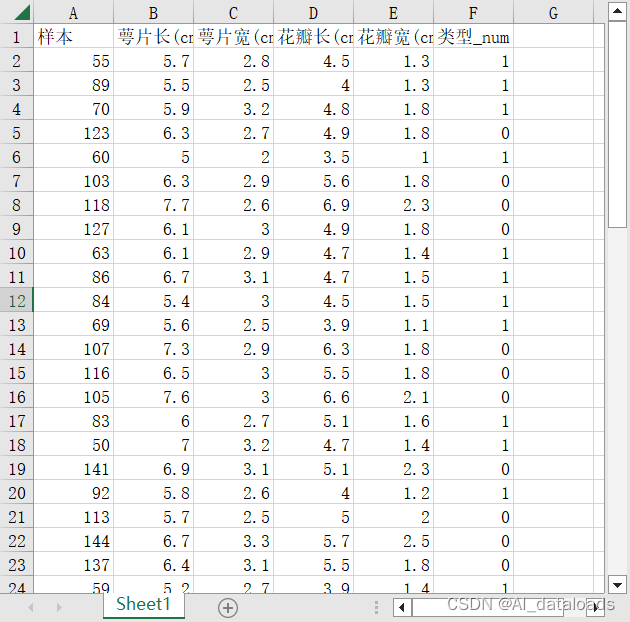
print(data.head()) #查看前几行数据,默认为前5行。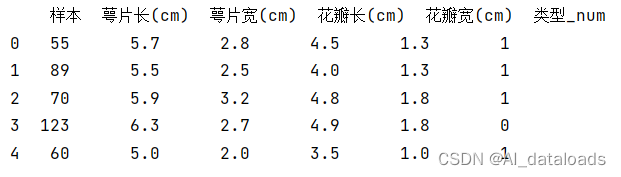
print(data.tail()) #查看后几行数据,默认为后5行。
print(data.info()) #显示数据的基本信息,如列名、数据类型、非空值数量等。
五:提取数据
进行数据处理时注意数据重排;训练模型时变量要与标签分离。data是一个DataFrame对象,我们希望选择其中几列作为变量x和y。通过使用[['column_name']]语法,我们将列名放在两层方括号中,如[['萼片长(cm)', '萼片宽(cm)', '花瓣长(cm)', '花瓣宽(cm)']]和[['类型_num']]。这会将这些列作为DataFrame对象返回给变量x和y,以便后续的数据处理和分析。
import pandas as pd
data=pd.read_excel("鸢尾花训练数据.xlsx")
x = data[['萼片长(cm)', '萼片宽(cm)', '花瓣长(cm)', '花瓣宽(cm)']]
y = data[['类型_num']]
print(x)
print(y)

原文地址:https://blog.csdn.net/AI_dataloads/article/details/132747378
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_6917.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!