一.前言
上一篇博客对Redis常用的数据结构进行了详细介绍。Redis除了丰富的数据类型支持,还包含许多高级特性,例如事务、内存驻留策略、排序、消息队列等,本文将对这些进行逐一介绍。
二.事务
Redis同样包含事务(transaction)的概念,事务是一组命令的集合,事务中的命令要不全部都执行,要不都不执行。
> MULTI # 事务的开始, 告知Redis下面的命令属于同一个事务, 先不要执行, 而是暂存起来。
"OK"
> DEL cpp
"QUEUED" # 表示命令已经放入等待执行的事务队列中
> DEL program
"QUEUED"
> EXEC # 告知Redis将事务队列中的命令按顺序执行
1) "1"
2) "1"
2.1 错误处理
事务中的命令可能会出错,错误原因主要包含语法错误和运行错误两种,针对两种错误类型,Redis采用了不同的应对策略。
语法错误
语法错误主要指命令不存在或者命令参数不对。下面便展示了一个语法错误的例子,事务中总共添加了两条命令,其中第二条语法出错,执行EXEC后可以看到Redis会直接返回错误,事务中语法正确的命令也不会执行。
> MULTI
"OK"
> SET money 11
"QUEUED"
> GET money 11
"ERR wrong number of arguments for 'get' command"
> EXEC
"EXECABORT Transaction discarded because of previous errors."
运行错误
运行错误指在符合语法但执行过程中出现的错误,该类错误是由程序员造成的。对于该种类型,事务里的错误命令不会导致其他命令无法执行。
下面展示的是一个运行错误的例子,事务的第二天命令错误的对非整数形式的字符串类型应用了自增命令INCR,在执行EXEC后可以看到,第一条命令成功执行,第二条命令返回错误信息。
> MULTI
"OK"
> GET JAPAN
"QUEUED"
> INCR JAPAN
"QUEUED"
> EXEC
1) "Tokyo"
2) "ReplyError: ERR value is not an integer or out of range"
2.2 WATCH命令
WATCH命令可以用来监控一个或多个键,一旦其中有一个键被修改或删除,之后的事务就不会执行,监控一直持续到EXEC命令。
执行EXEC命令后会取消对所有键的监控,若不想执行事务中的命令,也可以使用UNWATCH命令来取消监控。
下面例子中,WATCH命令监控键count之后对其进行了自增操作,之后又进入了一个事务,从结果可以看出,事务并没有执行。
> SET count 1
"OK"
> WATCH count
"OK"
> INCR count
(integer) 2
> MULTI
"OK"
> INCR count
"QUEUED"
> EXEC
(nil)
> GET count
"2"
三.过期时间
Redis可以使用EXPIRE命令设置一个键的过期时间,到期后Redis会自动删除它,该命令具体的形式为:
# seconds表示键过期的时间,单位是秒
EXPIRE key seconds
使用示例如下,这里设置了一个折扣discount的过期时间为10秒,其中TTL命令是用来查看一个键还有多久被删除的,-2表示键已经不存在,对永久存在的键应用TTL命令返回的是-1。
> SET discount 8.5
"OK"
> EXPIRE discount 10
(integer) 1
> TTL discount
(integer) -2
> EXISTS discount
(integer) 0
若想清除键的过期时间设置,可以使用PERSIST命令,若清除成功返回1,否则返回0。
> SET discount 8
"OK"
> EXPIRE discount 20
(integer) 1
> TTL discount
(integer) 17
> PERSIST discount
(integer) 1
> TTL discount
(integer) -1
使用SET或GETSET命令为键赋值同样也会清除键的过期时间。
> GET discount
"8"
> EXPIRE discount 20
(integer) 1
> TTL discount
(integer) 17
> SET discount 7
"OK"
> TTL discount
(integer) -1
四.排序
在Redis中倘若需要数据有序有多种方法,下面将对其进行逐一介绍。
4.1 有序集合
# score和member一一对应, score是排序的依据
ZADD key score member [score member ...]
> ZADD rank 90 xm 88 xh 95 xz 86 xl
(integer) 4
> ZRANGE rank 0 -1
1) "xl"
2) "xh"
3) "xm"
4) "xz"
4.2 SORT命令
SORT命令可以对列表类型、集合类型和有序集合类型键进行排序。
SORT命令的时间复杂度为
O
(
n
+
m
(
m
)
)
O(n+mlog(m)),其中n表示待排序的列表/集合中的元素个数,m表示要返回元素的个数。
> LPUSH scores 87 77 90 68 100
(integer) 5
> SORT scores
1) "68"
2) "77"
3) "87"
4) "90"
5) "100"
> SORT scores DESC
1) "100"
2) "90"
3) "87"
4) "77"
5) "68"
SORT命令还可以通过ALPHA参数实现按字典序排列非数字元素。
> LPUSH namelist tom james shelly sala andy
(integer) 5
> LRANGE namelist 0 -1
1) "andy"
2) "sala"
3) "shelly"
4) "james"
5) "tom"
> SORT namelist ALPHA
1) "andy"
2) "james"
3) "sala"
4) "shelly"
5) "tom"
SORT与SQL一样也支持使用LIMIT offset count来指定跳过前offset个元素并获取之后的count个元素。
> SORT scores DESC LIMIT 0 3
1) "100"
2) "90"
3) "87"
> SORT scores DESC STORE sorted_scores
(integer) 5
> LRANGE sorted_scores 0 -1
1) "100"
2) "90"
3) "87"
4) "77"
5) "68"
SORT还可以通过BY参数来指定排序的模式,其语法形式为BY 参考键,参考键可以是字符串类型键或哈希类型键的某个字段(键名->字段名)。
> LPUSH students student:1 student:2 student:3 student:4
(integer) 4
> HMSET student:1 age 18 name Tom
"OK"
> HMSET student:2 age 17 name Shelly
"OK"
> HMSET student:3 age 20 name Andy
"OK"
> HMSET student:4 age 18 name Jack
"OK"
# 按年龄排序
> SORT students BY *->age
1) "student:2"
2) "student:1"
3) "student:4"
4) "student:3"
# 按名字排序
> SORT students BY *->name ALPHA
1) "student:3"
2) "student:4"
3) "student:2"
4) "student:1"
SROT还包含GET参数,该参数不影响排序,它的作用是使SORT命令的返回结果不再是元素自身的值,而是GET参数中指定的键值。
# 根据年龄排序,并返回学生名字
> SORT students BY *->age GET *->name
1) "Shelly"
2) "Tom"
3) "Jack"
4) "Andy"
五.消息通知
通知可以借助任务队列实现,任务队列就是传递任务的队列,与任务队列交互的实体有生产者(将需要处理的任务放入任务队列)和消费者(不从任务队列中读取任务消息并执行)。
使用任务队列有如下好处:
5.1 基于列表的队列
可以列表可以实现队列,即让生产者在一边使用LPUSH命令将任务加入到列表中,然后让消费者在另一边使用RPOP不断从里列表中取出任务执行。但采用RPOP有一点不完美之处,当任务队列中没有任务时,需要不断调用RPOP去检查,而使用BRPOP命令则不会有这个问题,当列表中没有元素时,BRPOP命令会不断阻塞,直到有新元素加入。
BRPOP命令接受两个参数,第一个是键名,第二个是超时时间,单位为秒,当到达设定的超时时间还没有新元素时,则返回nil。该命令会返回两个值,分别是键名和元素值。
> LPUSH message m1 m2 m3
(integer) 3
> BRPOP message 1
1) "message"
2) "m1"
BRPOP可以同时接收多个键,其语法形式为BRPOP key [key ...] timeout,若所有键都没有元素则阻塞,否则会按顺序弹出第一个非空列表中的元素。
> LPUSH message1 m1 m2 m3
(integer) 3
> LPUSH message2 m4
(integer) 1
> BRPOP message1 message2 1
1) "message1"
2) "m1"
> BRPOP message1 message2 1
1) "message1"
2) "m2"
> BRPOP message1 message2 1
1) "message1"
2) "m3"
> BRPOP message1 message2 1
1) "message2"
2) "m4"
> BRPOP message1 message2 1
(nil)
5.2 发布订阅模式
Redis还提供了一组命令可以实现发布订阅模式,该模式中包含两种角色,发布者和订阅者,订阅者可以订阅一个或多个频道(channel),发布者可以想指定频道发送消息,只有订阅该频道的订阅者才能收到相关的消息。
发布者发布消息的命令为PUBLISH channel message,其返回值为接收到这条消息的订阅者的数量。订阅频道的命令为SUBSCRIBE channel [channel ...],从语法可以看出可以订阅多个频道。
# 客户端1
# 订阅频道, 等待和接收消息
> SUBSCRIBE mchannel
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "mchannel"
3) (integer) 1
1) "message"
2) "mchannel"
3) "hello world"
# 客户端2
# 往频道发布消息
> PUBLISH mchannel "hello world"
(integer) 1
从上面可以看到,客户端可以收到3种类型的回复,每种类型的回复都包含3个值,第一个是消息的类型,第二、三个视消息类型而不同。
消息类型包括:
subscribe:表示订阅成功的反馈信息。第二个值为订阅的频道名,第三个值为当前客户端订阅的频道数量。message:表示接收到的消息,第二个值为产生消息的频道名,第三个值为消息的内容。unscribe:表示成功取消订阅某个频道,第二个为要取消的频道名,第三个是当前客户端订阅的频道数量。
通过UNSUBSCRIBE channel [channel ...]可以取消订阅的频道。
5.3 强大的流
Redis 5.0引入了全新的流类型,流类型除了能高效存储日志结构的数据,还可以作为消息中间件。作为消息中间件时,其与上述介绍的列表、发布/订阅模式的对比如下表所示:

由上图可见,流同时具备列表和发布/订阅模式的所有优点。
流的基本用法
流类型具备日志的特征,一是仅在末尾追加,二是每一条记录都包含了多个结构化的信息。
流在插入新条目时会为其自动生成一个在流中唯一的ID,这个ID可以用来进行查询操作。
往流中增加条目的命令为:
XADD key [MAXLEN [=|~] threshold] *|ID field value [field value ...]
其中:
[MAXLEN [=|~] threshold]用来指定流最多保持指定数量的条目,~表示近似裁剪,即非精确地保持thresold条,而是可以稍微多一点,这样可以提升性能。*|ID用来指定条目的ID,其中*的含义是让Redis按规则自动生成,也可以由用户主动指定ID。field value [field value ...]表示若干字段及其对应的字段值。
添加条目的示例如下:
> XADD logs MAXLEN ~ 20 * IP 172.146.5.3 status 200
"1699929848274-0"
> XADD logs MAXLEN ~ 20 * IP 172.146.5.6 status 304
"1699930100371-0"
由上示例可知ID的格式为<millisecondsTime>-<sequenceNumber>,其中前半部分为Redis服务器的时间戳,后半部分为序列号。
流的查询可以使用如下命令,其中start和end表示条目的ID,查询时ID中的序列号部分可以省略,通过这种方式,可以查询指定范围内的条目列表。COUNT可以用来限制返回结果的条数。
XRANGE key start end [COUNT count]
此外,xRANGE还支持两个特殊的ID,即-和+,分别表示最小ID和最大ID,通过这两个特殊ID可以获取流中所有的条目。
> XRANGE logs - +
1) 1) "1699929848274-0"
2) 1) "IP"
2) "172.146.5.3"
3) "status"
4) "200"
2) 1) "1699930100371-0"
2) 1) "IP"
2) "172.146.5.6"
3) "status"
4) "304"
流对消息中间件的支持
流提供了高效查询消息历史的命令,并可以自定义从哪个ID开始读。具体通过XREAD命令实现。
XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...]
其中count表示读取的条目数,BLOCK表示阻塞多久,单位是毫秒,STREAMS参数后是要读取键名,以及从哪个ID开始读。
命令示例为:
> XREAD COUNT 1 STREAMS logs 1699929848274-0
1) 1) "logs"
2) 1) 1) "1699930100371-0"
2) 1) "IP"
2) "172.146.5.6"
3) "status"
4) "304"
由上可知,XREAD返回数据是一个列表,最外层列表中每个元素对应XREAD命令请求的键名,接下来每个结果中包含条目ID和条目中所有的键值对。
5.4 流与消费组
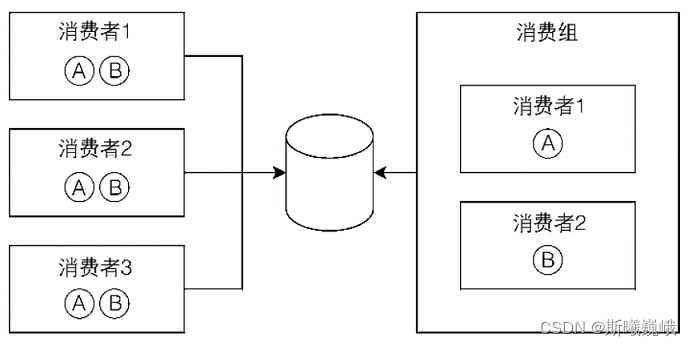
消费组中包含若干消费者,消费组在对外接收消息时可以视为一个整体,当消费组接收一条消息时,会将该消息分发给组内的其中一个消费者,即同一条消息不会发给组内的多个消费者。例如下图中包含5个消费者,其中有2个消费者处于同一个消费组中,故它们各自只收到了一条消息,而其他的消费者能收到所有的消息。
创建消费者组的命令为:
XGROUP [CREATE key groupname] ID|$ [MKSTREAM]
其中MKSTREAM参数用来说明若指定的流不存在,则会创建一个流,若不指明该参数的话,流不存在会返回一个错误。符号$用来说明当前消费组的ID,其表示最后一个条目,也可以指定具体的ID。
消费组的创建示例为:
> XGROUP CREATE mystream mygroup $ MKSTREAM
OK
消费者组消费消息的命令为XREADGROUP,该命令与XREAD的定义类似,具体语法为:
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] id [id ...]
往流mystream中添加消息,两个属于同一个消费组mygroup的消费者消费流中消息的示例为:
# 往消费组添加消息
> XADD mystream * message A
"1700632675587-0"
> XADD mystream * message B
"1700632678571-0"
# 客户端
> XREADGROUP GROUP mygroup consumer1 COUNT 1 STREAMS mystream >
1) 1) "mystream"
2) 1) 1) "1700632675587-0"
2) 1) "message"
2) "A"
# 客户端2
> XREADGROUP GROUP mygroup consumer2 COUNT 1 STREAMS mystream >
1) 1) "mystream"
2) 1) 1) "1700632678571-0"
2) 1) "message"
2) "B"
上述命令中末尾的>表示还没有分发的消息ID,消费组读取要提供ID是为了进行消息确认。消费者组内消费者读取每个条目并正确处理后,都必须通过XACK命令告诉消费者组处理成功,否则该条目会被加入该消费者的等待队列,直接到接收到XACK命令,或用XCLAIM命令将这条消息转移给组内的其他消费者重新处理。
XACK命令语法形式为:
XACK key group ID [ID ...]
其中key表示流,group表示消费者组,ID表示消费消息的ID。
消费者2确认处理成功的示例如下:
> XACK mystream mygroup 1700632678571-0
(integer) 1
消费者组内维护了每个消费者的等待队列,可以通过XPENDING命令查看:
XPENDING key group
使用示例为:
> XACK mystream mygroup 1700632678571-0
(integer) 1
> XPENDING mystream mygroup
1) (integer) 1
2) "1700632675587-0"
3) "1700632675587-0"
4) 1) 1) "consumer1"
2) "1"
上述返回结果中第一行表示,mygroup消费者组内所有消费者的等待队列中包含的条目数,接下来两行表示条目的最大和最小ID,紧接着是有等待条目的消费者名称和相应队列的条目数量。
六.结语
参考资料:
以上便是文本的全部内容,若有任何错误敬请批评指正,要是觉得不错可以点赞或关注一下,后续会持续更新。
原文地址:https://blog.csdn.net/qq_42103091/article/details/134552567
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_10995.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!