本文介绍: 已解决(pd.read_xml函数读取xml文件报错)ImportError: Missing optional dependency ‘fsspec’. Use pip or conda to install fsspec.
已解决(pd.read_xml函数读取xml文件报错)ImportError: Missing optional dependency ‘fsspec’. Use pip or conda to install fsspec.
报错代码
粉丝群里面的一个小伙伴想用pandas读取xml文件,但是发生了报错(当时他心里瞬间凉了一大截,跑来找我求助,然后顺利帮助他解决了,顺便记录一下希望可以帮助到更多遇到这个bug不会解决的小伙伴),报错代码如下::
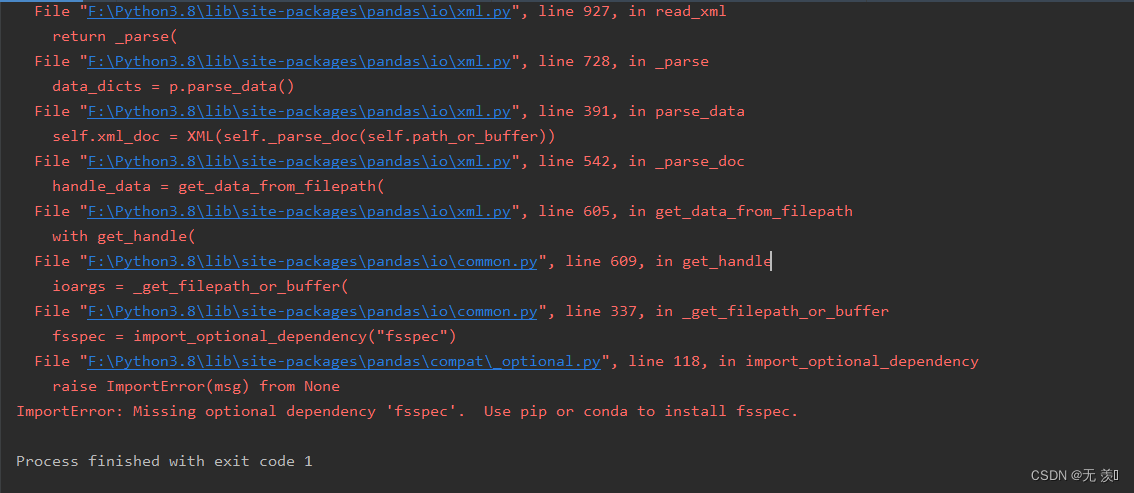
报错翻译
报错原因
解决方法
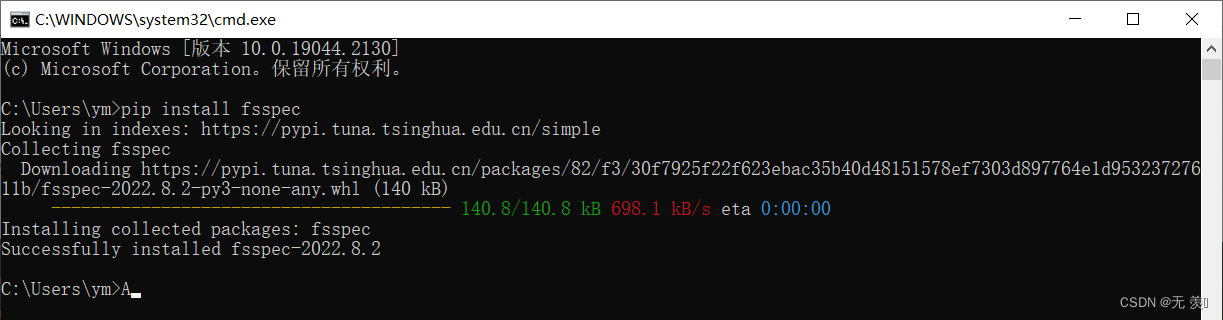
千人全栈VIP答疑群联系博主帮忙解决报错

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。