本文介绍: 导入和处理数据是数据分析的重要一环。Pandas是一个强大且流行的Python库,用于数据处理和分析。在本篇博客中,我们将介绍如何使用Pandas库导入Excel表格,以及一些常用并且实用的操作技巧。
导入和处理数据是数据分析的重要一环。Pandas是一个强大且流行的Python库,用于数据处理和分析。在本篇博客中,我们将介绍如何使用Pandas库导入Excel表格,以及一些常用并且实用的操作技巧。
一:安装Pandas库
首先,确保你已经安装了Pandas库。如果没有安装,可以使用以下命令来安装:
二:导入所需库和文件
三:读取Excel表格数据
假设我们有一个名为”鸢尾花训练数据.xlsx“(提取码:6666)的Excel表格,其中包含我们要导入的数据。使用Pandas的read_excel()函数读取Excel文件并将数据用data接收。注意:numpy是以数组形式来读取数据,而pandas是以表格的形式来读取数据。
四:查看数据
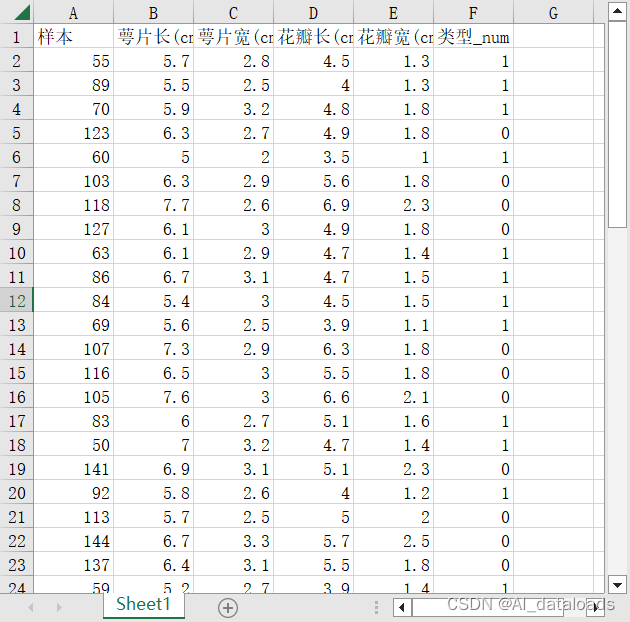
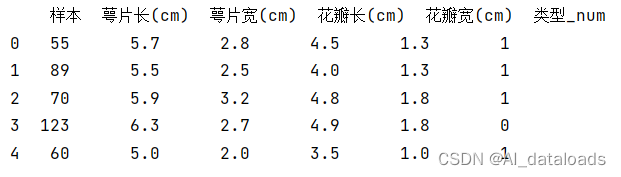

五:提取数据


声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。