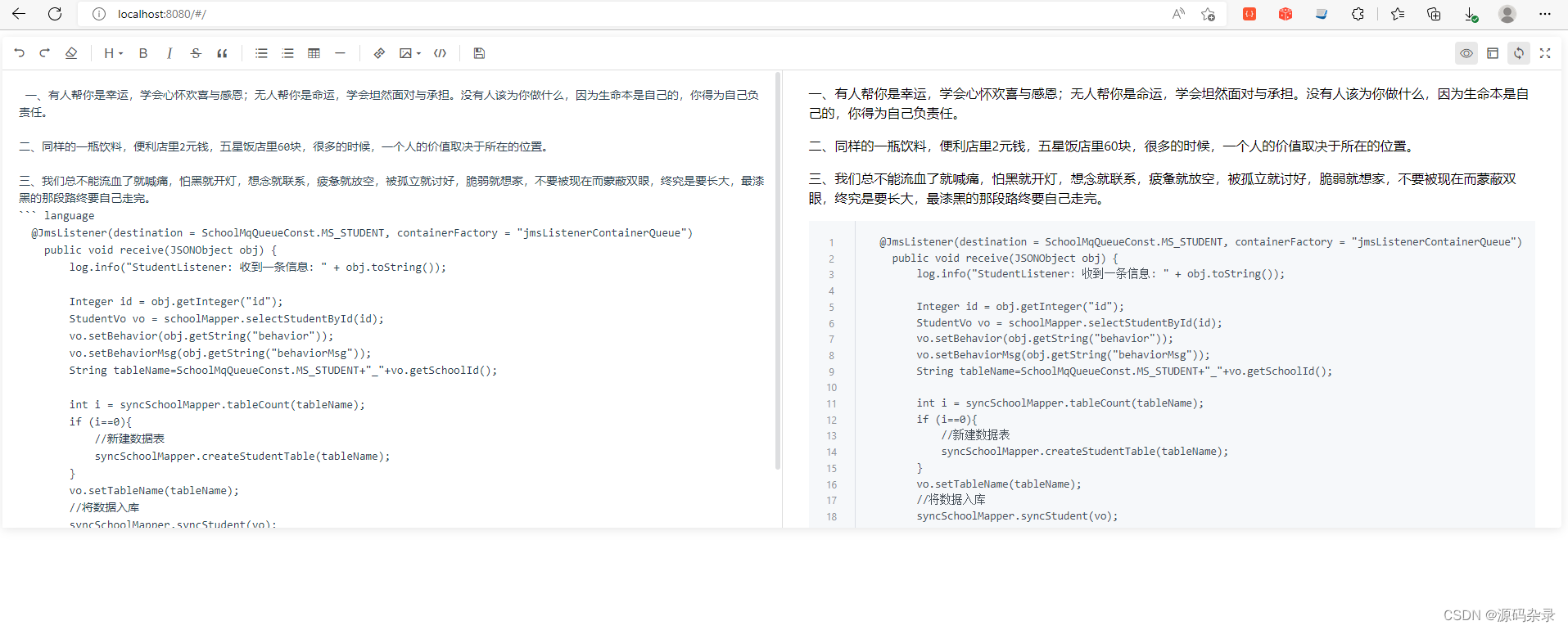
挖掘文本的奇妙力量:传统与深度方法探索匹配之道

许多 NLP 任务的成功离不开训练优质有效的文本表示向量。特别是文本语义匹配(Semantic Textual Similarity,如 paraphrase 检测、QA 的问题对匹配)、文本向量检索(Dense Text Retrieval)等任务。
1. 传统方法:基于特征的匹配
代表模型:
BM25 算法,通过候选句子的字段对 qurey 字段的覆盖程度来计算两者间的匹配得分,得分越高的候选项与 query 的匹配度更好,主要解决词汇层面的相似度问题。
2.深度方法:基于表征的匹配
代表模型:
3.深度方法:基于交互的匹配
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。