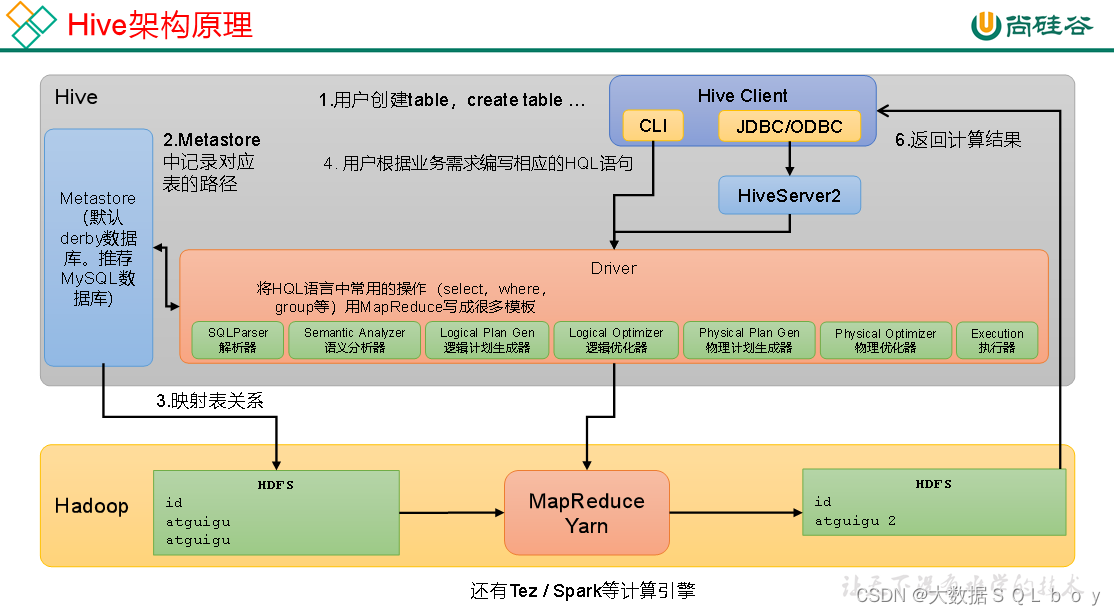
Hadoop概述
Hadoop 是数仓平台的核心组件。
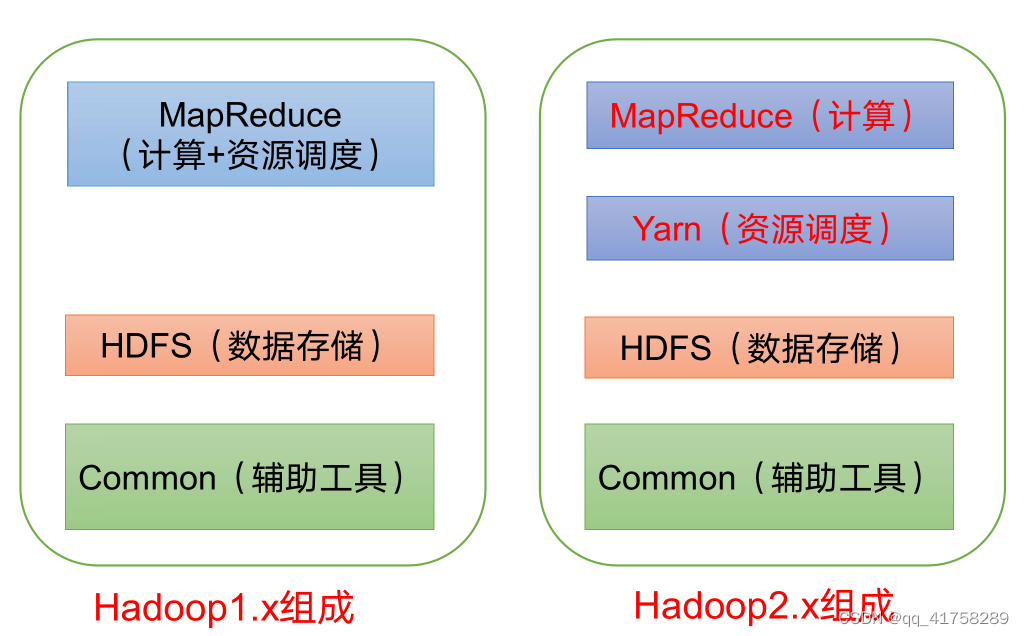
在 Hadoop1.x 时代,Hadoop 中的 MapReduce 同时处理业务逻辑运算和资源调度,耦合性较大。在 Hadoop2.x 时代,增加了 Yarn。Yarn 只负责资源的调度,MapReduce 只负责运算。Hadoop3.x 在架构上没有变化。
HDFS架构概述
Hadoop Distributed File System,简称HDFS,是一个分布式文件系统。包含NameNode(NN)、DataNode(DN)和Secondary NameNode(2NN)。
- NameNode: 存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
- DataNode:在本地文件系统存储文件块数据,以及块数据的校验和。
- secondary NameNode:周期性的对NameNode元数据备份。
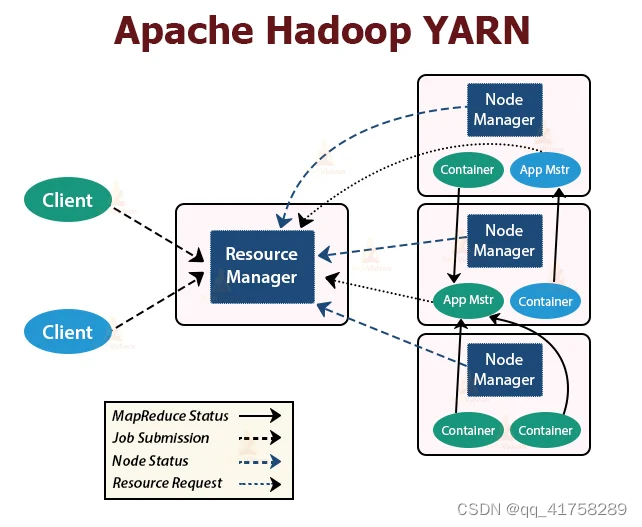
YARN架构概述
Yet Another Resource Negotiator(YARN)是资源管理协调调度工具,是Hadoop的资源管理器。
MapReduce 架构概述
MapReduce 是对数据进行计算的架构,分为 Map 和 Reduce2 个阶段。
Hadoop job 执行逻辑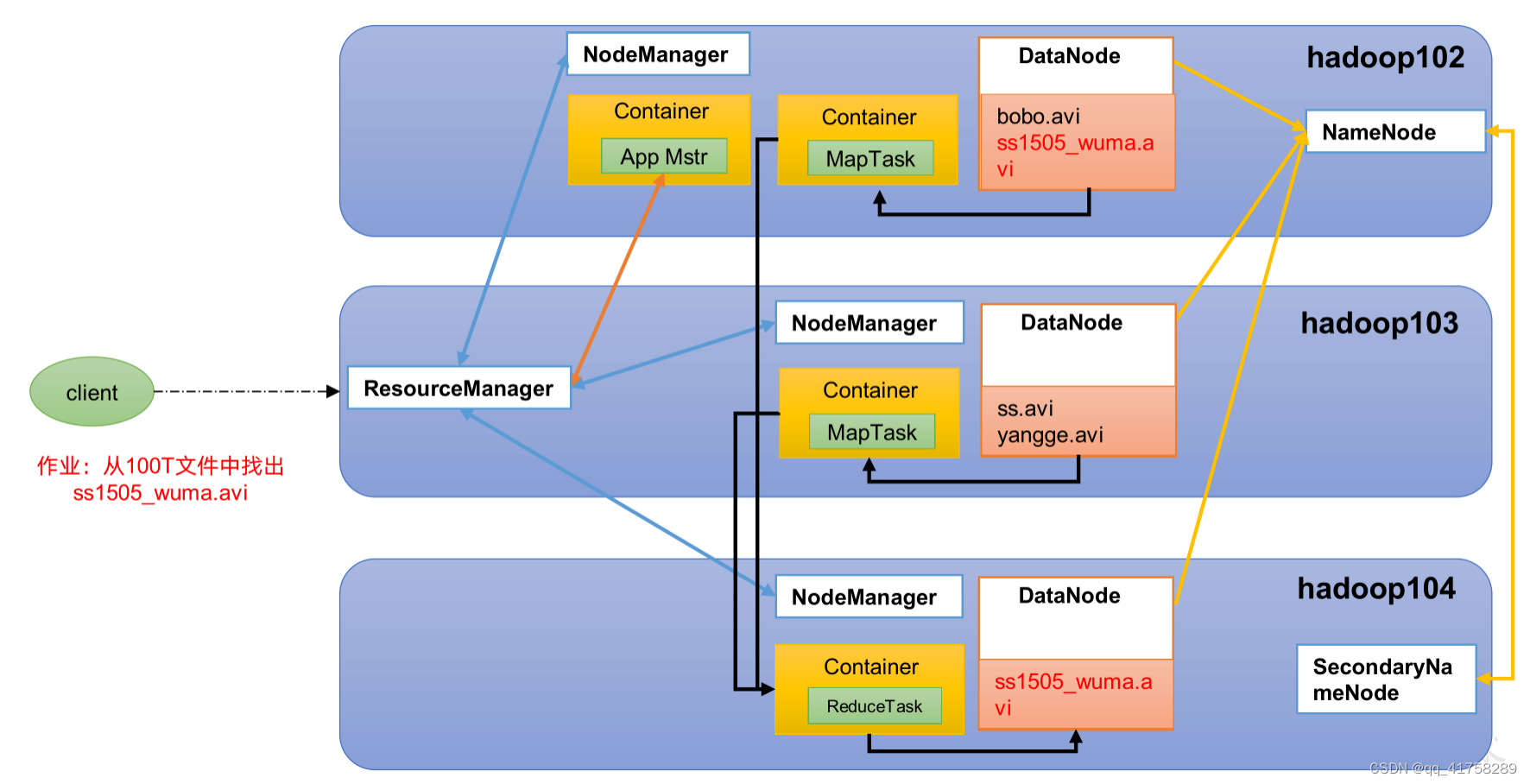
Hadoop 完全分布式运行模式(开发重点)
1)准备3台客户机(关闭防火墙、静态IP、主机名称)
2)安装JDK
3)配置环境变量
4)安装Hadoop
5)配置环境变量
6)配置集群
7)单点启动
8)配置ssh
9)群起并测试集群
配置3台服务器免密与分发脚本
免密配置
[logan@hadoop101 hadoop-3.1.3]$ ssh-copy-id hadoop101
[logan@hadoop101 hadoop-3.1.3]$ ssh-copy-id hadoop102
[logan@hadoop101 hadoop-3.1.3]$ ssh-copy-id hadoop103
编写集群分发脚本
[logan@hadoop101 ~]$ cd /home/logan/bin/
[logan@hadoop101 bin]$ vim xsync
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop101 hadoop102 hadoop103
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
JDK准备
[logan@hadoop101 bin]# sudo rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps
[logan@hadoop102 bin]# sudo rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps
[logan@hadoop103 bin]# sudo rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps
[logan@hadoop101 module]tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
- 刷新环境变量
source /etc/profile - 检查Java 是否正常安装
java -version - 分发 JDK
xsync /opt/module/jdk1.8.0_212/ - 更新 hadoop102 和 103 上的配置文件, 检查 Java 是否正常安装
[logan@hadoop102 module]$ source /etc/profile
[logan@hadoop103 module]$ source /etc/profile
Hadoop部署
1)集群部署规划
注意:NameNode和SecondaryNameNode不要安装在同一台服务器
注意:ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。
2)将hadoop-3.1.3.tar.gz导入到opt目录下面的software文件夹下面
3)进入到Hadoop安装包路径下
[logan@hadoop101 ~]$ cd /opt/software/
4)解压安装文件到/opt/module下面
[logan@hadoop101 software]$ tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
5)查看是否解压成功
ls /opt/module/hadoop-3.1.3
6)将Hadoop添加到环境变量
- 获取Hadoop安装路径
[logan@hadoop101 hadoop-3.1.3]$ pwd
/opt/module/hadoop-3.1.3
sudo vim /etc/profile.d/my_env.sh
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
Hadoop 核心配置
1)转到配置目录
[logan@hadoop101 hadoop]$ cd /opt/module/hadoop-3.1.3/etc/hadoop
2)配置core–site 文件vim core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:8020</value>
</property>
<!-- 指定 hadoop 数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置 HDFS 网页登录使用的静态用户为 atguigu -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>logan</value>
</property>
</configuration>
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- nn web 端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop101:9870</value>
</property>
<!-- 2nn web 端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop103:9868</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>10</value>
</property>
</configuration>
4)配置yarn–site 文件vim yarn-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 MR 走 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager 的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop102</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CO
NF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAP
RED_HOME</value>
</property>
5)MapReduce配置文件 vim mapred-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3</value>
</property>
</configuration>
hadoop101
hadoop102
hadoop103
配置历史服务器
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop101:10020</value>
</property>
<!-- 历史服务器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop101:19888</value>
</property>
配置日志聚集
注意:开启日志聚集功能,需要重启NodeManager、ResourceManager和 HistoryManager。
- 配置yarn-site.xml
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop101:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为 7 天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
分发 Hadoop
[logan@hadoop101 hadoop]$ xsync /opt/module/hadoop-3.1.3/
群起集群
- 第一次启动集群,需要在hadoop101上格式化 NameNode(格式化之前需要停止所有 NameNode 和 DataNode进程,然后删除data 和 log 数据)
hdfs namenode -format - 启动 HDFS
start-dfs.sh - 启动 YARN
start-yarn.sh - Web 端查看 HDFS 进行校验 http://hadoop101:9870
- Web端查看SecondaryNameNode http://hadoop103:9868
Hadoop 集群启动脚本
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop101 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop101 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop101 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop101 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
原文地址:https://blog.csdn.net/qq_41758289/article/details/134698941
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_10221.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!