本文介绍: hadoop主要解决:海量数据的存储和海量数据的分析计算hadoop发展历史Google是hadoop的思想之源(Google在大数据方面的三篇论文)2006年3月,Map–reduce和Nutch Distributed File System(NDFS)分别被纳入到Hadoop项目,Hadoop正式诞生。
hadoop发展历史
Google是hadoop的思想之源(Google在大数据方面的三篇论文)
2006年3月,Map–reduce和Nutch Distributed File System(NDFS)分别被纳入到Hadoop项目,Hadoop正式诞生。
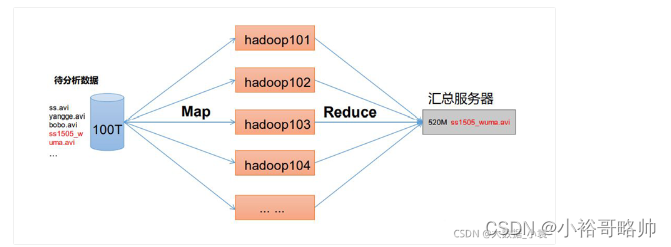
MapReduce
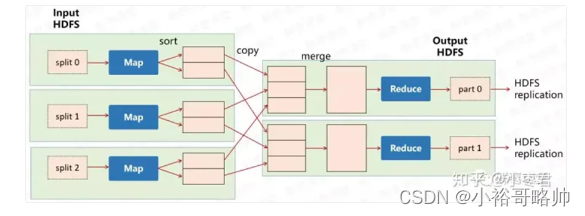
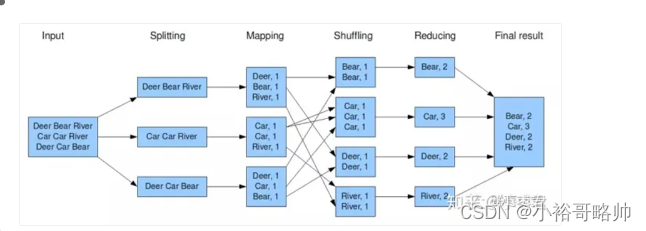
map阶段
reduce阶段
HDFS
概念
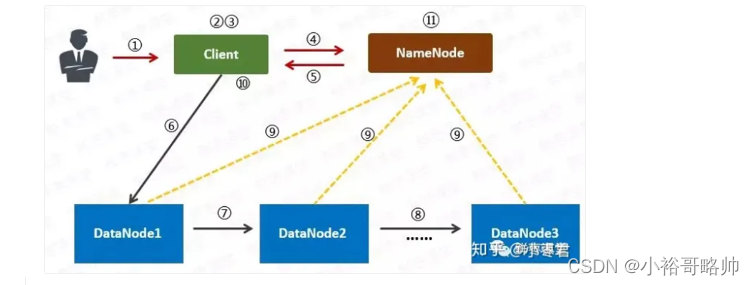
写入流程:
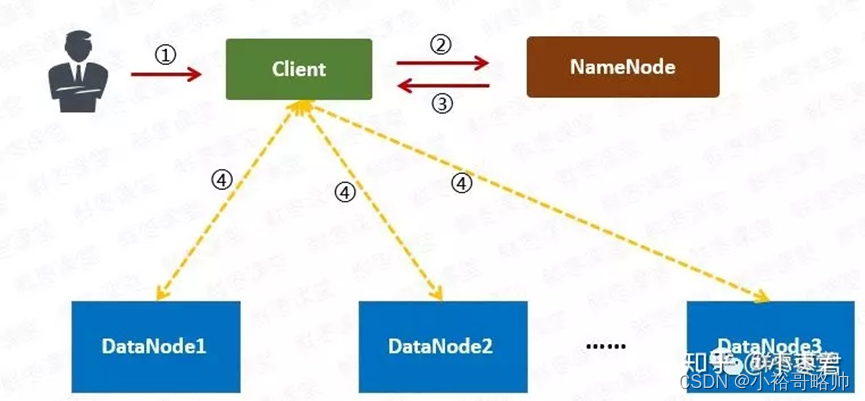
读取流程:
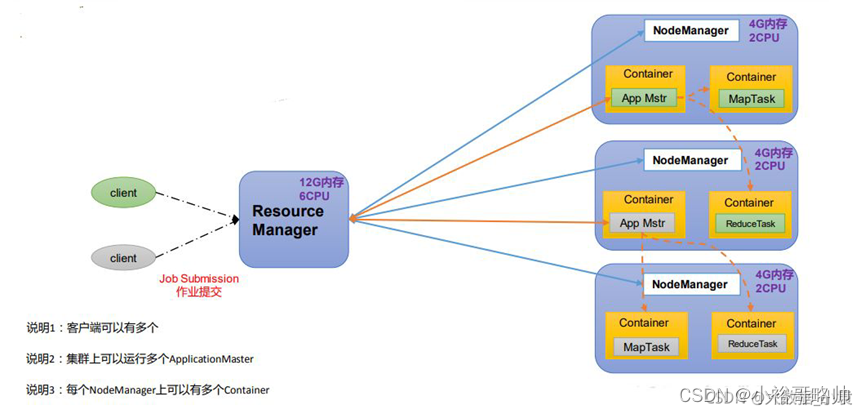
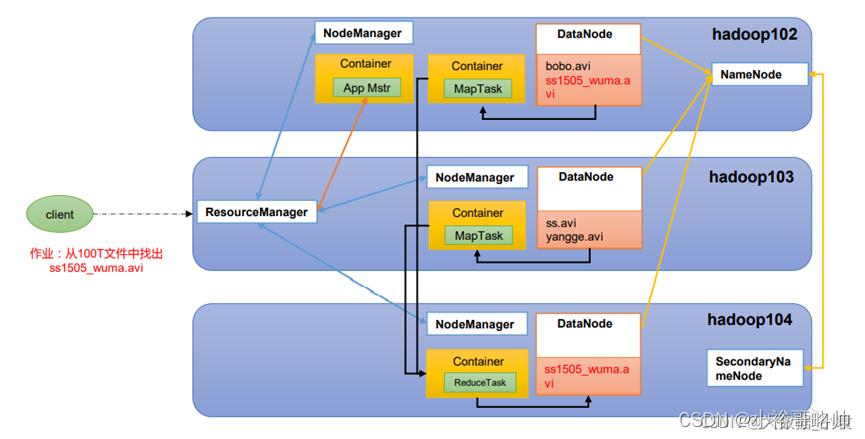
YARN
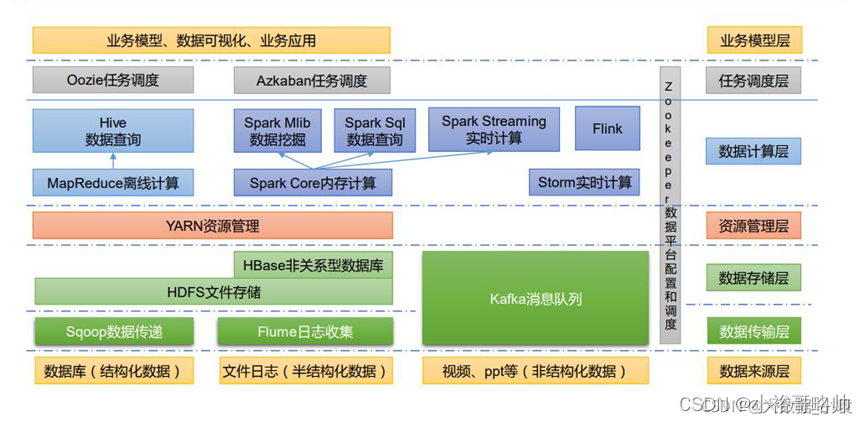
大数据技术生态系统
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。