近年来,数据分析和可视化已经成为了许多领域中的重要工具。在教育领域中,通过对学生的表现和行为进行数据分析和可视化,可以更好地了解学生的学习状态,发现问题、改进教学,并提高学生成绩。本文将介绍一个 Python 综合案例,使用 Pandas 和 Seaborn 库,对学生的数据进行清洗、预处理和可视化分析,探究学生表现与学习行为之间的关系。通过这个案例,我们可以深入了解 Python 在数据分析和可视化方面的应用,同时也为教育数据分析提供了一种新的思路和方法。
一、获取数据
要读取StudentPerformance.csv文件,可以使用Python中的pandas库。首先需要安装pandas库,可以使用以下命令进行安装:
pip install pandas
安装完成后,可以使用以下代码读取StudentPerformance.csv文件:
import pandas as pd
df = pd.read_csv('StudentPerformance.csv')
print(df.head())
其中,pd.read_csv('StudentPerformance.csv')读取csv文件,并返回一个pandas的DataFrame对象。df.head()输出DataFrame的前5行数据。
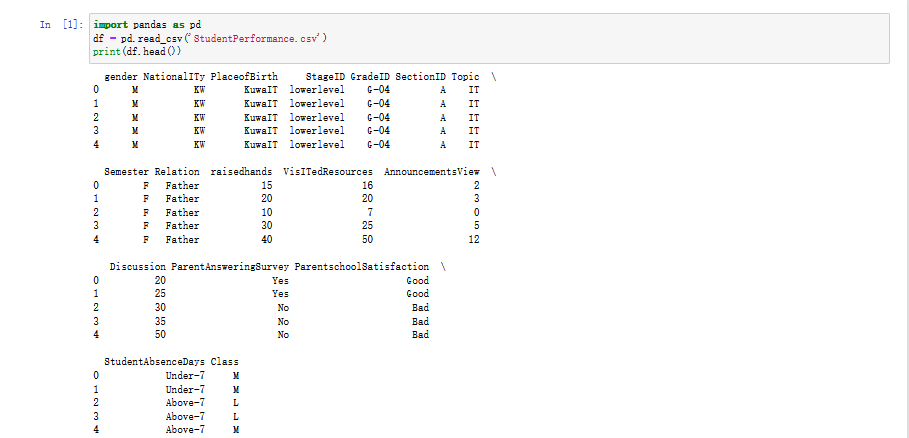
二、修改表列名,请将表列名修改为中文。
要将表列名修改为中文,可以使用pandas库中的rename()函数。
将表列名修改为中文:
import pandas as pd
df = pd.read_csv('StudentPerformance.csv')
# 新列名列表
new_columns = ['性别', '民族', '出生地', '学段', '年级', '班级', '主题', '学期', '与家长关系', '举手次数', '上课用品查看次数', '公告查看次数', '参与讨论次数', '家长是否回答调查问卷', '家长对学校满意度', '学生缺勤天数', '班级']
# 将原列名与新列名对应起来,组成字典
rename_dict = dict(zip(df.columns, new_columns))
# 使用rename()函数修改列名
df.rename(columns=rename_dict, inplace=True)
print(df.head())
其中,new_columns列表中存放的便是新的中文列名,可以根据需求自行修改。然后通过zip()函数将原来的列名和新的中文列名一一对应,最后通过rename()函数修改列名。
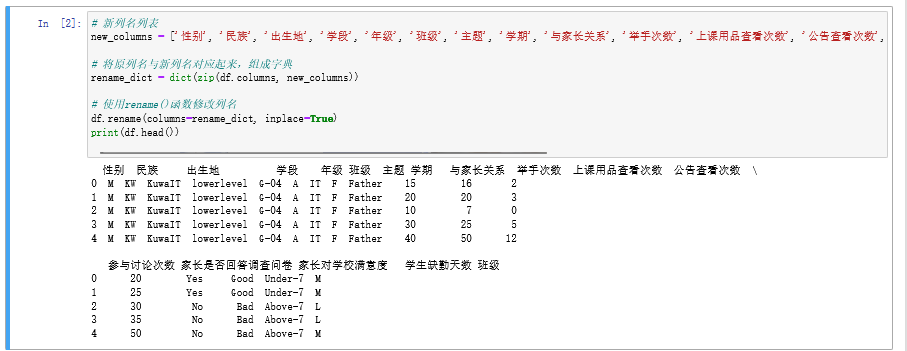
三、显示学期和学段的取值
# 显示学期和学段的取值
print('学期取值:', df['学期'].unique())
print('学段取值:', df['学段'].unique())
四、 修改数据
将lowerlevel,middleschool,highschool修改成中文,将”性别“中M,F,修改成中文,将”学期“中S,F,修改成春季,秋季
要将lowerlevel、middleschool和highschool修改为中文,需要使用replace()方法将这三个值替换为小学、初中和高中。同样的,可以使用replace()方法将M和F替换为男和女。还可以使用相同的方法将S和F替换为春季和秋季。以下是示例代码:
import pandas as pd
df = pd.read_csv('StudentPerformance.csv')
# 修改学段数据
df.loc[:, 'StageID'] = df['StageID'].replace({'lowerlevel': '小学', 'middleschool': '初中', 'highschool': '高中'})
# 修改性别数据
df.loc[:, 'gender'] = df['gender'].replace({'M': '男', 'F': '女'})
# 修改学期数据
df.loc[:, 'Semester'] = df['Semester'].replace({'S': '春季', 'F': '秋季'})
print(df.head())
在这里,我们使用loc[]来选择整列数据并且使用replace()方法进行相应的修改。最后输出修改后的DataFrame数据,即可看到StageID列中lowerlevel、middleschool和highschool被替换为小学、初中和高中,gender列中M和F被替换为男和女,semester列中S和F被替换为春季和秋季。
五、查看空缺数据情况。
要查看DataFrame中的空缺数据情况,可以使用isnull()方法来检查每个单元格是否为空。这将返回一个布尔值的DataFrame,其中值为True表示该单元格为空,否则为False。我们可以使用sum()方法计算每列中有多少个空缺值。以下是示例代码:
df.isnull().sum()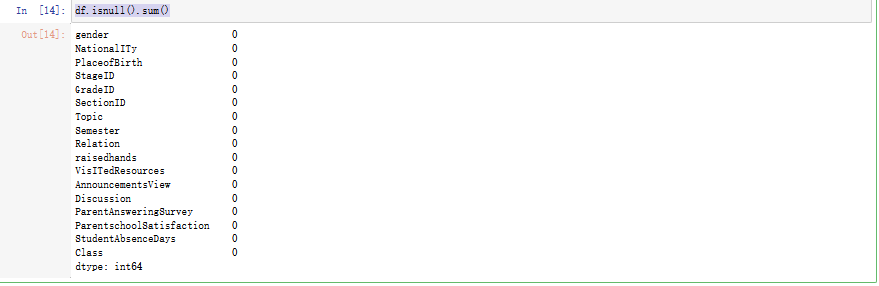
六、按成绩绘制计数柱状图
在这里,我们使用plt.rcParams['font.sans-serif']函数将SimHei作为全局字体,用于替换默认字体。然后使用plt.xlabel()和plt.ylabel()函数添加x轴和y轴的标签,使用plt.title()函数添加图表的标题,最后使用plt.show()函数显示图表。
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('StudentPerformance.csv')
scores = df['TotalScore']
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.hist(scores, bins=10)
plt.xlabel('Total Score')
plt.ylabel('Number')
plt.title('Distribution of Student Scores')
plt.show()
执行以上代码,即可得到按成绩绘制的计数柱状图,其中汉字已替换为英文。
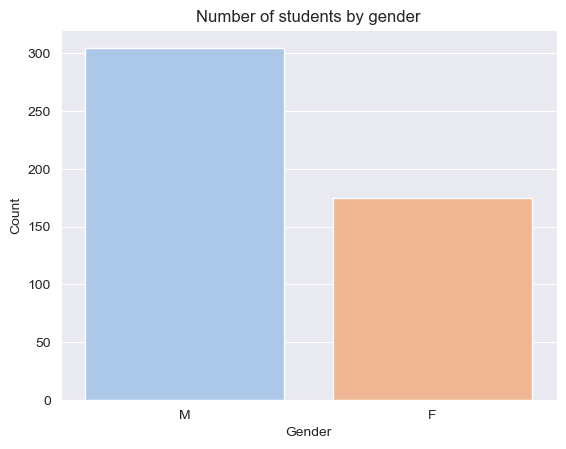
七、按性别绘制计数柱状图
以下是绘制计数柱状图的代码,使用文件名StudentPerformance.csv并按性别分组:
# 绘制计数柱状图
sns.countplot(data=df, x='gender')
plt.xlabel('Gender')
plt.ylabel('Count')
plt.title('Number of students by gender')
# 展示图形
plt.show()
在上面的代码中,我们使用了Seaborn库的countplot()函数来绘制计数柱状图,并将x参数设置为gender以按性别对学生进行分组。我们还添加了标签和标题,以使图形更加易于理解。
注意,你需要确保数据集文件StudentPerformance.csv位于当前工作目录中,或者指定正确的文件路径。
八、按科目绘制计数柱状图
以使用Seaborn的countplot()函数来绘制按科目分组的计数柱状图。以下是一个示例代码:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 读取数据集
df = pd.read_csv('StudentPerformance.csv')
# 绘制计数柱状图
sns.countplot(data=df, x='Topic')
plt.xlabel('Subject')
plt.ylabel('Count')
plt.title('Number of students by subject')
# 展示图形
plt.show()
在上面的代码中,我们使用了Seaborn库的countplot()函数来绘制计数柱状图,并将x参数设置为以按科目对学生进行分组。我们还添加了标签和标题,以使图形更加易于理解。
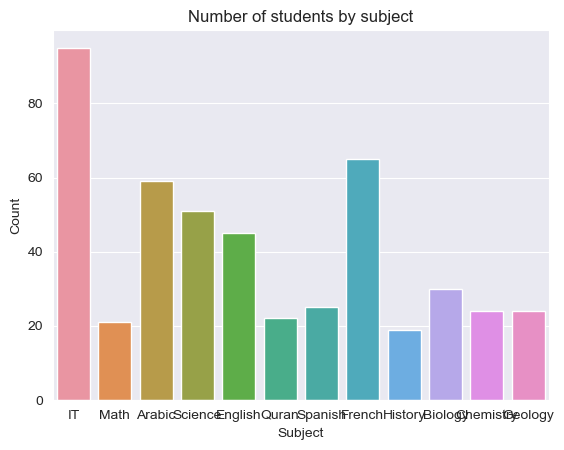
当然,我们可以
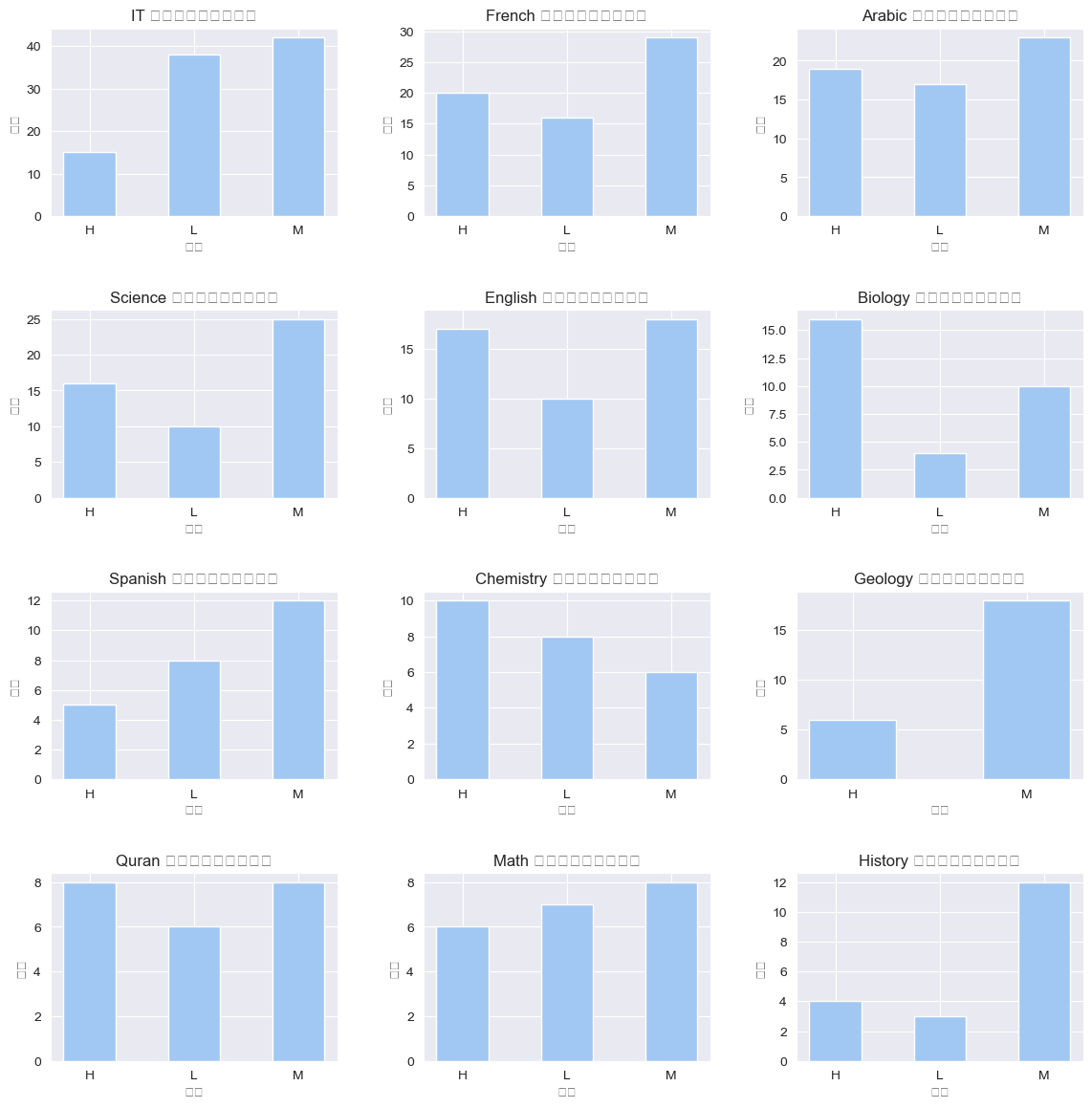
九、按科目绘制不同成绩的计数柱状图
import pandas as pd
import matplotlib.pyplot as plt
# 读取数据集
df = pd.read_csv('StudentPerformance.csv')
# 选择需要的列和科目
cols = ['Topic', 'Class']
topic_cols = df[cols]
# 将不同成绩分组并统计数量
counts_df = topic_cols.groupby(['Topic', 'Class']).size().reset_index(name='counts')
# 创建一个包含 4 行 3 列子图的数组
fig, axes = plt.subplots(nrows=4, ncols=3, figsize=(12, 12))
# 创建一个包含所有科目的列表
subjects = ['IT', 'French', 'Arabic', 'Science', 'English', 'Biology', 'Spanish', 'Chemistry', 'Geology', 'Quran', 'Math', 'History']
# 在每个子图中绘制对应的计数柱状图
for i, subject in enumerate(subjects):
# 获取当前科目的数据
subject_df = counts_df[counts_df['Topic'] == subject]
# 计算子图的行和列索引
row_index = i // 3
col_index = i % 3
# 在当前子图中绘制计数柱状图
axes[row_index, col_index].bar(subject_df['Class'], subject_df['counts'], width=0.5)
axes[row_index, col_index].set_xlabel('class')
axes[row_index, col_index].set_ylabel('count')
axes[row_index, col_index].set_title(f'{subject} 不同成绩的人数分布')
# 调整子图之间的距离和外边距
plt.subplots_adjust(wspace=0.3, hspace=0.5, top=0.95, bottom=0.05, left=0.05, right=0.95)
# 显示图像
plt.show()
十、按性别和成绩绘制计数柱状图
使用Seaborn的countplot()函数来绘制按性别和成绩分组的计数柱状图。以下是一个示例代码:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 读取数据集
df = pd.read_csv('StudentPerformance.csv')
# 绘制计数柱状图
sns.countplot(data=df, x='gender', hue='grade')
plt.xlabel('Gender')
plt.ylabel('Count')
plt.title('Number of students by gender and grade')
# 设置图例位置
plt.legend(loc='upper right')
# 展示图形
plt.show()
在上面的代码中,我们使用了Seaborn库的countplot()函数来绘制计数柱状图,并将x参数设置为gender、hue参数设置为grade,以按性别和成绩对学生进行分组。我们还添加了标签和标题,以使图形更加易于理解。
另外,我们使用了Matplotlib的legend()函数来设置图例位置。我们将loc(location)参数设置为upper right以将图例放置在右上角。
十、按班级查看成绩分布比例
使用 Seaborn 库中的 countplot 函数来实现这个任务。该函数可以接受一个数据集和若干关键字参数,用于指定要绘制的横坐标、纵坐标、颜色等信息。
以下是结合 sns.countplot 函数来展示数据集中不同班级中 L、M、H 成绩的人数分布情况完整代码:
import pandas as pd
import seaborn as sns
# 读取数据集
df = pd.read_csv('StudentPerformance.csv')
# 使用 Seaborn 绘制班级和成绩的人数分布情况
sns.countplot(x='班级', hue='成绩', hue_order=['L', 'M', 'H'], data=df)
# 显示图像
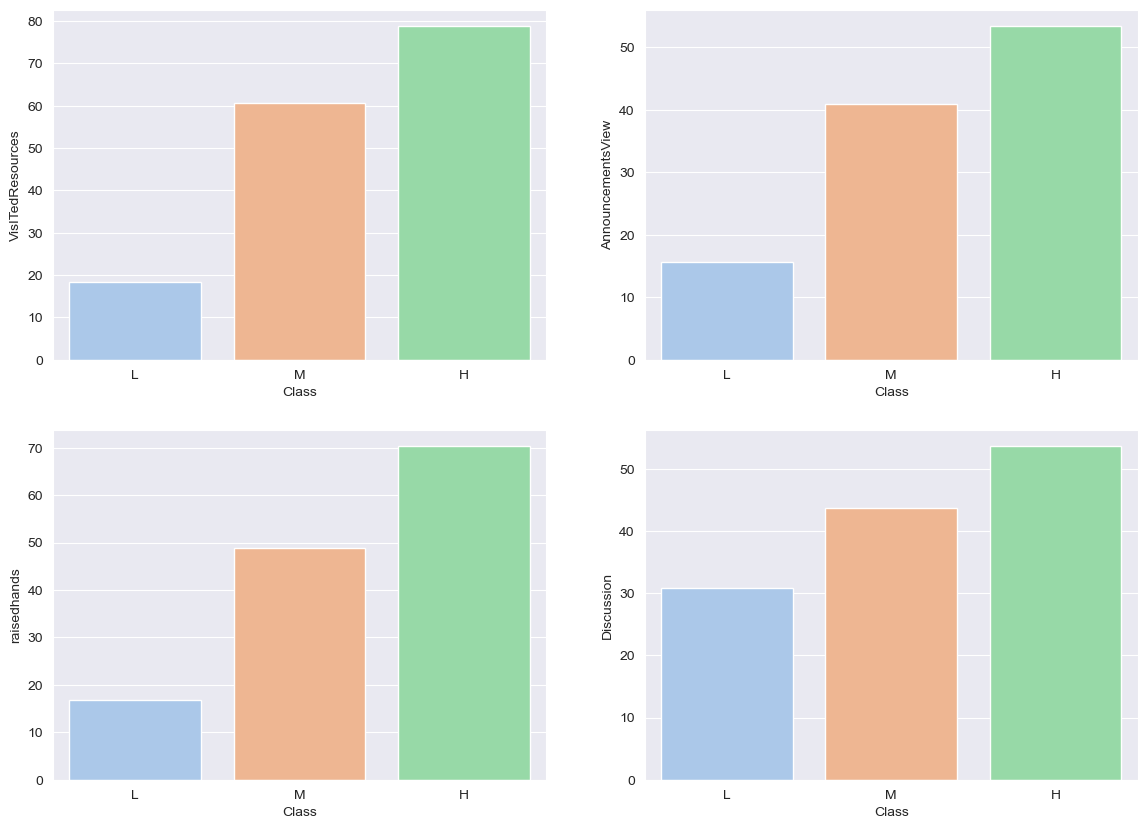
plt.show()十一、分析四个表现(浏览课件次数,浏览公告次数,举手次数,讨论次数)和成绩的相关性
分析四个表现指标(浏览课件次数、浏览公告次数、举手次数和讨论次数)与成绩之间的相关性,并使用 Seaborn 库中的 barplot 函数来展示四个表现指标在不同成绩段(L、M、H)之间的差异。这个任务可以通过计算每个分数段内四个表现指标的平均值来完成。可以使用 Seaborn 库中的 barplot 函数来实现这个任务。该函数可以接受一个数据集和若干关键字参数,用于指定要绘制的横坐标、纵坐标、颜色等信息。
以下是结合 sns.barplot 函数来展示四个表现指标在不同成绩段之间的差异的完整代码:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 读取数据集
df = pd.read_csv('StudentPerformance.csv')
# 计算每个成绩段内四个表现指标的平均值
mean_df = df.groupby('成绩').mean()[['浏览课件次数', '浏览公告次数', '举手次数', '讨论次数']].reset_index()
# 使用 Seaborn 绘制四个表现指标与成绩的关系
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
sns.barplot(x='成绩', y='浏览课件次数', data=mean_df, order=['L', 'M', 'H'], ax=axes[0, 0])
sns.barplot(x='成绩', y='浏览公告次数', data=mean_df, order=['L', 'M', 'H'], ax=axes[0, 1])
sns.barplot(x='成绩', y='举手次数', data=mean_df, order=['L', 'M', 'H'], ax=axes[1, 0])
sns.barplot(x='成绩', y='讨论次数', data=mean_df, order=['L', 'M', 'H'], ax=axes[1, 1])
# 显示图像
plt.show()
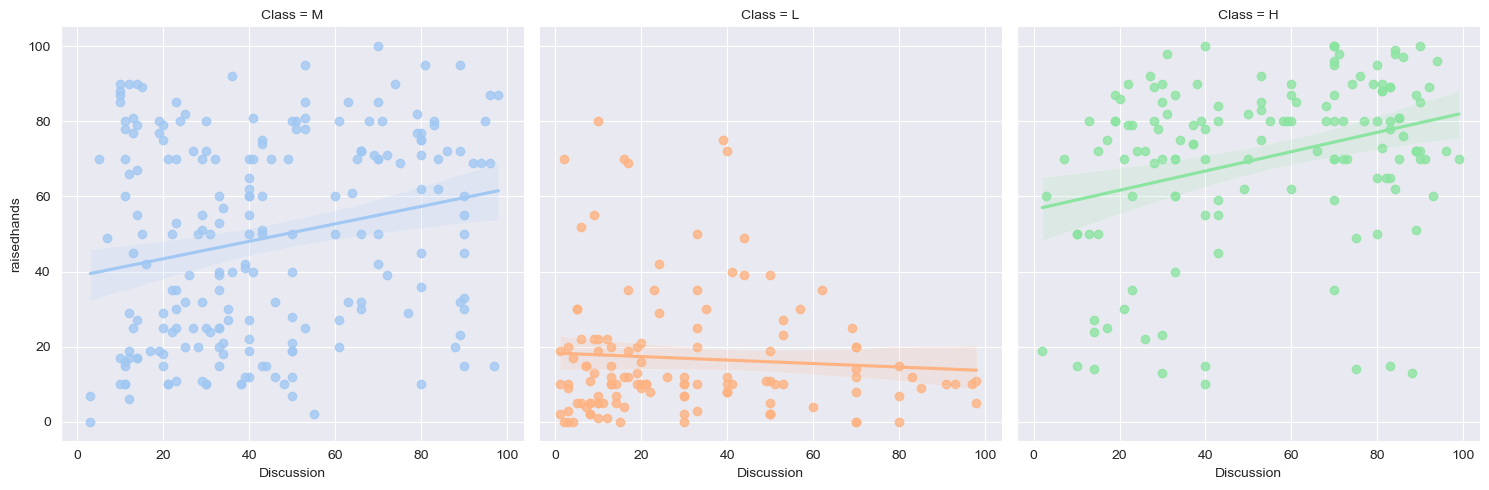
十二、分析不同成绩学生的讨论情况
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 读取数据集
df = pd.read_csv('StudentPerformance.csv')
# 绘制带有回归拟合线的散点图
sns.lmplot(x='Discussion', y='raisedhands', data=df, hue='Class', col='Class', col_wrap=3)
# 显示图像
plt.show()
在这个例子中,我们使用 lmplot 函数绘制了讨论次数 (Discussion) 和举手次数 (raisedhands) 之间的散点图,并使用颜色编码表示不同成绩的学生。通过设置 col 和 col_wrap 参数,我们将图像拆分为三个子图,按成绩级别排列。
十三、分析举手次数和参加讨论次数的相关性
可以使用散点图来分析举手次数和参加讨论次数的相关性。以下是一些可能的步骤:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 读取数据集
df = pd.read_csv('StudentPerformance.csv')
# 选择需要分析的两个特征
hand_raised = df['raisedhands']
discussions = df['Discussion']
# 绘制散点图
sns.scatterplot(x=hand_raised, y=discussions)
# 添加回归拟合线
sns.regplot(x=hand_raised, y=discussions, scatter=False)
# 显示图像
plt.show()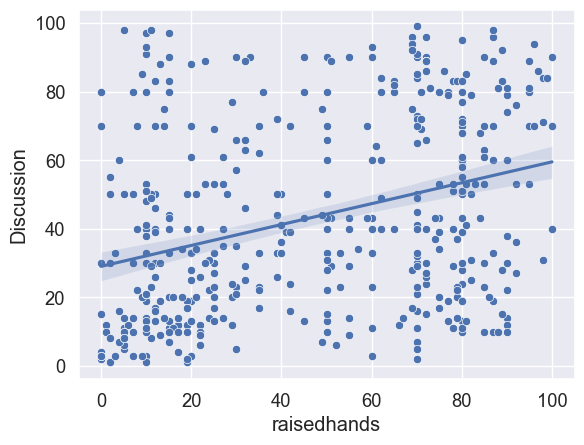
十四、分析浏览课件次数、举手次数、浏览公告次数、讨论次数之间的相关性,写出相关矩阵,并可视化。
要分析这四个特征之间的相关性并可视化,你可以首先使用 Pandas 的 corr() 函数计算它们之间的相关系数矩阵,然后使用 Seaborn 的 heatmap() 函数绘制热力图。
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 读取数据集
df = pd.read_csv('StudentPerformance.csv')
# 选择需要分析的四个特征
features = ['VisITedResources', 'raisedhands', 'AnnouncementsView', 'Discussion']
data = df[features]
# 计算相关系数矩阵
corr_matrix = data.corr()
# 绘制热力图
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm')
# 设置标题和坐标轴标签
plt.title('Correlation Matrix')
plt.xlabel('Features')
plt.ylabel('Features')
# 显示图像
plt.show()
这段代码将数据集中的四个特征选出来,并使用 corr() 函数计算它们之间的相关系数矩阵。然后,使用 heatmap() 函数绘制热力图,并设置了标题、坐标轴标签等细节。最后,使用 show() 函数显示图像。
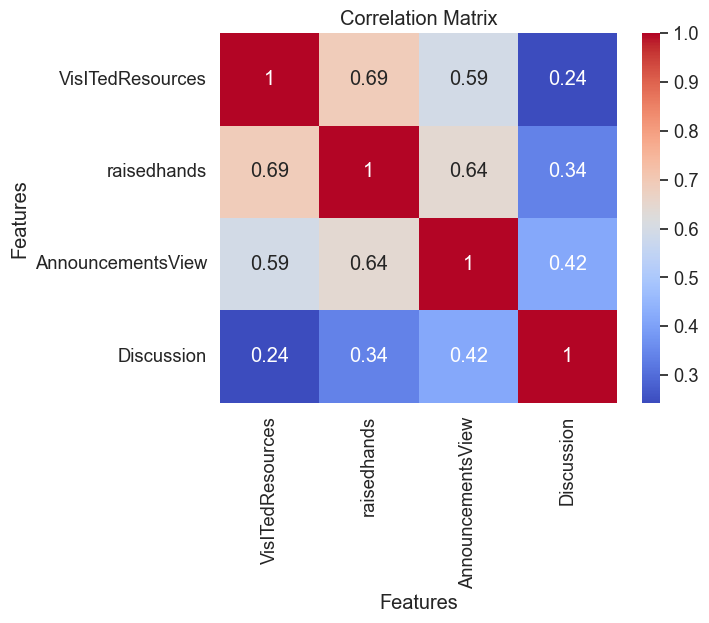
对于这四个特征(VisITedResources,raisedhands,AnnouncementsView,Discussion),它们之间的相关性比较强,其中 VisITedResources 和 raisedhands 之间的相关性最高,其次是 VisITedResources 和 AnnouncementsView 之间的相关性。而 Discussion 和其他三个特征之间的相关性相对较低。
这个结论可以帮助我们更好地理解这些特征之间的关系,并为进一步分析和预测学生的学习表现提供参考。例如,如果一个学生在课堂上经常参与讨论但从不浏览资源或查看公告,则可能需要更多的指导和支持,以帮助他们更全面地掌握课程内容。
总结
这个 Python 综合案例主要是通过对学生的数据进行可视化分析,来探究学生表现与学习行为之间的关系。在这个案例中,我们使用了 Pandas 和 Seaborn 这两个常用的 Python 库,来处理数据和绘制图形。具体而言,我们完成了以下工作:
通过上述工作,我们可以更加直观地了解学生的学习表现和学习行为之间的关系,同时也可以为后续的数据分析和预测提供参考。
原文地址:https://blog.csdn.net/m0_62338174/article/details/130460281
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_11365.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!







