本文介绍: 刚开始的时候我们业务的数据量比较少,直接使用“UNION ALL”等操作查询速度也很快,突然有一天线上的数据库开始报警,提示CPU占用过高,影响了线上的部分业务,慌得一批。,实时查询这种可以按表来查询,比如在页面上让用户主动选择 数据库(人工指定查哪个数据库),这种大概率就是数据抽样查看。此方法风险很大,不再赘述,对数据库压力较大,不是推荐的做法。的(分表的思路),因此并不会出现上述我们提到的查询语法场景,速度很快,不会有任何问题。线上真实的使用场景查询条件很多,也有对应的索引,一般是查询某个人的数据,
1、背景
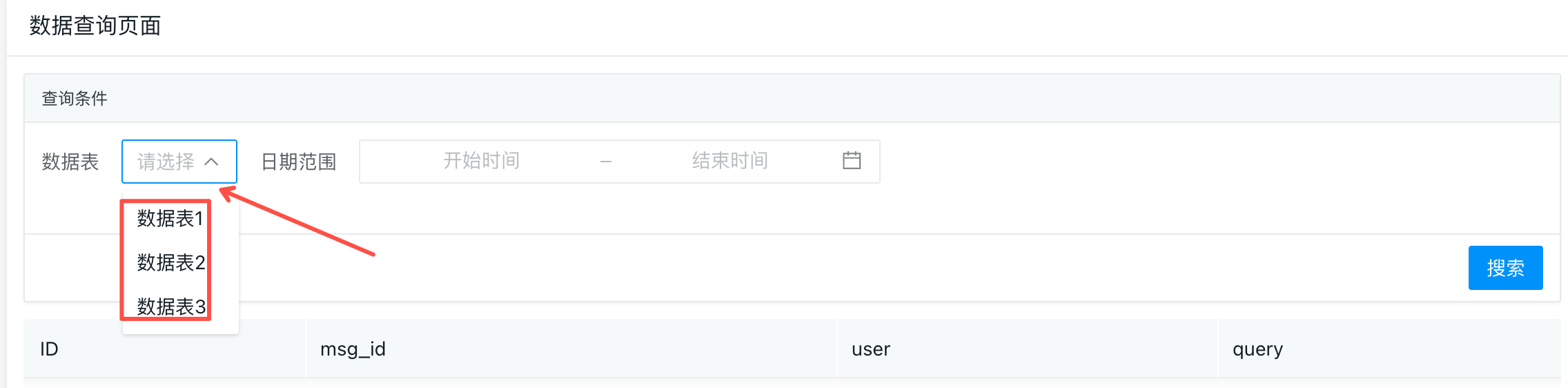
线上某个业务数据分表存储在10个子表中,现在需要快速按照条件(比如时间范围)筛选出所有的数据,主要是想做一个可视化的数据查询工具,给产研团队使用。
2、实践
注意:不要在线上真实数据库操作,操作前需要确认清楚。线上质量第一!线上质量第一!线上质量第一!
思路1:使用UNION ALL操作符将这些子表合并,然后在合并后的结果集上执行查询操作。
假设现在有10个子表,命名为table_1, table_2, …, table_10,并且每个表中都有一个表示时间的字段 timestamp_column,可以使用以下查询来按照时间范围筛选出所有的数据:
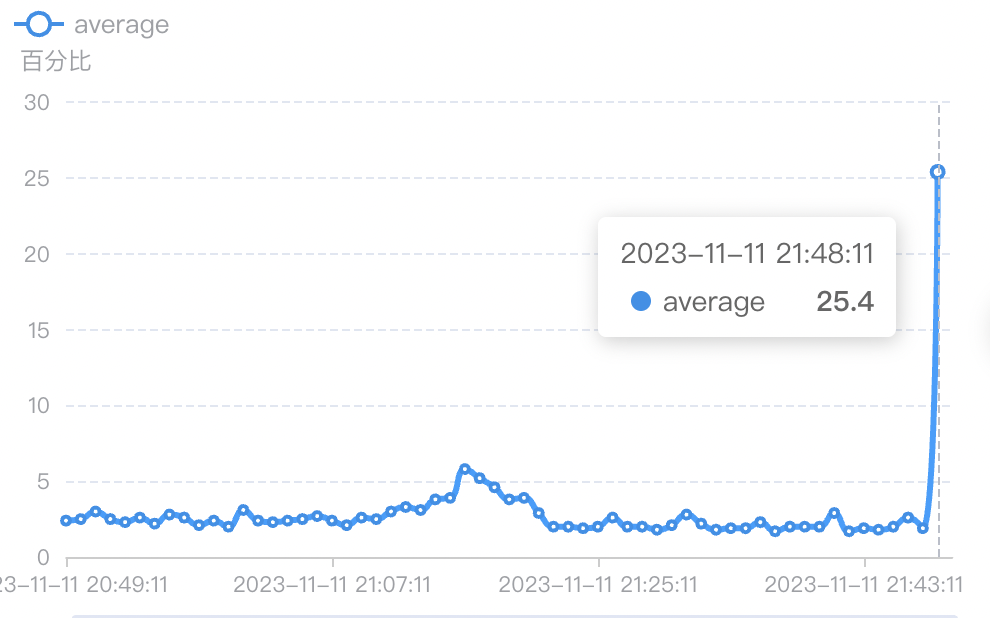

3、思考&方案
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。