本文介绍: 一、Redis为什么快?二、Redis合适的应用场景 三、Redis为什么6.0之前不支持多线程 四、Redis为什么6.0之后引入多线程 五、Redis有哪些高级功能 六、为什么需要使用Redis 七、Redis的事务 八、Redis的过期策略以及内存淘汰机制 九、什么是缓存穿透?如何避免? 十、什么是缓存雪崩?如何避免? 十一、Redis如何设计分布式锁 十二、什么是bigkey?会有什么影响? 十三、Redis如何解决key冲突 十四、怎么提高换成命中率 十五、Redis持久化方式有哪些方式?
一、Redis为什么快?
1、纯内存访问
2、单线程,避免上下文切换
3、渐进式ReHash、缓存时间戳
(1)渐进式ReHash:
哈希表相当于一个数组,数组的每个元素称为一个哈系桶,每个哈系桶中保存了键值对的数据。


(2)缓存时间戳:
二、Redis合适的应用场景
常用基本数据类型(5种)
1、字符串(String)
(1)缓存
(2)计数器
(3)分布式会话(共享Session)
2、哈希(Hash)
3、列表(list)
(1)消息队列
(2)文章列表

4、集合(set)
(1)标签(tag)
(2)随机数(抽奖活动)
(3)社交图谱
5、有序集合(ZSET)
(1)排行榜
Redis高级数据结构
6、Bitmaps

(1)布隆过滤器

7、HyperLogLog
(1)UV

三、Redis为什么6.0之前不支持多线程
1、Redis的瓶颈不是CPU,受制于内存、网络
2、提高Redis性能,Pipeline(命令批量)
3、单线程,内部维护成本相对较低,不需要管理多线程安全
4、多线程(线程切换、加锁/解锁、导致死锁问题)
5、惰性Rehash(渐进式)减少阻塞
四、Redis为什么6.0之后引入多线程
本质:多线程任务 分摊到Redis 同步IO中,读写负载。
五、Redis有哪些高级功能
(1)慢查询
(2)Pipeline

(3)watch命令:
(4)Redis+Lua语言实现限流

(5)分布式锁
锁的过期时间不好计算

解决方案:分布式锁加入看门狗
(6)高并发高可用


(7)哨兵:Redis Sentinel
主从复制的问题
六、为什么需要使用Redis
1、高性能
2、高并发

七、Redis的事务

八、Redis的过期策略以及内存淘汰机制
1、内存淘汰机制
2、过期策略
3、缓存淘汰算法
九、什么是缓存穿透?如何避免?
布隆过滤器的应用:


十、什么是缓存雪崩?如何避免?
原因:
1、Redis失效、宕机(故障)
2、Redis大量key的ttl过期

十一、Redis如何设计分布式锁
1、概念
2、问题
十二、什么是bigkey?会有什么影响?
1、概念:
2、字符串类型:
3、非字符串类型:
4、危害:
5、解决方案:value拆分
十三、Redis如何解决key冲突
1、业务隔离
2、key的设计
3、分布式锁
4、时间戳
十四、怎么提高换成命中率
1、提前加载
2、增加缓存的存储空间,增加缓存的数据
3、调整缓存的存储类型
4、调整缓存的存储类型
十五、Redis持久化方式有哪些方式?有什么区别?
1、持久化:
2、RDB(Redis DataBse):
3、AOF:
4、生产环境中一般采用混合两者的方式

十六、为什么Redis需要把所有数据放到内存中?
1、内存访问与磁盘访问的差距:

2、Redis通过异步,持久化将数据写入磁盘
3、随着技术的发展,硬件上来说内存也越来越便宜了
4、默认情况下,哪怕Redis内存不够了,也不会发生宕机,而是只可读不能写(Noeviction策略)
5、通过内存淘汰策略,确保整体服务正常运行
十七、如何保证缓存与数据库双写一致性?
1、新增数据类
2、更新缓存类
(1)先更新缓存,在更新DB(一般不考虑)
(2)先更新DB,在更新缓存(一般不考虑)
3、删除缓存
(3)先删除缓存,后更新DB
问题:
解决方案:
(4)先更新DB,后删除缓存
4、如何选择

伪代码实现延迟双删:
十八、Redis集群方案
1、分布式解决方案 :Redis Cluster
方案:
(1)客户端分区:
(2)代理方案:
2、虚拟槽分区(0~16383)
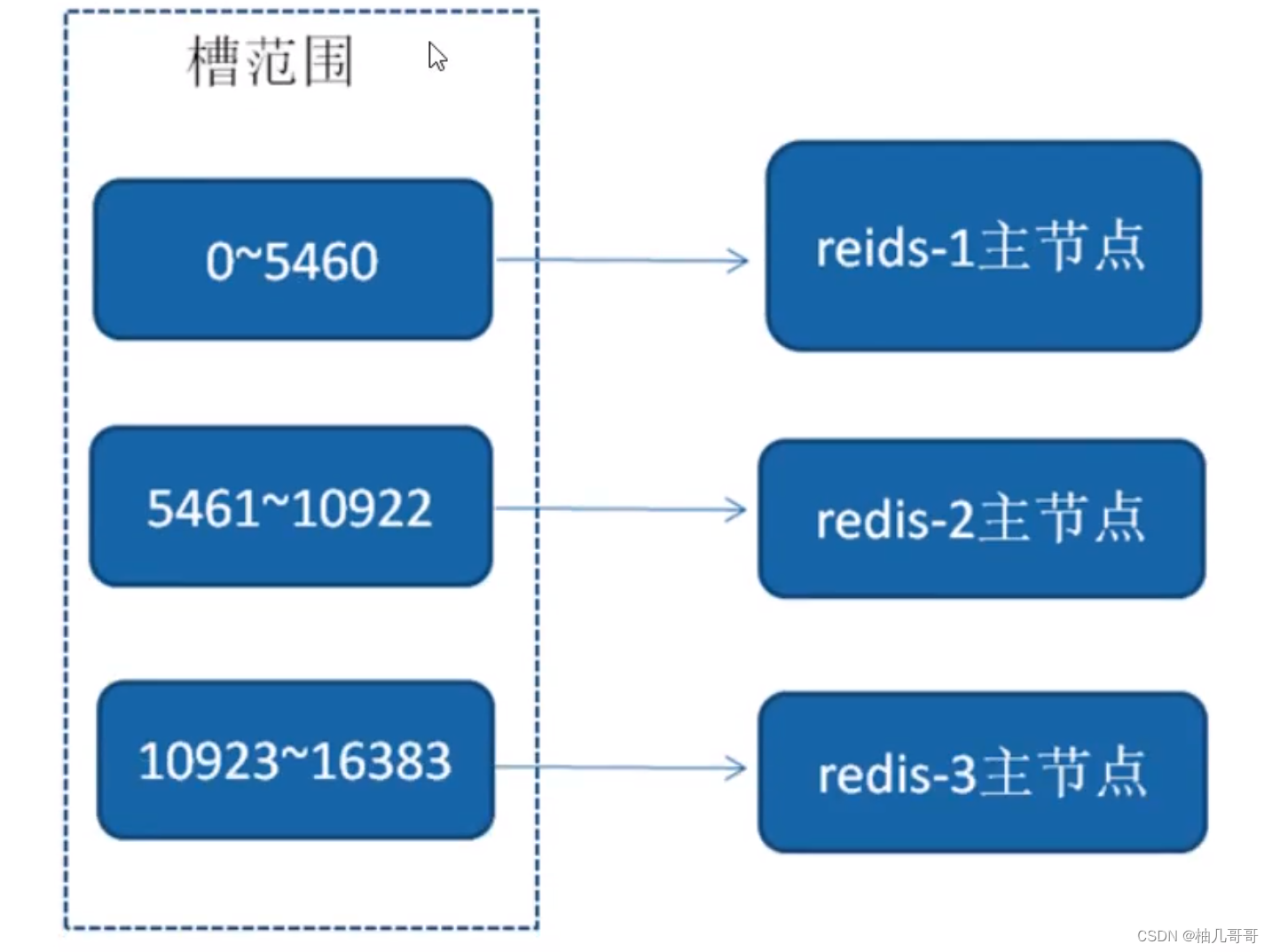
3、集群功能限制
4、搭建集群
十九、Redis集群方案什么情况下会导致整个集群不可用?
集群不可用判定:
二十、Redis集群会有写操作丢失吗?为什么?
二十一、Redis常见性能问题和解决方案
1、持久化 性能问题
2、数据比较重要,开启AOF。策略最好配置每秒同步。
3、主从复制 流畅,建议同一个局域网内操作,负责网络开销过大
4、尽量避免主库压力过大,增加从库
5、主从复制 尽量不要使用网状结构、线性结构
二十二、热点数据和冷数据
1、热数据
2、冷数据
二十三、什么情况下可能会导致Redis阻塞
1、客户端阻塞
2、BIGkey删除
3、清空库
4、AOF日志同步写,记录AOF日志
5、从库 加载RDB文件
6、Redis尽量部署在独立的服务器中
二十四、线上Redis响应慢处理思路
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。




