话不多说,开干!!!
1. 使用 csv 模块
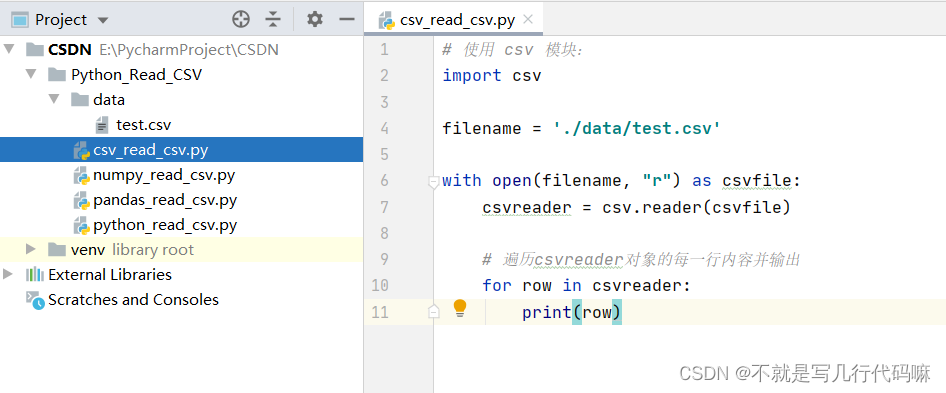
(2)代码如下:
import csv
filename = './data/test.csv'
with open(filename, "r") as csvfile:
csvreader = csv.reader(csvfile)
# 遍历csvreader对象的每一行内容并输出
for row in csvreader:
print(row)
(3)效果如下:

2.使用 numpy 库
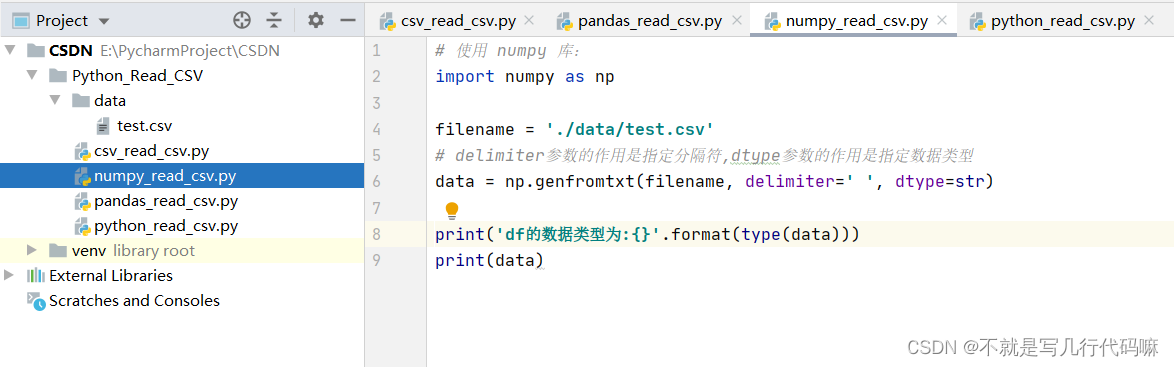
(2)代码如下:
# 使用 numpy 库:
import numpy as np
filename = './data/test.csv'
# delimiter参数的作用是指定分隔符,dtype参数的作用是指定数据类型
data = np.genfromtxt(filename, delimiter=' ', dtype=str)
print('df的数据类型为:{}'.format(type(data)))
print(data)(3)效果如下:
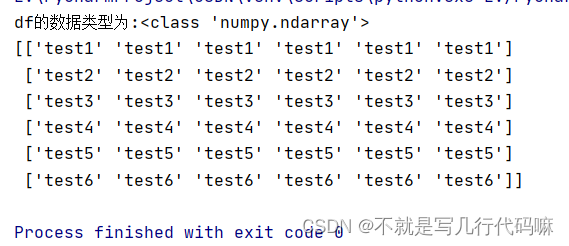
3.使用pandas库
(1)项目结构如下:
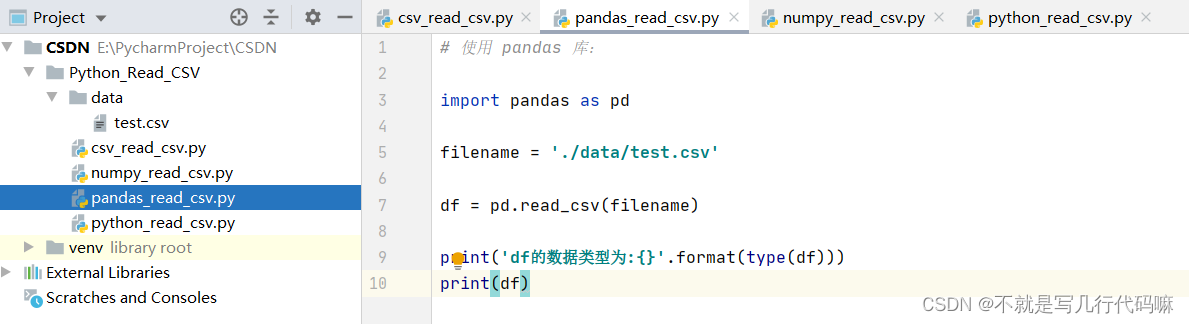
(2)代码如下:
# 使用 pandas 库:
import pandas as pd
filename = './data/test.csv'
df = pd.read_csv(filename)
print('df的数据类型为:{}'.format(type(df)))
print(df)(3)效果如下:

4.使用标准库中的 csv 模块
(1)项目结构如下:

(2)代码如下:
# 使用标准库中的 csv 模块:
import csv
filename = './data/test.csv'
with open(filename, newline='') as csvfile:
reader = csv.DictReader(csvfile)
# 遍历csvreader对象的每一行内容并输出
for row in reader:
print(row)(3)效果如下:
5.注意事项
请注意,这个程序假设您的 CSV 文件已经存在,并且可以被正确读取。如果您的 CSV 文件不在当前目录中,您需要提供完整的文件路径。
这些方法在读取 CSV 文件时都有不同的优缺点,您可以根据自己的需求选择合适的方法。例如,如果您想要快速、方便地处理 CSV 文件并将其转换为 DataFrame 对象,则可以使用 pandas 库;如果您想要更高级的控制和更灵活的选项,则可以使用标准库中的 csv 模块。
原文地址:https://blog.csdn.net/spx_0108/article/details/130706946
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_11787.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。




