本文介绍: No One Idles: Efficient Heterogeneous Federated Learning with Parallel Edge and Server Computation
一、概要
随着联邦学习的发展,简单的聚合算法已经不在有效。但复杂的聚合算法使得联邦学习训练时间出现新的瓶颈。本文提出了并行联邦学习(parallel federated learning,PFL),通过调换中心节点聚合和广播的顺序。本文算法的优点:在全局聚合计算时解锁了边缘节点,在边缘节点本地计算时解锁了中心节点,并且在计算过程中具有灵活的伸缩性。
本文主要贡献:
二、关键算法
本文的PFL算法并没有重新设计FL框架,仅仅只是将原计算流程进行了适当的调整,主要包含同步的SPFL和异步的APFL。如图所示,(a)表示FedAvg流程:uploading–>global aggregation–>broadcasting–>local optimization。(b)表示本文提出的SPFL流程:uploading(中心节点接收当前所有边缘局部更新)–>broadcasting(中心节点广播缓存中的全局模型参数)–>全局聚合计算(中心节点利用接收到的局部更新聚合全局模型参数)。该设计可以使得本地一旦优化完成便上传到中心节点,而中心节点一旦接收到本地更新边广播缓存中的全局模型参数。因此边缘节点和中心节点不用等待阻塞。
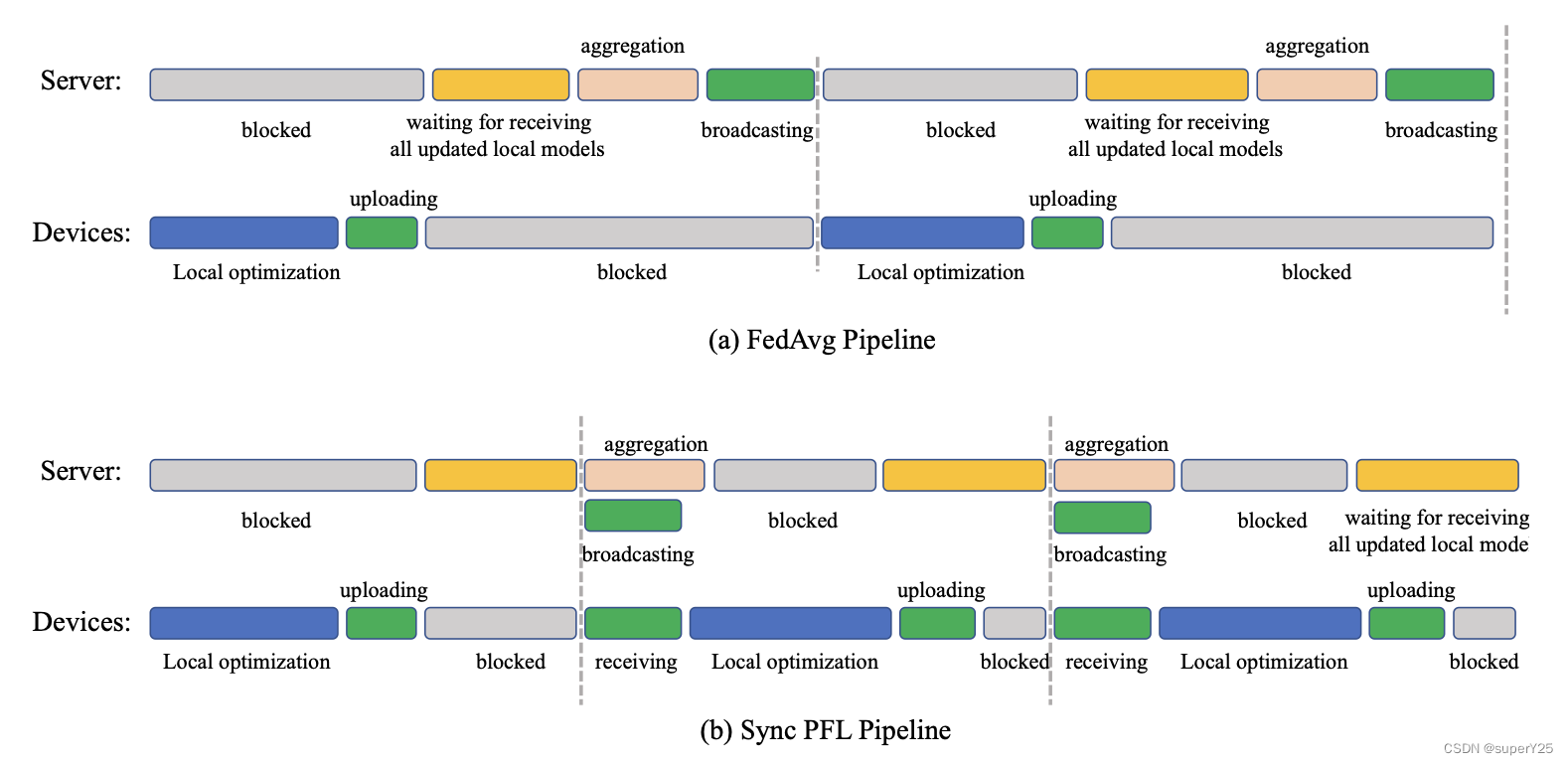
下图是APFL的流程图:

SPFL
同步的PFL并不能处理网络掉队的问题,而是对复杂聚合逻辑做了相应的处理。其流程中对应的处理逻辑分别如下:
APFL
异步的PFL同时对边缘节点的网络掉队问题和中心节点的复杂聚合算法逻辑做了优化。每个边缘节点和中心节点都有不同的clocks,并且中心节点的clock只和其中一个边缘节点有关,例如对于第
t
t
SPFL和APFL的异同

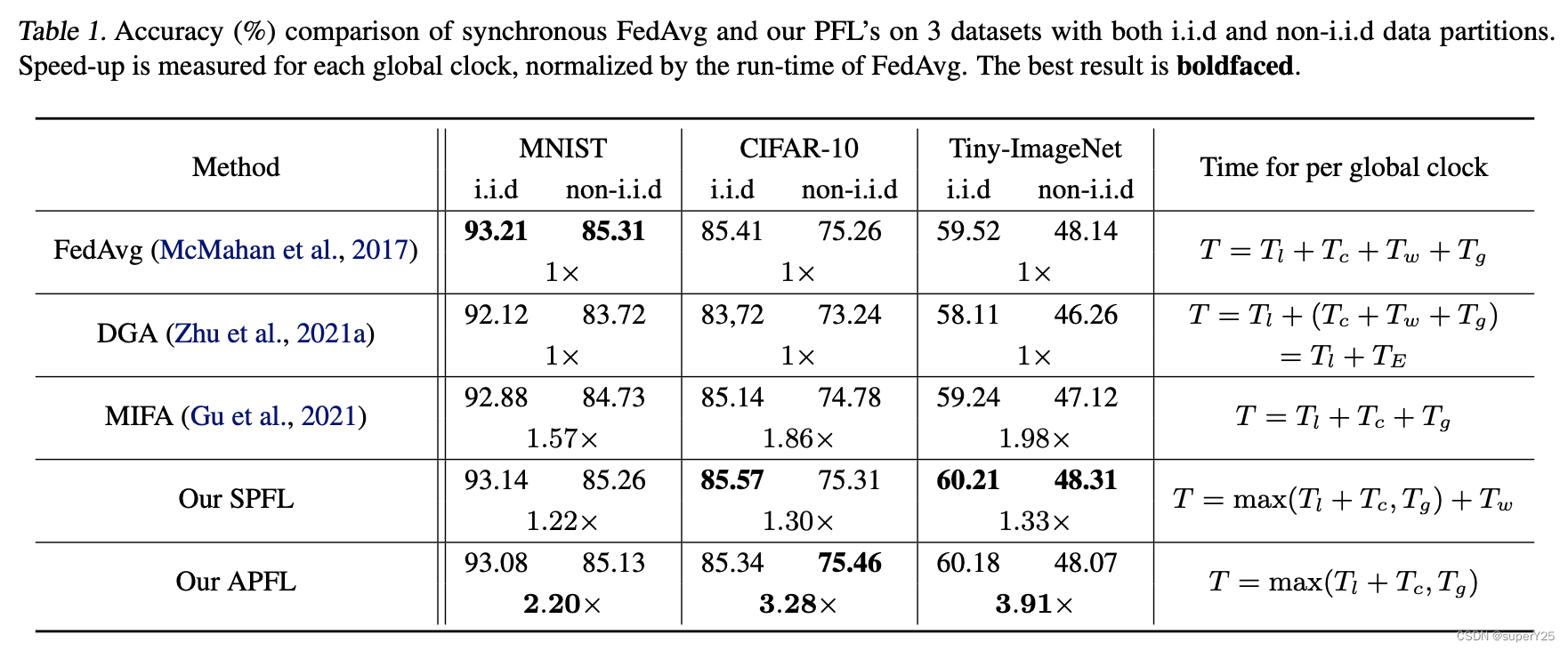
三、总结

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。





