一、词向量引入
先来考虑一个问题:如何能将文本向量化呢?听起来比较抽象,我们可以先从人的角度来思考。
如何用一个数值向量描述一个人呢?只用身高或者体重,还是综合其各项指标呢?当然是综合各项指标能更加准确的描述一个人啦,具体什么指标还得看你能收集到什么指标。比如除了常规的身高、体重外,我们还可以用人的性格,从内向到外向设置为从-1到+1,人的性格让“专家”去打分,从而获取人性格的数值化数据。
只要有了向量,就可以用不同方法(欧氏距离、曼哈顿距离、切比雪夫距离、余弦相似度等)来计算两个向量之间的相似度了!

通常来说,向量的维度越高,能提供的信息也就越多,从而计算结果的可靠性就更值得信赖

现在回到正题,如何描述词的特征?通常都是在词的层面上来构建特征。Word2Vec就是要把词转化为向量。

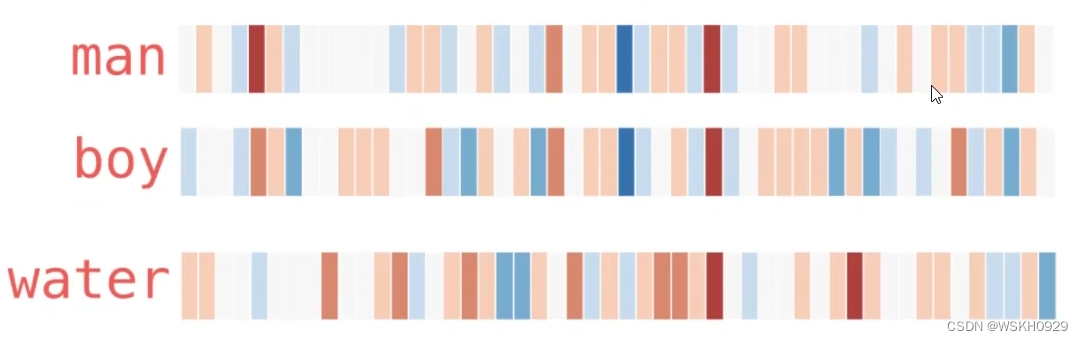
假设现在已经拿到了一份训练好的词向量,其中每一个词都表示为50维的向量,如下图所示:


在结果中可以发现,相似的词在特征表达中比较相似,也就是说明词的特征是有实际意义的!
二、词向量模型

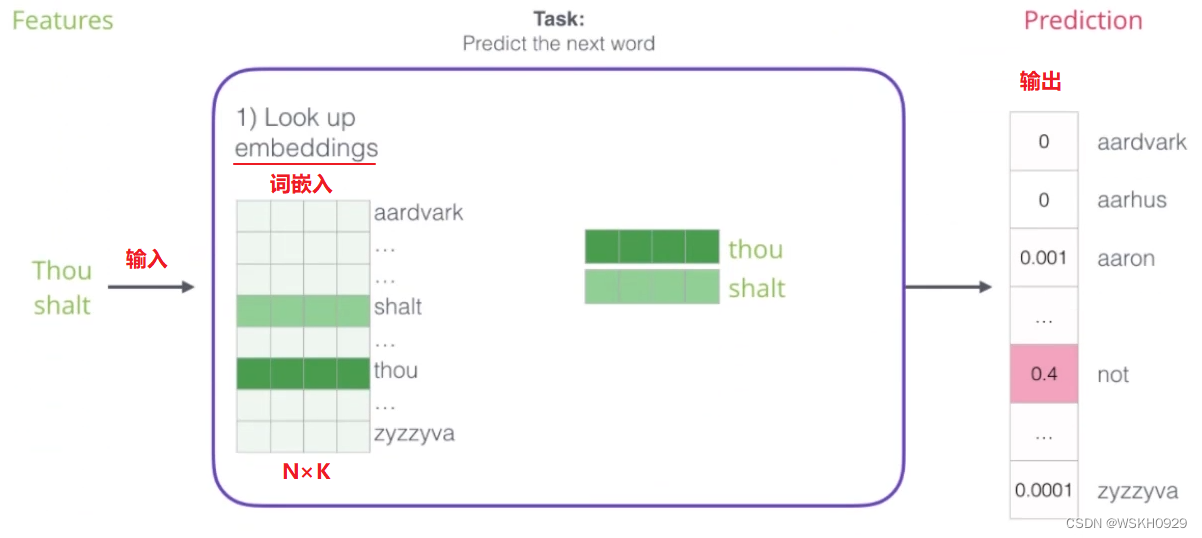
如下图所示,在词向量模型中,输入可以是多个词。例如下面所示的,输入是 Thou 和 shalt,模型的任务是预测它们的下一个词是什么。
最后一层连接了 SoftMax,所以网络的输出是所有词可能是下一个词的概率。

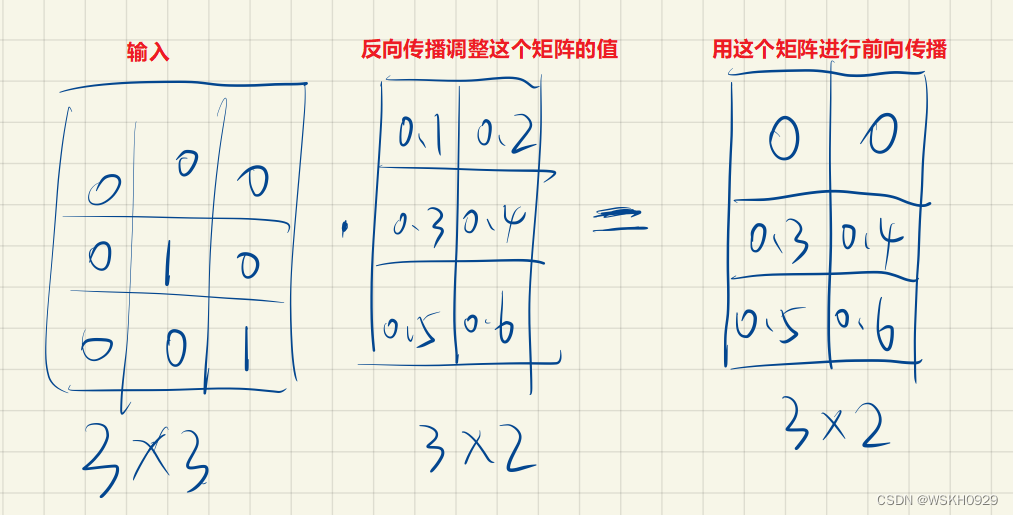
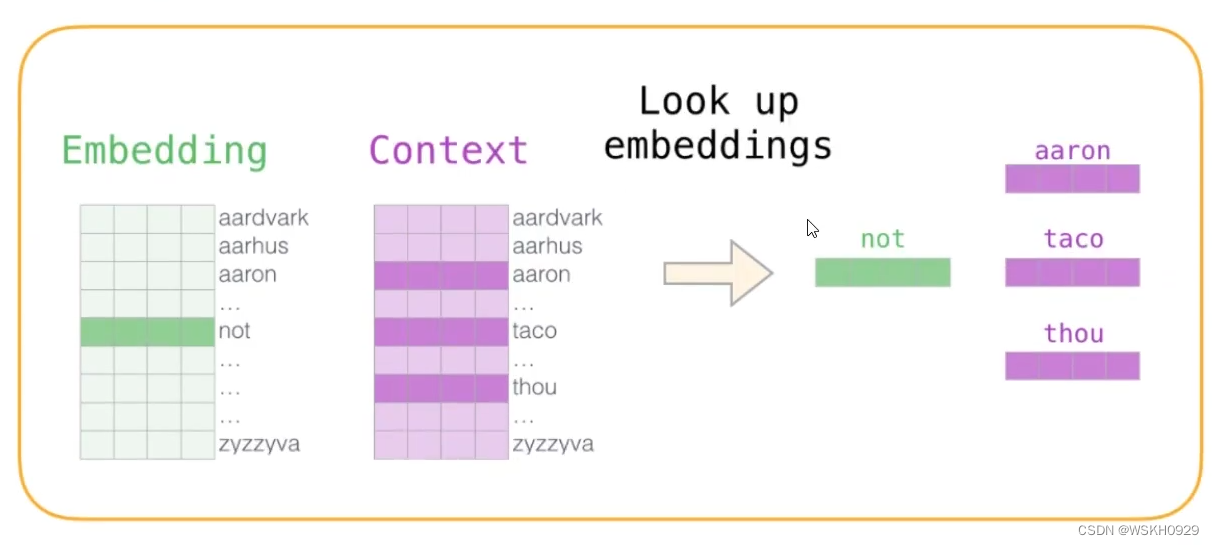
那么有人就会问了,输入是文字,文字怎么输入到神经网络中啊 ?这个问题很好,我们通常会用一个 Embedding 层来解决这个问题。如下图所示,在神经网络初始化的时候,我们会随机初始化一个 N×K 的矩阵,其中 N 是 词典的大小,K 是词向量的维数(一个自行设定的超参数)。然后,我们会用一个 N×N 的矩阵和 N×K 的矩阵相乘,得到一个新的 N×K的矩阵向下进行前向传播。其中,N×N 的矩阵会在输入的文字的对应对角线上设置为1,其余位置均为0。N×K 的矩阵是随机初始化的,通过反向传播进行更新调整。
下面展示了一个例子(假设输入的两个词在词典中的位置是2和3处):
三、训练数据构建
答:一切具有正常逻辑的语句都可以作为训练数据。如小说、论文等。
如果我们有一个句子,那么我们可以按照下面你的方式构建数据集,选出前三个词,用前两个作为词模型的输入,最后一个词作为词模型输出的目标,继而进行训练。如下图所示:

然后,我们还可以将”窗口“往右平移一个词,如下图所示,构造一个新的训练数据

当然,这个”窗口“的宽度也是可以自己设置的,在上例中,窗口宽度设置为 3,也可以设置为 4、5、6 等等
四、不同模型对比
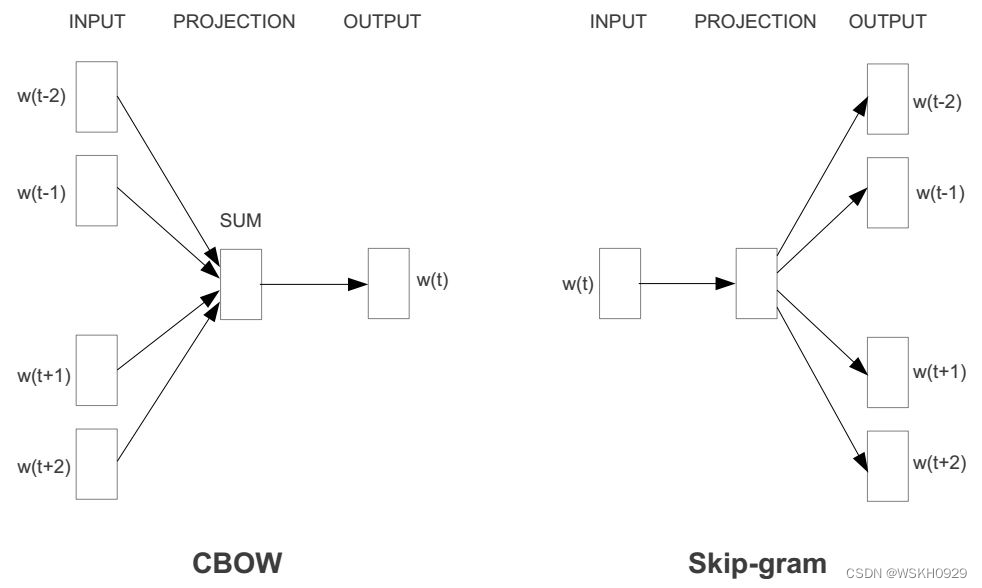
4.1 CBOW
CBOW的全称是continuous bag of words(连续词袋模型)。其本质也是通过context word(背景词)来预测target word(目标词)。
CBOW之所以叫连续词袋模型,是因为在每个窗口内它也不考虑词序信息,因为它是直接把上下文的词向量相加了,自然就损失了词序信息。CBOW抛弃了词序信息,指的就是在每个窗口内部上下文直接相加而没有考虑词序。

4.2 Skip-gram 模型
Skip-gram 模型和 CBOW 相反,Skip-gram 模型的输入是一个词汇,输出则是该词汇的上下文。如下图所示:

下面举一个例子,设”窗口“宽度为5,每次用”窗口“的第三个也就是中的词汇作为输入,其余上下文作为输出,分别构建数据集,如下图所示:


如果一个语料库稍微大一点,可能的结果就太多了,最后一层 SoftMax 的计算就会很耗时,有什么办法来解决吗?
下面提出了一个初始解决方案:假设,传统模型中,我们输入 not ,希望输出是 thou,但是由于语料库庞大,最后一层 SoftMax 太过耗时,所以我们可以改为:将 not 和 thou 同时作为输入,做一个二分类问题,类别 1 表示 not 和 thou 是邻居,类别 0 表示它们不是邻居。
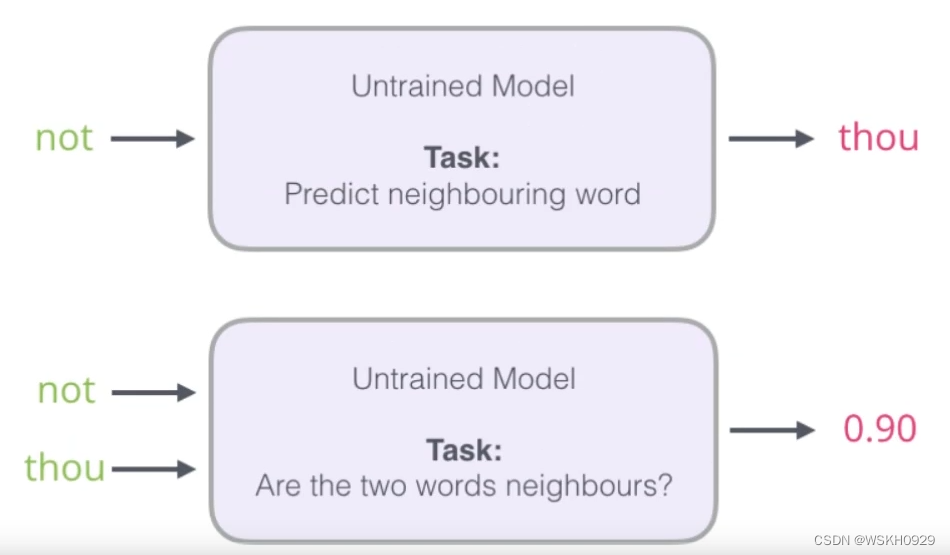
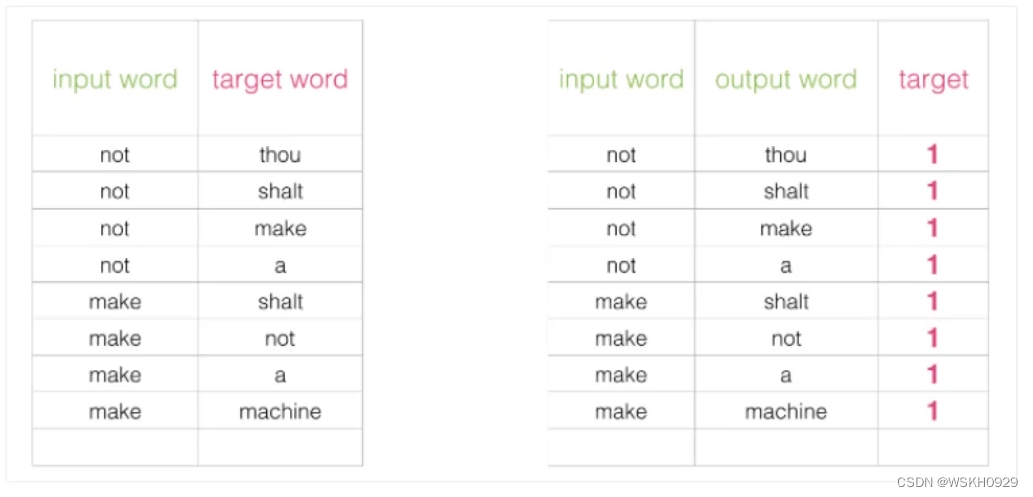
上面提到的解决方案出发点非常好,但是由于训练集本来就是用上下文构建出来的,所以训练集构建出来的标签全为 1 ,无法较好的进行训练,如下图所示:
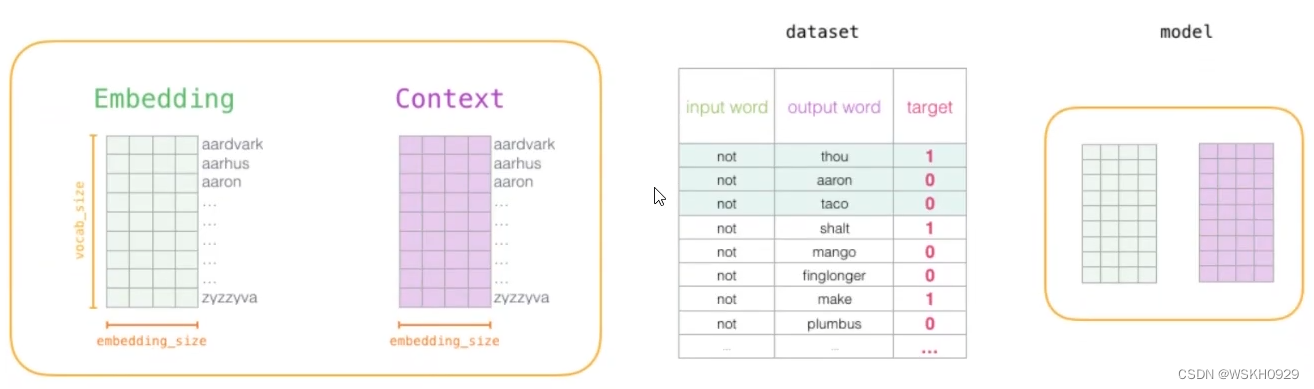
改进方案:加入一些负样本(负采样模型),一般负采样个数为 5 个就好,负采样示意图如下图所示:

4.3 CBOW 和 Skip-gram 对比
五、词向量训练过程
5.1 初始化词向量矩阵
5.2 训练模型
通过神经网络反向传播来计算更新,此时不光更新权重参数矩阵W,也会更新输入数据

训练完成后,我们就得到了比较准确的 Word Embeddings,从而得到了每个词的向量表示!!!
六、Python 代码实战
6.1 Model
from torch import nn
class DNN(nn.Module):
def __init__(self, vocabulary_size, embedding_dim):
super(DNN, self).__init__()
self.embedding = nn.Linear(vocabulary_size, embedding_dim, bias=False)
print("embedding_size:", list(self.embedding.weight.size()))
self.layers = nn.Sequential(
nn.Linear(vocabulary_size * embedding_dim, embedding_dim // 2),
nn.LeakyReLU(),
nn.Linear(embedding_dim // 2, 4),
nn.LeakyReLU(),
nn.Linear(4, 1),
)
# Mean squared error loss
self.criterion = nn.MSELoss()
# self.criterion = nn.CrossEntropyLoss()
def forward(self, x):
x = self.embedding(x)
x = x.view(x.size()[0], -1)
x = self.layers(x)
x = x.squeeze(1)
return x
def cal_loss(self, pred, target):
""" Calculate loss """
return self.criterion(pred, target)
6.2 DataSet
import random
import numpy as np
from torch.utils.data import Dataset
class MyDataSet(Dataset):
def __init__(self, features, labels):
self.features = features
self.labels = labels
def __getitem__(self, index):
return self.features[index], self.labels[index]
def __len__(self):
return len(self.features)
def get_data_set(data_path, window_width, window_step, negative_sample_num):
with open(data_path, 'r', encoding='utf-8') as file:
document = file.read()
document = document.replace(",", "").replace("?", "").replace(".", "").replace('"', '')
data = document.split(" ")
print(f"数据中共有 {len(data)} 个单词")
# 构造词典
vocabulary = set()
for word in data:
vocabulary.add(word)
vocabulary = list(vocabulary)
print(f"词典大小为 {len(vocabulary)}")
# index_dict
index_dict = dict()
for index, word in enumerate(vocabulary):
index_dict[word] = index
# 开始滑动窗口,构造数据
features = []
labels = []
neighbor_dict = dict()
for start_index in range(0, len(data), window_step):
if start_index + window_width - 1 < len(data):
mid_index = int((start_index + start_index + window_width - 1) / 2)
for index in range(start_index, start_index + window_width):
if index != mid_index:
feature = np.zeros((len(vocabulary), len(vocabulary)))
feature[index_dict[data[index]]][index_dict[data[index]]] = 1
feature[index_dict[data[mid_index]]][index_dict[data[mid_index]]] = 1
features.append(feature)
labels.append(1)
if data[mid_index] in neighbor_dict.keys():
neighbor_dict[data[mid_index]].add(data[index])
else:
neighbor_dict[data[mid_index]] = {data[index]}
# 负采样
for _ in range(negative_sample_num):
random_word = vocabulary[random.randint(0, len(vocabulary))]
for word in vocabulary:
if random_word not in neighbor_dict.keys() or word not in neighbor_dict[random_word]:
feature = np.zeros((len(vocabulary), len(vocabulary)))
feature[index_dict[random_word]][index_dict[random_word]] = 1
feature[index_dict[word]][index_dict[word]] = 1
features.append(feature)
labels.append(0)
break
# 返回dataset和词典
return MyDataSet(features, labels), vocabulary, index_dict
6.3 Main
import random
from math import sqrt
import numpy as np
import torch
from torch.utils.data import DataLoader
from Python.机器学习.唐宇迪机器学习.词向量.DataSet import get_data_set
from Python.机器学习.唐宇迪机器学习.词向量.Model import DNN
def same_seed(seed):
"""
Fixes random number generator seeds for reproducibility
固定时间种子。由于cuDNN会自动从几种算法中寻找最适合当前配置的算法,为了使选择的算法固定,所以固定时间种子
:param seed: 时间种子
:return: None
"""
torch.backends.cudnn.deterministic = True # 解决算法本身的不确定性,设置为True 保证每次结果是一致的
torch.backends.cudnn.benchmark = False # 解决了算法选择的不确定性,方便复现,提升训练速度
np.random.seed(seed) # 按顺序产生固定的数组,如果使用相同的seed,则生成的随机数相同, 注意每次生成都要调用一次
torch.manual_seed(seed) # 手动设置torch的随机种子,使每次运行的随机数都一致
random.seed(seed)
if torch.cuda.is_available():
# 为GPU设置唯一的时间种子
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
def train(model, train_loader, config):
# Setup optimizer
optimizer = getattr(torch.optim, config['optimizer'])(
model.parameters(), **config['optim_hyper_paras'])
device = config['device']
epoch = 0
while epoch < config['n_epochs']:
model.train() # set model to training mode
loss_arr = []
for x, y in train_loader: # iterate through the dataloader
optimizer.zero_grad() # set gradient to zero
x, y = x.to(device).to(torch.float32), y.to(device).to(torch.float32) # move data to device (cpu/cuda)
pred = model(x) # forward pass (compute output)
mse_loss = model.cal_loss(pred, y) # compute loss
mse_loss.backward() # compute gradient (backpropagation)
optimizer.step() # update model with optimizer
loss_arr.append(mse_loss.item())
print(f"epoch: {epoch}/{config['n_epochs']} , loss: {np.mean(loss_arr)}")
epoch += 1
print('Finished training after {} epochs'.format(epoch))
def find_min_distance_word_vector(cur_i, vector, embeddings, vocabulary):
def calc_distance(v1, v2):
# 计算欧式距离
distance = 0
for i in range(len(v1)):
distance += sqrt(pow(v1[i] - v2[i], 2))
return distance
min_distance = None
min_i = -1
for i, word in enumerate(vocabulary):
if cur_i != i:
distance = calc_distance(vector, embeddings[i].tolist())
if min_distance is None or min_distance > distance:
min_distance = distance
min_i = i
return min_i
if __name__ == '__main__':
data_path = './data/data.txt'
config = {
'seed': 3407, # Your seed number, you can pick your lucky number. :)
'device': 'cuda' if torch.cuda.is_available() else 'cpu',
'n_epochs': 20, # Number of epochs.
'batch_size': 64,
'optimizer': 'Adam',
'optim_hyper_paras': { # hyper-parameters for the optimizer (depends on which optimizer you are using)
'lr': 0.001, # learning rate of optimizer
},
'embedding_dim': 6, # 词向量长度
'window_width': 5, # 窗口的宽度
'window_step': 2, # 窗口滑动的步长
'negative_sample_num': 10 # 要增加的负样本个数
}
same_seed(config['seed'])
data_set, vocabulary, index_dict = get_data_set(data_path, config['window_width'], config['window_step'],
config['negative_sample_num'])
train_loader = DataLoader(data_set, config['batch_size'], shuffle=True, drop_last=False, pin_memory=True)
model = DNN(len(vocabulary), config['embedding_dim']).to(config['device'])
train(model, train_loader, config)
# 训练完,看看embeddings,展示部分词的词向量,并找到离它最近的词的词向量
embeddings = torch.t(model.embedding.weight)
for i in range(10):
print('%-50s%s' % (f"{vocabulary[i]} 的词向量为 :", str(embeddings[i].tolist())))
min_i = find_min_distance_word_vector(i, embeddings[i].tolist(), embeddings, vocabulary)
print('%-45s%s' % (
f"离 {vocabulary[i]} 最近的词为 {vocabulary[min_i]} , 它的词向量为 :", str(embeddings[min_i].tolist())))
print('-' * 200)
6.4 运行输出
数据中共有 1803 个单词
词典大小为 511
embedding_size: [6, 511]
epoch: 0/20 , loss: 0.0752271132772429
epoch: 1/20 , loss: 0.01744390495137818
epoch: 2/20 , loss: 0.0030546926833554416
epoch: 3/20 , loss: 0.0025285633501449696
epoch: 4/20 , loss: 0.002311844104776371
epoch: 5/20 , loss: 0.002020565740071776
epoch: 6/20 , loss: 0.001762585903602405
epoch: 7/20 , loss: 0.0015661540336415719
epoch: 8/20 , loss: 0.0013828050599872846
epoch: 9/20 , loss: 0.0010562216170033104
epoch: 10/20 , loss: 0.0008050707044451867
epoch: 11/20 , loss: 0.0006666925565903575
epoch: 12/20 , loss: 0.0005228724374622592
epoch: 13/20 , loss: 0.00041554564311234953
epoch: 14/20 , loss: 0.0003863844721659884
epoch: 15/20 , loss: 0.00024095189464708056
epoch: 16/20 , loss: 0.0001828093964042254
epoch: 17/20 , loss: 0.0001404089290716863
epoch: 18/20 , loss: 0.00010190787191819701
epoch: 19/20 , loss: 6.971220871894714e-05
Finished training after 20 epochs
well 的词向量为 : [0.2800050377845764, -0.28451332449913025, -0.288005530834198, -0.3119206130504608, 0.2786404490470886, 0.31298771500587463]
离 well 最近的词为 first , 它的词向量为 : [0.11318866163492203, -0.1251109391450882, -0.13063986599445343, -0.11296737194061279, 0.1378508061170578, 0.13971801102161407]
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
submitted 的词向量为 : [0.15754808485507965, -0.12277694046497345, -0.14227379858493805, -0.14454570412635803, 0.05900704860687256, 0.09546193480491638]
离 submitted 最近的词为 benefit , 它的词向量为 : [0.13462799787521362, -0.10862613469362259, -0.10275529325008392, -0.07748148590326309, 0.10121206194162369, 0.10051087290048599]
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
even 的词向量为 : [-0.11601416021585464, -0.10113148391246796, -0.1214226558804512, -0.10180512815713882, -0.09548257291316986, -0.11160479485988617]
离 even 最近的词为 working , 它的词向量为 : [-0.1340179741382599, -0.10384820401668549, -0.1085871234536171, -0.09771087765693665, -0.09202782064676285, -0.11302905529737473]
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
thus 的词向量为 : [0.1400231420993805, 0.11062948405742645, -0.13136275112628937, -0.14278383553028107, 0.0380394384264946, 0.1342836171388626]
离 thus 最近的词为 problem , 它的词向量为 : [0.13799253106117249, 0.12232215702533722, -0.11594908684492111, -0.14511127769947052, 0.11674903333187103, 0.14989981055259705]
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
so 的词向量为 : [-0.13579697906970978, -0.1544174700975418, -0.13814400136470795, 0.1473793238401413, -0.13407182693481445, -0.16138871014118195]
离 so 最近的词为 role , 它的词向量为 : [-0.13371147215366364, -0.1268460601568222, -0.12891902029514313, 0.10279709100723267, -0.11447536945343018, -0.14199912548065186]
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
decisions 的词向量为 : [-0.11366508901119232, 0.16771574318408966, 0.1678972989320755, -0.1269330531358719, -0.05488301441073418, 0.03212495520710945]
离 decisions 最近的词为 graduation , 它的词向量为 : [-0.1385655254125595, 0.11743943393230438, 0.16122682392597198, -0.08773274719715118, -0.10684341937303543, -0.018613960593938828]
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
retained 的词向量为 : [0.1318095624446869, 0.1072487011551857, -0.09701842069625854, 0.12827205657958984, -0.07958601415157318, 0.12242742627859116]
离 retained 最近的词为 but , 它的词向量为 : [0.12475789338350296, 0.10641714930534363, -0.10653595626354218, 0.10686526447534561, -0.11097636818885803, 0.12155742198228836]
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
not 的词向量为 : [0.11732926964759827, -0.1214861199259758, -0.12549108266830444, -0.14001798629760742, -0.11948511749505997, 0.10462098568677902]
离 not 最近的词为 we , 它的词向量为 : [0.11353950947523117, -0.12036407738924026, -0.12329546362161636, -0.10175121575593948, -0.11156024783849716, 0.08613568544387817]
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
agree 的词向量为 : [0.1323355734348297, 0.07596761733293533, -0.1199847161769867, -0.07760312408208847, 0.12063225358724594, -0.12207814306020737]
离 agree 最近的词为 attitudes , 它的词向量为 : [0.1297885924577713, 0.0682920590043068, -0.11543254554271698, -0.08852613717317581, 0.1026940643787384, -0.15329356491565704]
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
our 的词向量为 : [-0.005921764764934778, 0.13929229974746704, -0.12112995237112045, 0.11011514812707901, 0.10238232463598251, 0.11239470541477203]
离 our 最近的词为 iron-faced , 它的词向量为 : [-0.11445378512144089, 0.12393463402986526, -0.12114288657903671, 0.11323738098144531, 0.1026541218161583, 0.11349711567163467]
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
原文地址:https://blog.csdn.net/weixin_51545953/article/details/128622118
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_12197.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!







