二叉查找树
二叉树具有以下性质:左子树的键值小于根的键值,右子树的键值大于根的键值。
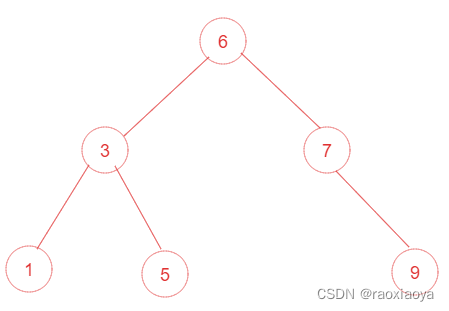
对该二叉树的节点进行查找发现深度为1的节点的查找次数为1,深度为2的查找次数为2,深度为n的节点的查找次数为n,因此其平均查找次数为 (1+2+2+3+3+3) / 6 = 2.3次。
平衡二叉树AVLT
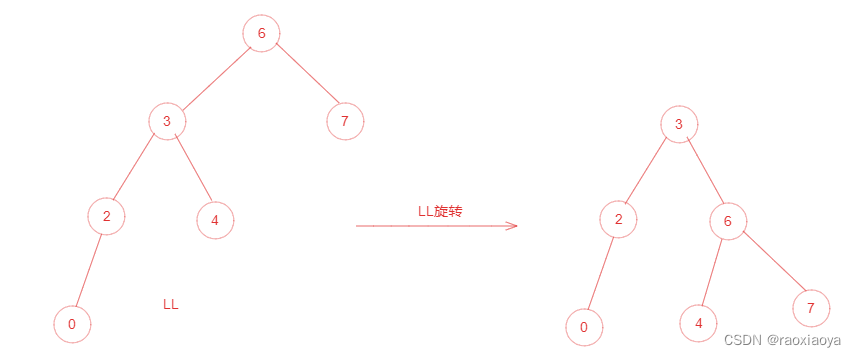
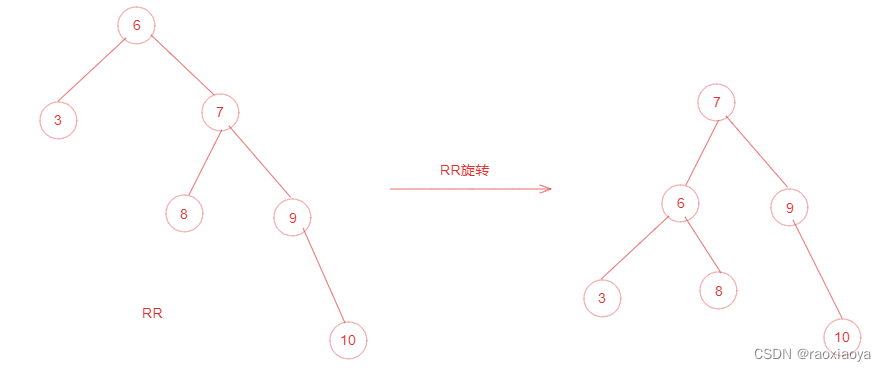
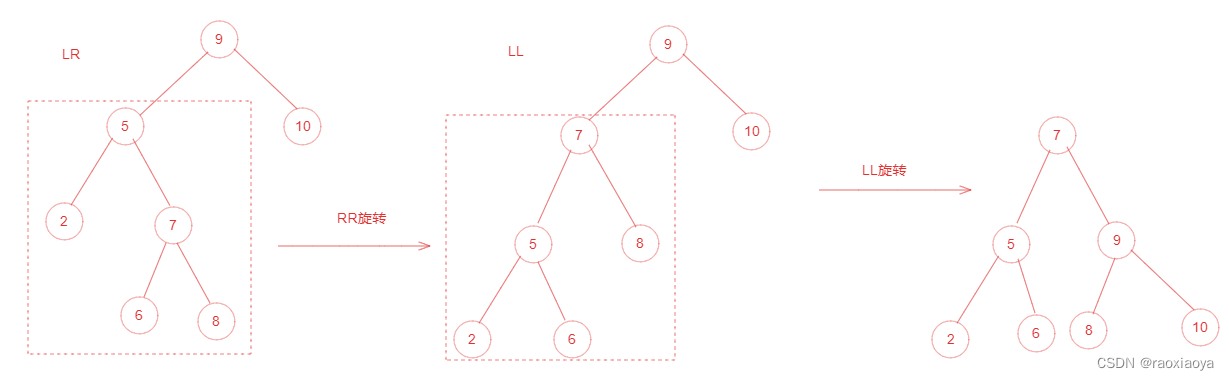
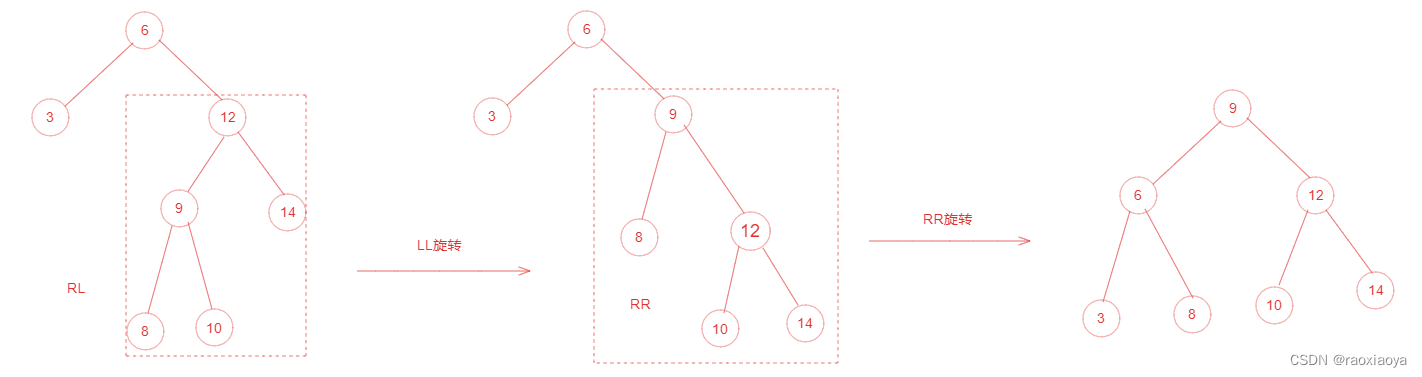
为了提高二叉树的查找效率,显然二叉树层级越少越好,于是就有了平衡二叉树。它在符合二叉查找树的条件下,还满足任何节点的两个子树的高度最大差为1,如下图所示:
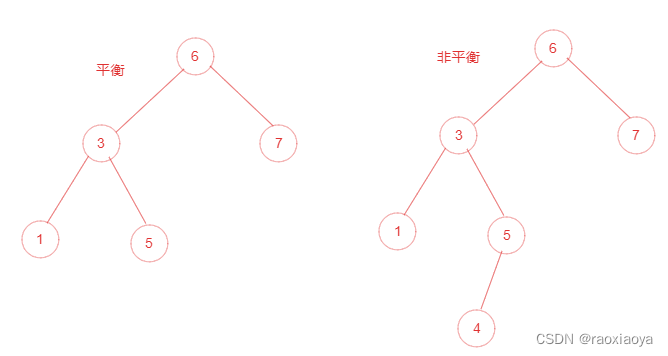
AVL二叉树的高度为:

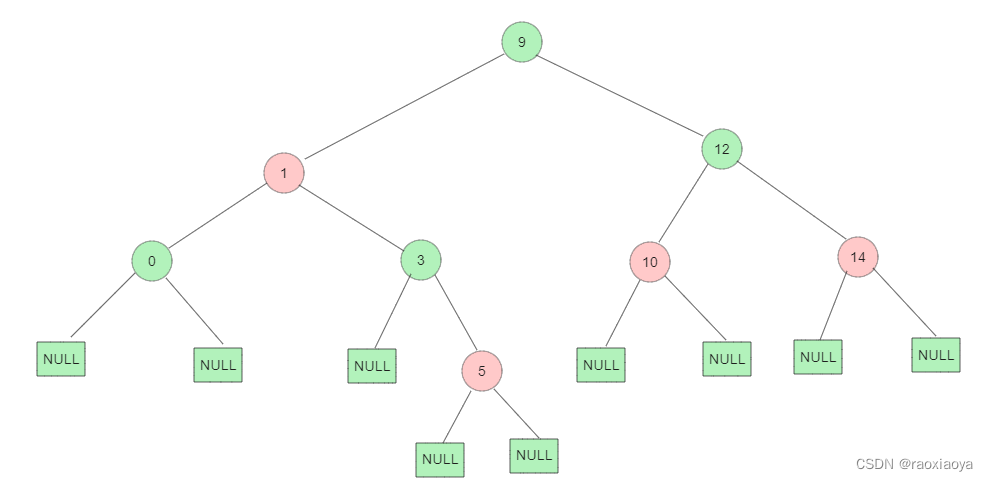
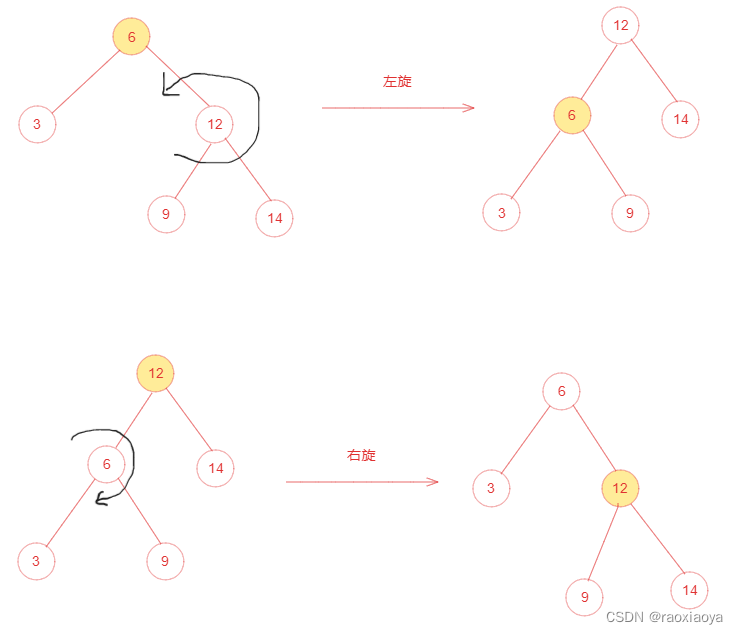
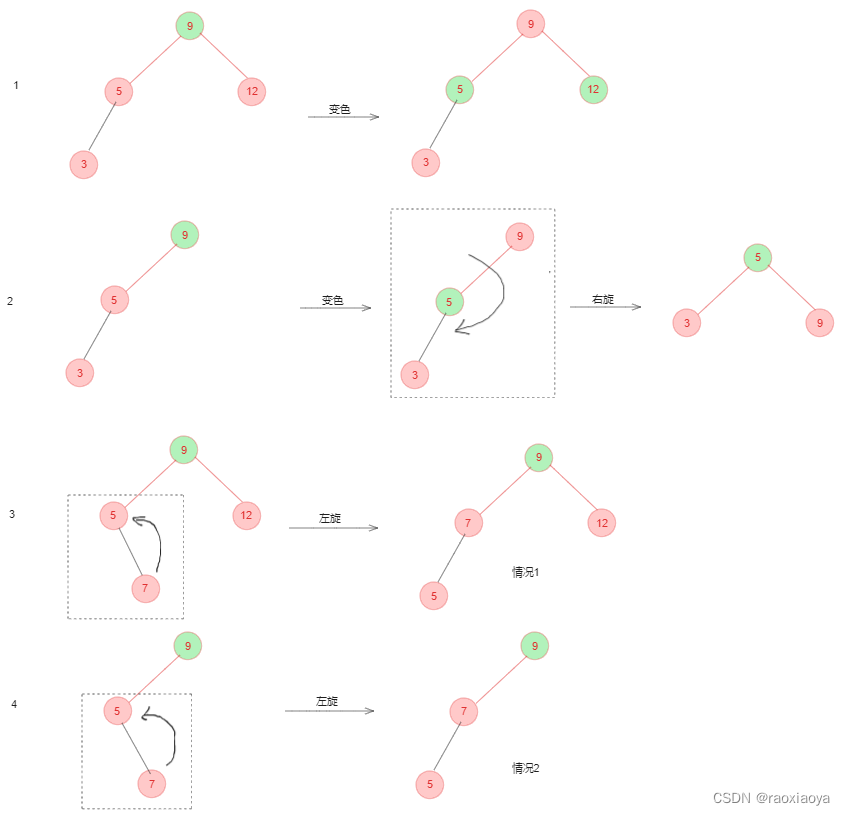
红黑树 RBT
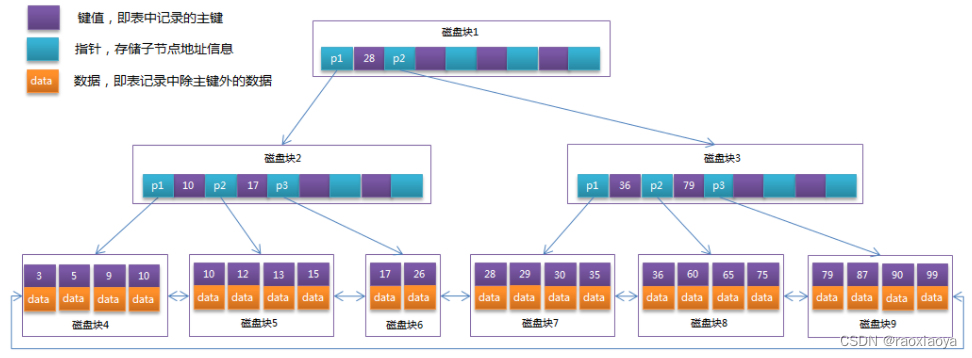
平衡多路查找数B-Tree
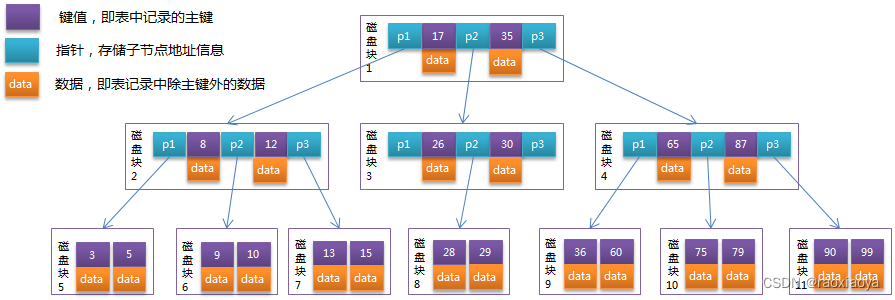
B+Tree
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。