Excel工作表是非常本能和用户友好的,这使得它们非常适合操作大型数据集,即使是技术人员也不例外。如果您正在寻找学习使用Python在Excel文件中操作和自动化内容的地方,请不要再找了。你来对地方了。
在本文中,您将学习如何使用Pandas来处理Excel电子表格。在文章的最后,您将了解:
安装
要在Anaconda中安装Pandas,我们可以在Anaconda终端中使用以下命令:
conda install pandas
要在常规Python(非Anaconda)中安装Pandas,我们可以在命令提示符中使用以下命令:
pip install pandas
开始使用
首先,我们需要导入Pandas模块,这可以通过运行命令来完成:
import pandas as pd
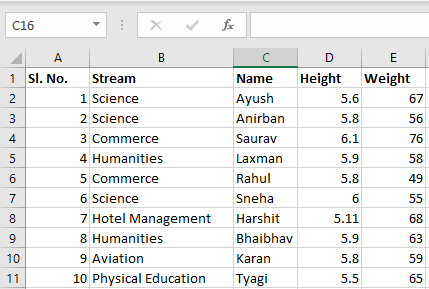
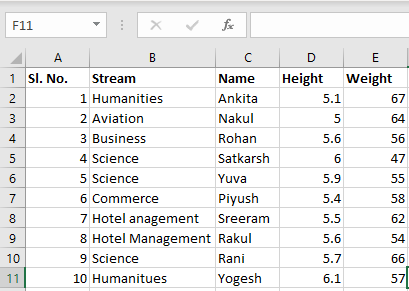
现在我们可以使用Pandas中的read_excel函数导入excel文件。第二个语句从excel中读取数据并将其存储到pandas数据框中,该数据框由变量newData表示。如果excel工作簿中有多个工作表,则该命令将导入第一个工作表的数据。要使用工作簿中的所有工作表创建数据框,最简单的方法是分别创建不同的数据框,然后将它们连接起来。read_excel方法接受参数sheet_name和index_col,我们可以指定数据框应该由哪个工作表组成,index_col指定标题列,如下所示:
file =('path_of_excel_file')
newData = pd.read_excel(file)
newData
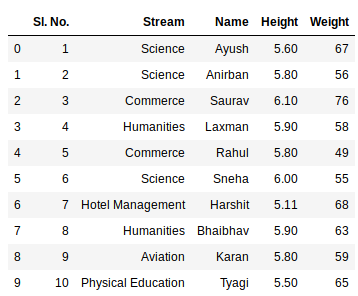
示例:
第三个语句连接两个表。现在要检查整个数据帧,我们可以简单地运行以下命令:
sheet1 = pd.read_excel(file,
sheet_name = 0,
index_col = 0)
sheet2 = pd.read_excel(file,
sheet_name = 1,
index_col = 0)
newData = pd.concat([sheet1, sheet2])
newData
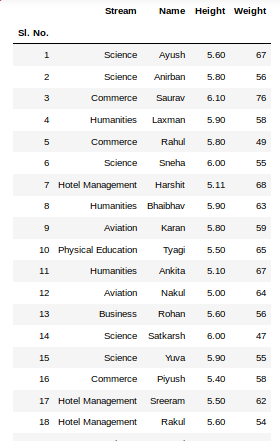
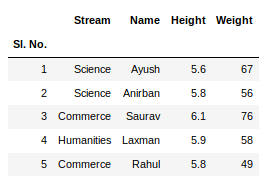
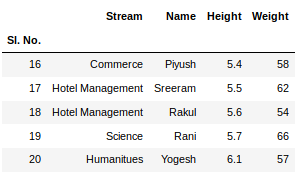
要从数据框的顶部和底部查看5列,可以运行命令。这个head()和tail()方法也接受参数作为要显示的列数的数字。
newData.head()
newData.tail()
newData.shape

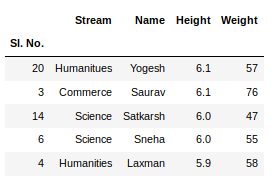
如果任何列包含数值数据,我们可以使用pandas中的sort_values()方法对该列进行排序,如下所示:
sorted_column = newData.sort_values(['Height'], ascending = False)
现在,假设我们想要排序列的前5个值,我们可以在这里使用head()方法:
sorted_column['Height'].head(5)
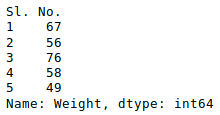
newData['Weight'].head()
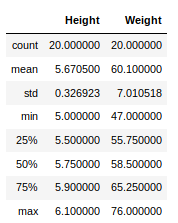
现在,假设我们的数据主要是数字。我们可以得到统计信息,如平均值,最大值,最小值等。使用describe()方法对数据帧进行处理,如下所示:
newData.describe()
newData['Weight'].mean()
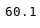
也可以使用相应的方法来计算其他统计信息。与Excel一样,也可以应用公式并创建计算列,如下所示:
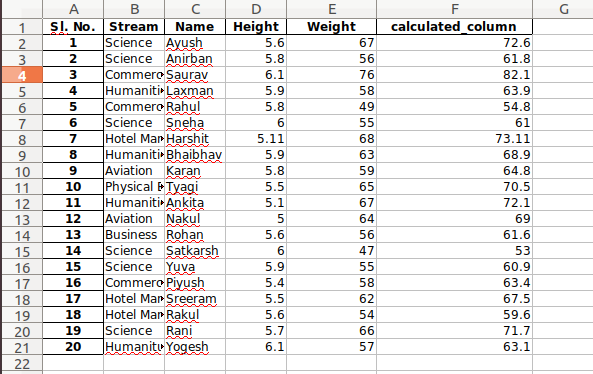
newData['calculated_column'] =
newData[“Height”] + newData[“Weight”]
newData['calculated_column'].head()
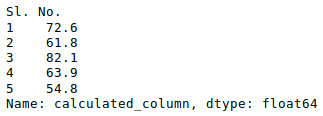
对数据框中的数据进行操作后,我们可以使用to_excel方法将数据导出回Excel文件。为此,我们需要指定一个输出excel文件,其中要写入转换后的数据,如下所示:
newData.to_excel('Output File.xlsx')
原文地址:https://blog.csdn.net/qq_42034590/article/details/131085170
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_12253.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!




