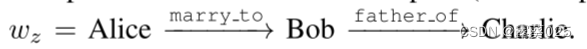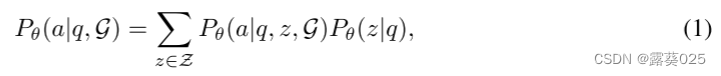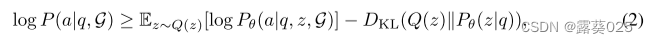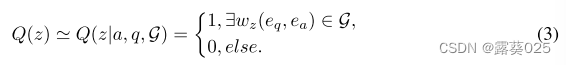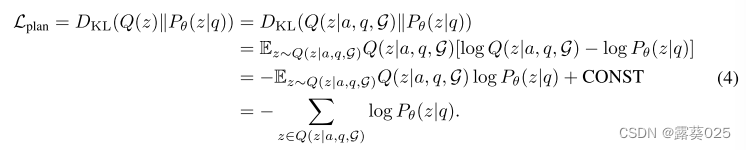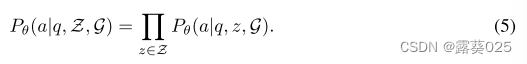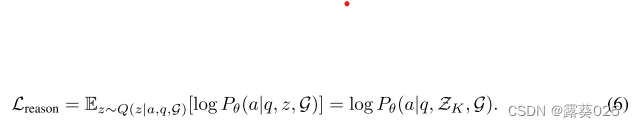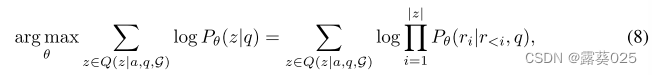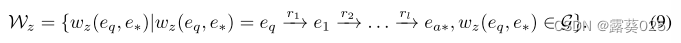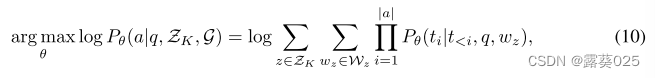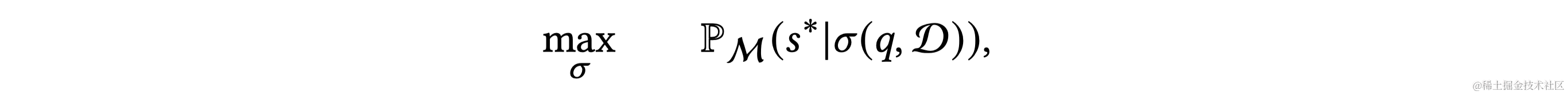摘要
大型语言模型(LLM)在复杂任务中表现出了令人印象深刻的推理能力。然而,他们在推理过程中缺乏最新的知识和经验幻觉,这可能导致错误的推理过程并降低他们的表现和可信度。知识图谱(KG)以结构化格式捕获大量事实,为推理提供了可靠的知识来源。然而,现有的基于KG的LLM推理方法仅将KG视为事实知识库,而忽视了其结构信息对于推理的重要性。在本文中,我们提出了一种称为图推理(Reasoning on Graph 即RoG)的新颖方法,它将 LLM 与 KG 相结合,以实现忠实且可解释的推理。具体来说,我们提出了一个planning–retrieval–reasoning 框架,其中 RoG 首先生成以知识图谱为基础的关系路径作为忠实的计划。然后使用这些计划从 KG 中检索有效的推理路径,供LLM进行忠实的推理。此外,RoG不仅可以从KG中提取知识,通过训练来提高LLM的推理能力,而且还可以在推理过程中与任意LLM无缝集成。对两个基准 KGQA 数据集的大量实验表明,RoG 在 KG 推理任务上实现了最先进的性能,并生成忠实且可解释的推理结果。
1 引言
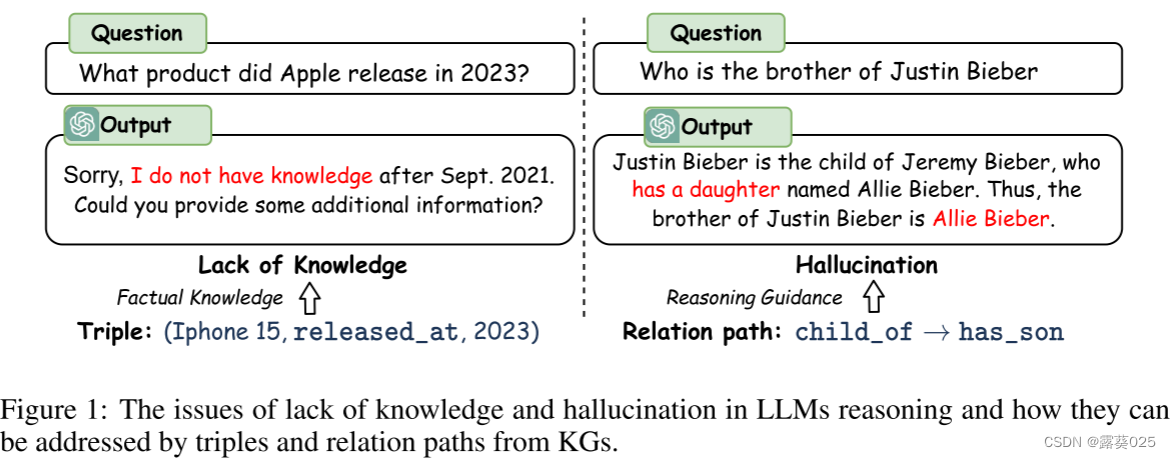
大型语言模型 (LLM) 在许多 NLP 任务中表现出了出色的性能。尤其引人注目的是他们通过推理处理复杂任务的能力。为了进一步释放LLM的推理能力,提出了计划与解决范式,其中提示LLM生成计划并执行每个推理步骤。通过这种方式,LLM将复杂的推理任务分解为一系列子任务并逐步解决。尽管LLM取得了成功,但他们仍然受到知识缺乏的限制,在推理过程中容易出现幻觉,这可能导致推理过程中的错误。例如,如图1所示,LLM没有最新的知识,会产生错误的推理步骤:“有一个女儿”。这些问题很大程度上降低了在高风险场景(例如法律判断和医疗诊断)中的表现和可信度。
为了解决这些问题,人们引入知识图谱(KG)来提高LLM的推理能力。知识图谱以结构化格式捕获丰富的事实知识,为推理提供了可靠的知识源。作为一个典型的推理任务,知识图谱问答(KGQA)旨在根据知识图谱中的知识获取答案。之前联合使用 KG 和 LLM 进行 KGQA 推理的工作大致可分为两类:
1)语义解析方法,该方法使用 LLM 将问题转换为逻辑查询,在 KG 上执行以获得答案;
2)检索增强方法,从 KG 中检索三元组作为知识上下文,并使用 LLM 获得最终答案。
尽管语义解析方法可以通过利用知识图谱推理来生成更准确和可解释的结果,但由于语法和语义的限制,生成的逻辑查询通常是不可执行的并且无法产生答案。检索增强方法更加灵活,可以利用LLM的推理能力。然而,他们只将知识图谱视为事实知识库,而忽视了其结构信息对于推理的重要性。例如,如图 1 所示,关系路径(即关系序列“child of→has son”)可用于获取问题“谁是 Justin Bieber 的兄弟?”的答案。因此,让LLM能够直接在KG上进行推理,以实现忠实且可解释的推理是至关重要的。
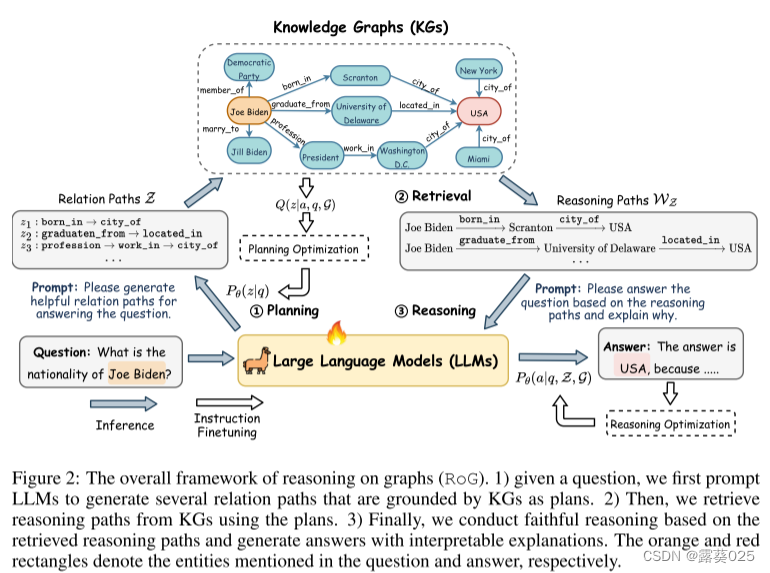
在本文中,我们提出了一种称为图推理(RoG)的新颖方法,该方法将 LLM 与 KG 协同进行忠实且可解释的推理。为了解决幻觉和缺乏知识的问题,我们提出了一个规划-检索-推理框架,其中 RoG 首先通过规划模块生成以 KG 为基础的关系路径作为忠实的计划。然后,这些计划用于从知识图谱中检索有效的推理路径,以通过检索推理模块进行忠实的推理。这样,我们不仅可以从知识图谱中检索最新的知识,还可以考虑知识图谱结构对推理和解释的指导。此外,RoG的规划模块在推理过程中可以与不同的LLM即插即用,以提高其性能。基于这个框架,RoG通过两个任务进行优化:
1)规划优化,我们将知识从KG中提取到LLM中,以生成忠实的关系路径作为规划;
2)检索推理优化,我们使LLM能够基于检索路径进行忠实推理并生成可解释的结果。
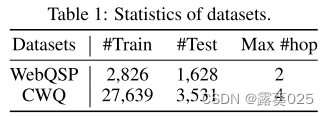
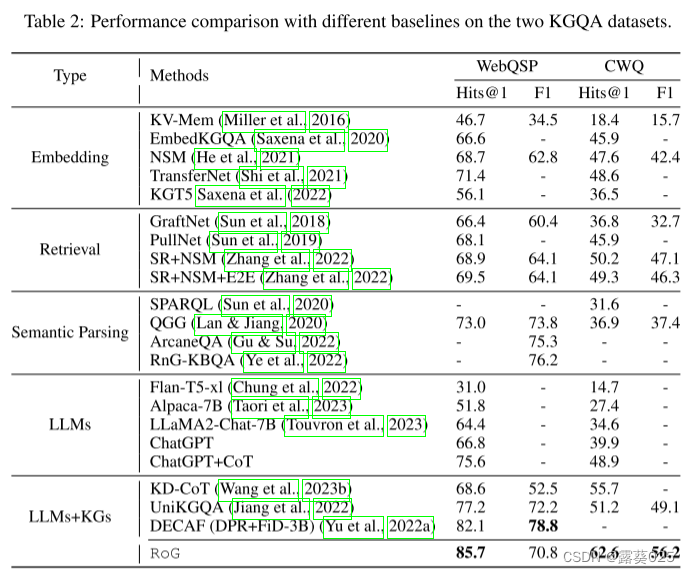
我们在两个基准 KGQA 数据集上进行了广泛的实验,结果表明 RoG 在 KG 推理任务上实现了最先进的性能,并生成了忠实且可解释的推理结果。