本文介绍: 可以用来修改某一列读取的参数类型,一般在数据读取的时候,读到某一列全部是数据,会默认把该列的数据类型定义为int类型,但是,如果遇到数据是0开头的,就会出现问题,因此,可以使用dtype来定义某一列的数据类型为想要的类型,一般是把int类型定义为str类型读取。举个不太恰当的例子,张三买车得到了一次砸金蛋的机会,他当然不能用手砸,于是他顺手抄起旁边的锤子就砸了一个金蛋。用来读取数据的前5行,pandas会在读取数据后自动在数据前加一行索引,也就是在YM前面的一列,这个索引一般是用来定位数据的。
基础知识
pandas 可以读取多种的数据格式,针对excel来说,可以使用read_excel()读取数据,如下:

但是,值得注意的是:pandas在读取excel文件的时候需要调用读取第三方库(简称 引擎)
举个不太恰当的例子,张三买车得到了一次砸金蛋的机会,他当然不能用手砸,于是他顺手抄起旁边的锤子就砸了一个金蛋。这个例子里面的张三相当于pandas,金蛋就是excel文件,锤子就是读取文件的引擎。
在pandas中支持四种excel的文件读取引擎,我们用的最多的是”xlrd“和”openpyxl“,其中”xlrd“是用来读取“.xls“文件的,而”openpyxl“是用来读取“.xlsx“及其他07版以后的新格式
其实”xlrd“和”openpyxl“都是python的库,可以单独的安装使用。命令:pip install xlrd
语法
参数详解–index_col


参数详解–header
参数详解–usecols
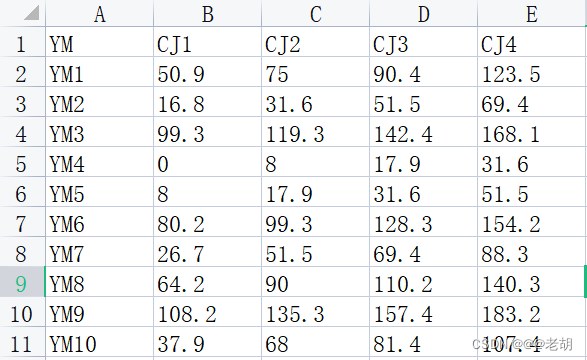
参数详解-dtype
其他参数
多表读取
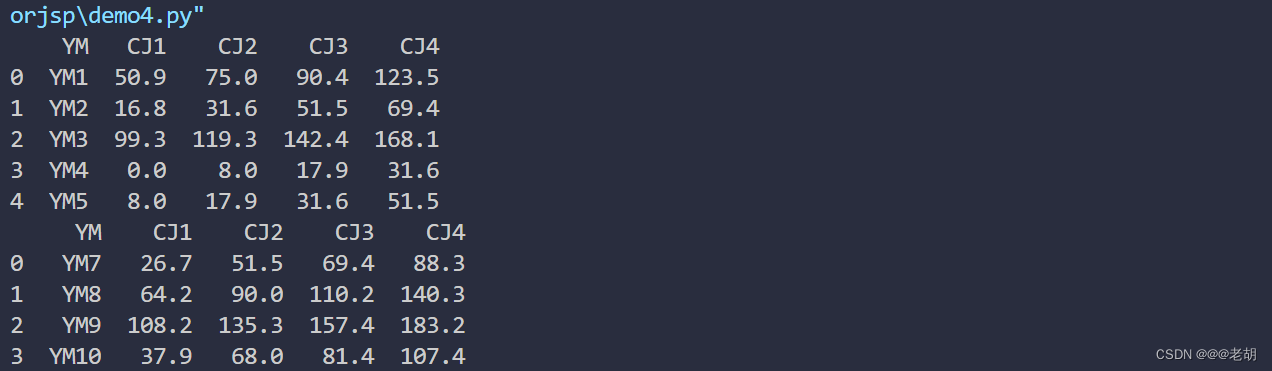
顺带提一句如何用pandas写数据到excel
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。