X称为自由度为
n
n
n的
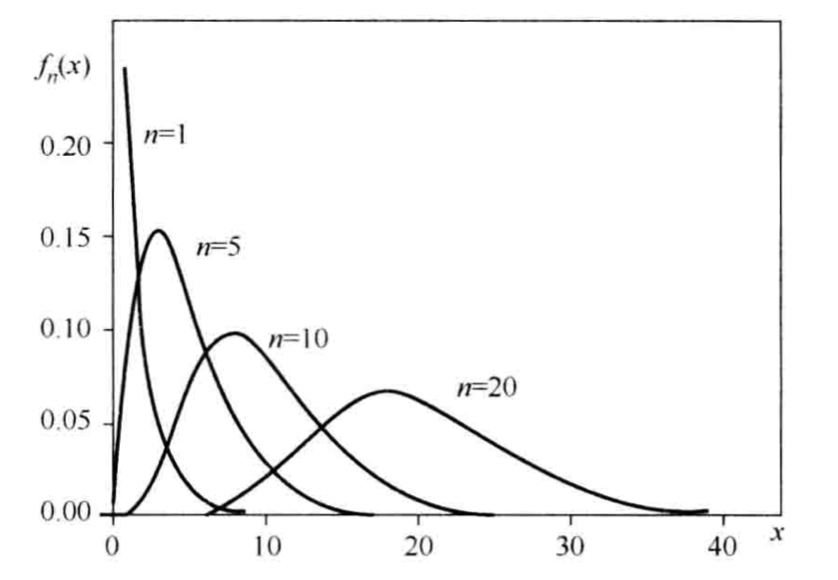
F
F
F分布:设
X
∼
χ
2
(
n
1
)
X∼χ2(n1),
Y
∼
χ
2
(
n
2
)
Y∼χ2(n2),且
X
X
X与
Y
Y
F
=
X
/
n
1
Y
/
n
2
F = frac{X / n_1}{Y / n_2}
F=Y/n2X/n1称为自由度为
(
n
1
,
n
2
)
(n_1, n_2)
(n1,n2)的
F
F
F分布,记作
F
∼
F
(
n
1
,
n
2
)
F sim F(n_1, n_2)
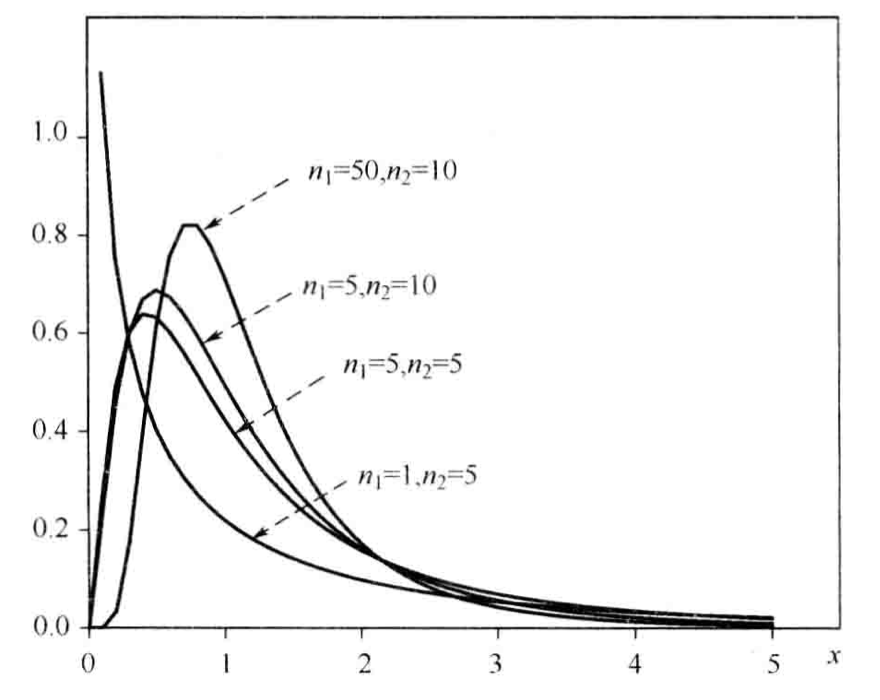
X称为自由度为
n
n
n的
F
F
F分布:设
X
∼
χ
2
(
n
1
)
X∼χ2(n1),
Y
∼
χ
2
(
n
2
)
Y∼χ2(n2),且
X
X
X与
Y
Y
F
=
X
/
n
1
Y
/
n
2
F = frac{X / n_1}{Y / n_2}
F=Y/n2X/n1称为自由度为
(
n
1
,
n
2
)
(n_1, n_2)
(n1,n2)的
F
F
F分布,记作
F
∼
F
(
n
1
,
n
2
)
F sim F(n_1, n_2)




