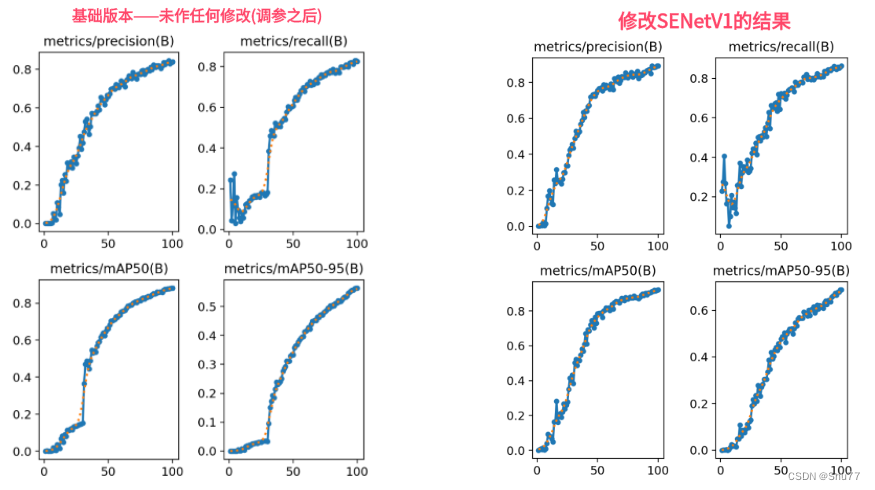
来源
2012年在全球知名的图像识别竞赛 ILSVRC 中,AlexNet 横空出世,直接将错误率降低了近 10 个百分点,这是之前所有机器学习模型无法做到的。
网络结构
AlexNet整体的网络结构包括:1个输入层(input layer)、5个卷积层(C1、C2、C3、C4、C5)、2个全连接层(FC6、FC7)和1个输出层(output layer)。
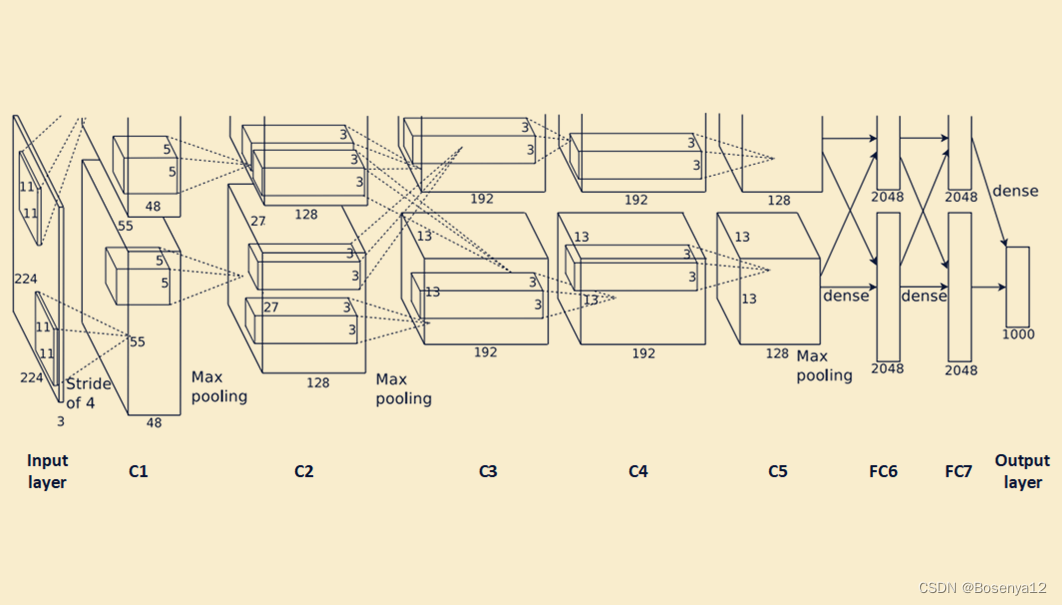
AlexNet整体的网络结构,包含各层参数个数、FLOPS如下图所示:

输入层(input layer)
AlexNet的输入图像尺寸是227x227x3。其中3代表3通道(即RGB),图像的长宽为227*227。
卷积层
处理流程:卷积–>ReLU–>局部响应归一化(LRN)–>池化
局部响应归一化:局部响应归一化层简称LRN,是在深度学习中提高准确度的技术方法。一般是在激活、池化后进行。LRN对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
池化层
使用3x3,stride=2的池化单元进行最大池化操作(max pooling)。注意这里使用的是重叠池化,即stride小于池化单元的边长。
全连接层
处理流程:(卷积)全连接 –>ReLU –>Dropout (卷积)
Dropout:随机的断开全连接层某些神经元的连接,通过不激活某些神经元的方式防止过拟合。
输出层(output layer)
处理流程:(卷积)全连接 –>softmax
将神经元的运算结果通过softmax函数中,输出所有类别对应的预测概率值。
模型特点
- 使用了Relu激活函数
f
(
)
=
(
0
,
)
f(x) = max (0,x)
f(x)=max(0,x)
ReLU是一个非线性函数,使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。
基于ReLU的深度卷积神经网络比基于tanh和sigmoid的网络训练快数倍。 - 标准化——局部响应归一化(LRN)
使用ReLU 后,会发现激活函数之后的值没有了tanh、sigmoid函数那样有一个值域区间,所以一般在ReLU之后会做一个normalization,LRU就是稳重提出一种方法,在神经科学中有个概念叫“Lateral inhibition”,讲的是活跃的神经元对它周边神经元的影响。
局部响应归一化(LRN)对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。 - Dropout
Dropout也是经常说的一个概念,能够比较有效地防止神经网络的过拟合。 相对于一般如线性模型使用正则的方法来防止模型过拟合,而在神经网络中Dropout通过修改神经网络本身结构来实现。对于某一层神经元,通过定义的概率来随机删除一些神经元,同时保持输入层与输出层神经元的个数不变,然后按照神经网络的学习方法进行参数更新,下一次迭代中,重新随机删除一些神经元,直至训练结束。 - 重叠池化
在以前的CNN中普遍使用平均池化层(average pooling),AlexNet全部使用最大池化层 (max pooling)。避免了平均池化层的模糊化的效果,并且步长比池化的核的尺寸小,这样池化层的输出之间有重叠,提升了特征的丰富性。
参考链接
搜狗百科-AlexNet
手撕 CNN 经典网络之 AlexNet(理论篇)
一文读懂LeNet、AlexNet、VGG、GoogleNet、ResNet到底是什么?
原文地址:https://blog.csdn.net/Glass_Gun/article/details/134600997
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_10925.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!