本文介绍: 如果这样的页面很多,那 所需要的存储空间是惊人的。为这样一个去重功能就耗费这样多的存储空间,值 得么?该实现一个明显的问题是内存占用过多,所有从库的连接在主库上是独立的,同样举抛硬币的例子,如果只有一组抛硬币实验,显然根据公式推导得到的。那么基于上面的估算结论,我们可以通过多次抛硬币实验的最大抛到正面的。大家应该对事务比较了解,简单地说,事务表示一组动作,要么全部执行,但是,如果你的页面访问量非常大,比如一个爆款页面几千万的 UV。列中的未执行命令,并不会回滚已经操作过的数据,这一点要和关系型数据库的。
Redis 高级数据结构 HyperLogLog
HyperLogLog(Hyper
[ˈhaɪpə(r)]
)
并不是一种新的数据结构
(
实际类型为字符串类 型)
,而是一种基数算法
,
通过
HyperLogLog
可以利用极小的内存空间完成独立总数的统计,数据集可以是 IP
、
Email
、
ID
等。
[ˈhaɪpə(r)]
)
并不是一种新的数据结构
(
实际类型为字符串类 型)
,而是一种基数算法
,
通过
HyperLogLog
可以利用极小的内存空间完成独立总数的统计,数据集可以是 IP
、
、
ID
等。
一个简单的方案,那就是为每一个页面一个独立的 set
集合来存储所有当 天访问过此页面的用户 ID
。当一个请求过来时,我们使用
sadd
将用户
ID
塞 进去就可以了。通过 scard
可以取出这个集合的大小,这个数字就是这个页面 的 UV
数据。
集合来存储所有当 天访问过此页面的用户 ID
。当一个请求过来时,我们使用
sadd
将用户
ID
塞 进去就可以了。通过 scard
可以取出这个集合的大小,这个数字就是这个页面 的 UV
数据。
但是,如果你的页面访问量非常大,比如一个爆款页面几千万的 UV
,你需 要一个很大的 set
集合来统计,这就非常浪费空间。如果这样的页面很多,那 所需要的存储空间是惊人的。为这样一个去重功能就耗费这样多的存储空间,值 得么?其实需要的数据又不需要太精确,1050w
和
1060w
这两个数字对于老板 们来说并没有多大区别,So
,有没有更好的解决方案呢?
,你需 要一个很大的 set
集合来统计,这就非常浪费空间。如果这样的页面很多,那 所需要的存储空间是惊人的。为这样一个去重功能就耗费这样多的存储空间,值 得么?其实需要的数据又不需要太精确,1050w
和
1060w
这两个数字对于老板 们来说并没有多大区别,So
,有没有更好的解决方案呢?
这就是 HyperLogLog
的用武之地,
Redis
提供了
HyperLogLog
数据结构就是 用来解决这种统计问题的。HyperLogLog
提供不精确的去重计数方案,虽然不精 确但是也不是非常不精确,
Redis
官方给出标准误差是
0.81%
,这样的精确度已经 可以满足上面的 UV
统计需求了。
的用武之地,
Redis
提供了
HyperLogLog
数据结构就是 用来解决这种统计问题的。HyperLogLog
提供不精确的去重计数方案,虽然不精 确但是也不是非常不精确,
Redis
官方给出标准误差是
0.81%
,这样的精确度已经 可以满足上面的 UV
统计需求了。
操作命令
pfadd
pfcount
立总数为
4:
4:
数据类型 1 天 1 个月 1 年
pfmerge
原理概述
数学原理
括
:
:
秀;
度更低;
一共进行了几个回合。
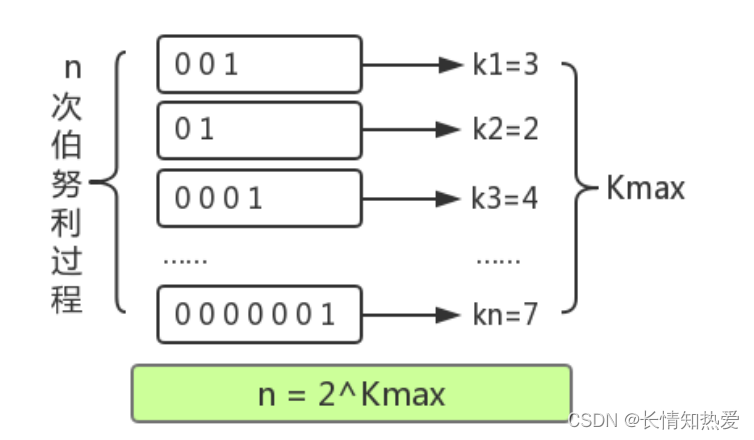
第一次
:
抛了
3
次才出现正面,此时
k=3
,
n=1
:
抛了
3
次才出现正面,此时
k=3
,
n=1
第二次试验
:
抛了
2
次才出现正面,此时
k=2
,
n=2
:
抛了
2
次才出现正面,此时
k=2
,
n=2
…………
k
是每回合抛到
1
(硬币的正面)所用的次数,我们已知的是最大的
k
值,
是每回合抛到
1
(硬币的正面)所用的次数,我们已知的是最大的
k
值,
种问题叫做伯努利实验。
师只抛了
3
回合,
3
回合,
的概念。
值。
什么叫调和平均数呢?举个例子
求平均工资:
+ 30000) / 2 = 15500
结合实例理解实现原理
1.转为比特串
是一样。为什么要这样转化呢?
认为,首次出现
1
的时候,就是正面。
1
的时候,就是正面。
那么基于上面的估算结论,我们可以通过多次抛硬币实验的最大抛到正面的
次数来预估总共进行了多少次实验,同样也就可以根据存入数据中,转化后的出
2.分桶
L = S.length
L = m * p
3、对应
现在要分轮,也就是分桶。所以我们可以设定,每个比特串的前多少位转为
第
2
号桶中去了。请注意,
50
已经是最坏的情况,且它都被容纳进去了。那么
2
号桶中去了。请注意,
50
已经是最坏的情况,且它都被容纳进去了。那么
其他的不用想也肯定能被容纳进去。
公式如下:
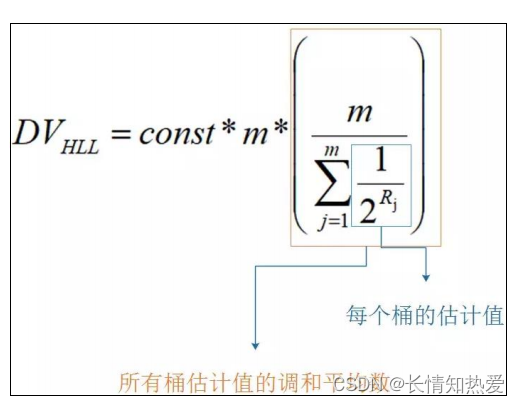
64
位转为十进制就是:
2^64
,
HyperLogLog
仅用了:
16384 * 6 /8 / 1024 =12K
存
位转为十进制就是:
2^64
,
HyperLogLog
仅用了:
16384 * 6 /8 / 1024 =12K
存
做更深入的了解了。


另一个客户端:

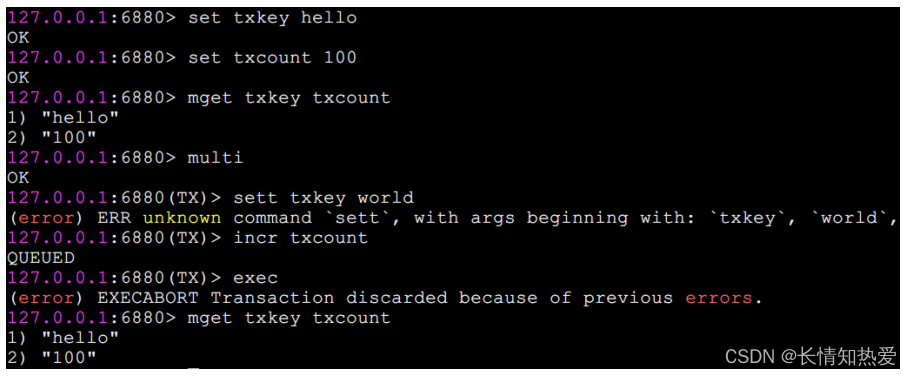
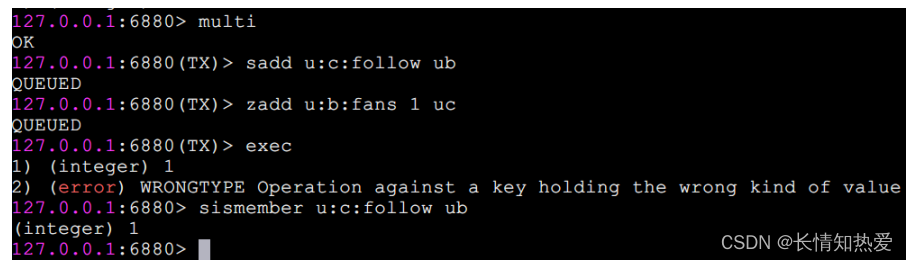
题。
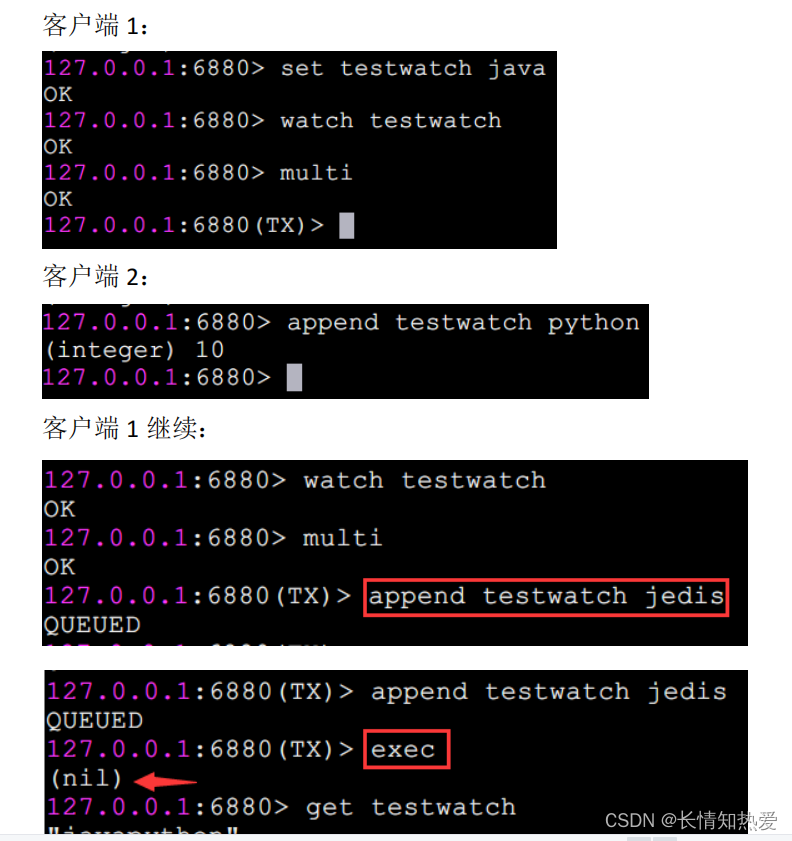
简单来说,
到服务器的;
执行。
力。
Redis 7.0 前瞻
现。
此外也提供了一些安全改进。
为两种情况:
命令传播
Redis 复制缓存区相关问题分析
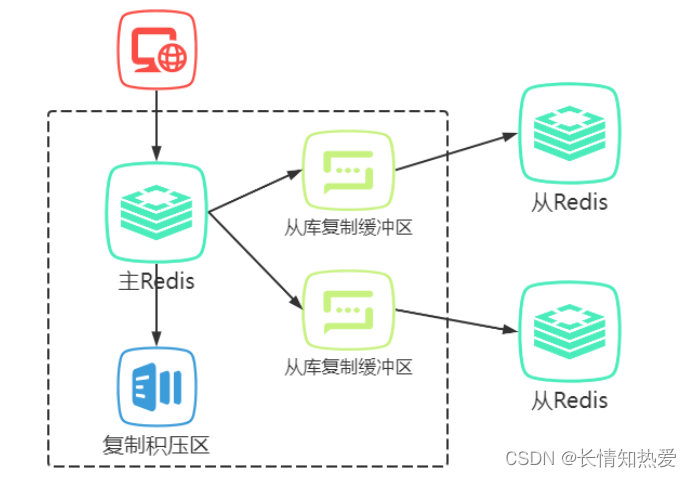
该实现一个明显的问题是内存占用过多,所有从库的连接在主库上是独立的,
实例的内存消耗不可控。
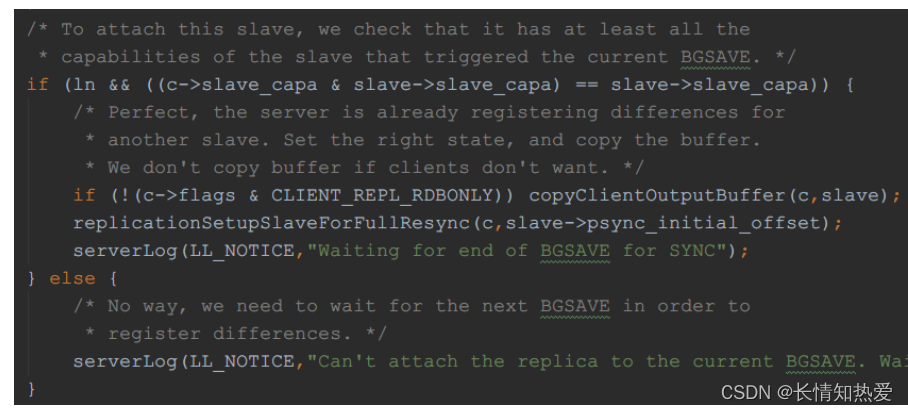
这次 BGSAVE
的
RDB
,为了从库复制数据的完整性,会将之前从库的
的
RDB
,为了从库复制数据的完整性,会将之前从库的
却很大。
接,而在释放
OutputBuffer
时,也需要释放数百
MB
甚至数
GB
的数据,其耗
OutputBuffer
时,也需要释放数百
MB
甚至数
GB
的数据,其耗
时对
Redis
而言也很长。
Redis
而言也很长。
些,这就存在矛盾了。
导致全量同步。
简述
区(
ReplicationBacklog
)中的内容与从库
OutputBuffer
中的数据也是一样的,所
以该方案中,
ReplicationBacklog
和从库一样共享一份复制缓冲区的数据,也避
ReplicationBacklog
)中的内容与从库
OutputBuffer
中的数据也是一样的,所
以该方案中,
ReplicationBacklog
和从库一样共享一份复制缓冲区的数据,也避

堵塞问题和限制问题的解决
多从库消耗内存过多的问题通过共享复制缓存区方案得到了解决,对于
了呢?
首先来看 OutputBuffer
拷贝和释放的堵塞问题问题, 这个问题很好解决,
拷贝和释放的堵塞问题问题, 这个问题很好解决,
值操作,不会有任何阻塞。
减少
refcount
的主要情况有:
refcount
的主要情况有:
数据结构的选择
就是跳表的实现:

没有使用这种数据结构。
Trie 树
销以达到提高效率的目的。
先看一下几个场景问题:
输入的 n 单词中出现过。
2.我们输入 n 个单词,每次查询一个单词的前缀,需要回答出这个前缀是之
前输入的 n 单词中多少个单词的前缀?
因此我们需要更加高效的数据结构,这时候就是
Trie
树的用武之地了。现在
Trie
树的用武之地了。现在
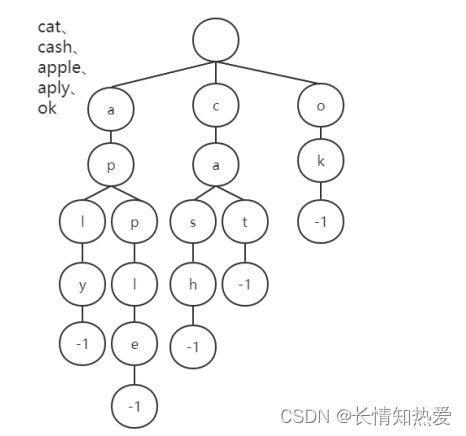
从图中可以看出:
Trie
树其实依然比较浪费空间,比如我们前面所说的“然如果大量字符串没
树其实依然比较浪费空间,比如我们前面所说的“然如果大量字符串没
有共同前缀时”。
Radix
树:压缩后的
Trie
树
树:压缩后的
Trie
树
所以
Radix
树就是压缩后的
Trie
树,因此也叫压缩
Trie
树。比如上面的字符
Radix
树就是压缩后的
Trie
树,因此也叫压缩
Trie
树。比如上面的字符
串列表完全可以这样存储:
串。
dog: 01100100 01101111 01100111
doge: 01100100 01101111 01100111 011
0
0101
0
0101
dogs: 01100100 01101111 01100111 011
1
0011
1
0011
可以发现
dog
和
doge
是在第二十五位的时候不一样的。
dogs
和
doge
是在
dog
和
doge
是在第二十五位的时候不一样的。
dogs
和
doge
是在
存储时可以进一步压缩空间。
原文地址:https://blog.csdn.net/weixin_43874650/article/details/134701773
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_10737.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。







