1. 业务场景
延时队列场景在我们日常业务开发中经常遇到,它是一种特殊类型的消息队列,它允许把消息发送到队列中,但不立即投递给消费者,而是在一定时间后再将消息投递给消费者。延迟队列的常见使用场景有以下几种:
- 在各种购物平台上下单,订单超过30分钟未支付,自动关闭。
- 订单完成后, 如果用户一直未评价, 5天后自动好评。
- 会员到期前15天, 到期前3天分别发送短信提醒。
- 当订单一直处于未支付状态时,如何及时的关闭订单,并退还库存?
- 如何定期检查处于退款状态的订单是否已经退款成功?
2. Redis延迟队列实现原理
- 基于消息的延迟:指为每条消息设置不同的延迟时间,那么每当队列中有新消息进入的时候就会重新根据延迟时间排序,或者定义时间轮,新消息落在指定位置;
- 基于队列的延迟: 设置不同延迟级别的队列,比如5s、1min、30mins、1h等,每个队列中消息的延迟时间都是相同的。
基于第一种不少组件都有实现方案,比如redis的sortset间接实现,kafka内部时间轮,rabbitMQ可安装插件实现。第一种实时性高,不过主观看会比较依赖组件本身,但自己实现就得考虑持久化、高可用等问题,建议直接使用组件本身;第二种方案可以基于组件去实现,通用性会高点,不过实时性不高,更适合用于重试业务场景。当然Redis本身并不支持延迟队列,所以我们只是实现一个比较简单的延迟队列,而且Redis不太适合大量消息堆积,所以只适合比较简单的场景,然假如我们对消息的实时性以及可靠性要求非常高,可能就需要使用MQ或kafka来实现了。
消息延迟流程图如下:
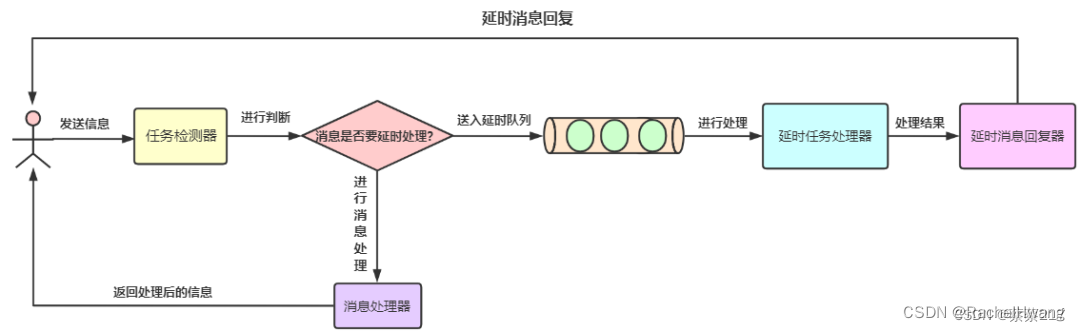
Redis延迟队列可以通过 zset 来实现,因为 zset 中有一个 score,我们可以把时间作为 score,将 value 存到 redis 中,然后通过轮询的方式,去不断的读取消息出来,整体思路为:
zadd命令
使用方式:ZADD key score member [[score member][score member] …]
将一个或多个 member 元素及其 score 值加入到有序集 key 当中。如果 key 不存在,则创建一个空的有序集并执行 ZADD 操作。如果某个 member 已经是有序集的成员,那么更新这个 member 的 score 值,并通过重新插入这个 member 元素,来保证该 member 在正确的位置上。score 值可以是整数值或双精度浮点数。
ZRANGEBYSCORE命令
使用方式:ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
- 返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。有序集成员按 score 值递增(从小到大)次序排列。
- 具有相同 score 值的成员按字典序来排列
- 可选的 LIMIT 参数指定返回结果的数量及区间(就像SQL中的 SELECT LIMIT offset, count ),注意当 offset 很大时,定位 offset 的操作可能需要遍历整个有序集,此过程最坏复杂度为 O(N) 时间。
- 可选的 WITHSCORES 参数决定结果集是单单返回有序集的成员,还是将有序集成员及其 score 值一起返回。
ZREM命令
使用方式:ZREM key member [member …]
移除有序集 key 中的一个或多个成员,不存在的成员将被忽略。
当 key 存在但不是有序集类型时,返回一个错误。
3. 基于springboot实现redis延迟队列
3.1 引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<version>${version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>${version}</version>
</dependency>
3.2 redis基础方法
定义RedisService基础服务方法,本次案例只涉及到以下三个基础方法:
/**
* 添加 ZSet 元素
*
* @param key
* @param value
* @param score
*/
@Override
public boolean add(String key, Object value, double score) {
return redisTemplate.opsForZSet().add(key, value, score);
}
/**
* 返回 分数范围内 指定 count 数量的元素集合, 并且从 offset 下标开始(从小到大,不带分数的集合)
*
* @param key
* @param min
* @param max
* @param offset 从指定下标开始
* @param count 输出指定元素数量
* @return
*/
@Override
public Set<Object> rangeByScore(String key, double min, double max, long offset, long count) {
return redisTemplate.opsForZSet().rangeByScore(key, min, max, offset, count);
}
/**
* Zset 删除一个或多个元素
*
* @param key
* @param values
* @return
*/
@Override
public Long removeZset(String key, Object... values) {
return redisTemplate.opsForZSet().remove(key, values);
}
3.3 定义Spring消息事件推送
@Getter
@ToString
public class DelayMsg extends ApplicationEvent {
private String msg;
private String topic;
public DelayMsg(Object source, String msg, String topic) {
super(source);
this.msg = msg;
this.topic = topic;
}
}
3.4 消息获取
/**
* 从zset中取出score小于当前时间戳的数据
*
* @param key
* @return
*/
public String getDelayOne(String key) {
//先查后删,一次拿3个做备选,这样抢占到的概率就会高一些
Set<Object> sets = redisService.rangeByScore(key, 0, System.currentTimeMillis(), 0, 3);
if (CollectionUtils.isEmpty(sets)) {
return null;
}
for (Object val : sets) {
if (1L.equals(redisService.removeZset(key, val))) {
// 删除成功,表示抢占到
return val.toString();
}
}
return null;
}
这里每次查询时取了三个数据,然后遍历获取到的数据,依次尝试去删除,若删除成功,则表示当前实例抢占到了这个消息
如果我们按照正常的实现流程,每次从zset中取一个,但是无法保证这个时候就只有我一个人拿到了这个数据,在多实例的场景下,可能存在多个实例同时拿到了它,那么如何才能表示只有一个实例抢占到呢?
借助redis的单线程机制,只可能有一个实例会删除成功,所以拿到并删除成功的那个小伙伴,就是最终的幸运儿;
因此实现细节就是先查,后删,若删除成功,表示获取成功;否则表示被其他的实例捷足先登。
从上面的分析可以看出,如果我一次只拿一个,那么我抢占到的几率并不太大,特别是当实例比较多时,可能会做多次的无效操作;为了减少这个可能性,所以我一次多拿几个做备选,这样抢占到的概率就会高一些,至于为什么是3,这个就看实际的实例与定时任务的执行间隔了。
上面定义了如何获取延迟队列中已到期的消息,接下来需要定时轮训获取消息:
/**
* 每5s定时轮训消息
*/
@Scheduled(fixedRate = 5000)
public void schedule() {
for (String specialTopic : topic) {
String msg = redisDelayQueue.getDelayOne(specialTopic);
logger.info("开始轮训获取消息 {}", msg);
if (StringUtil.isNotEmpty(msg)) {
//使用Spring推送事件处理
applicationContext.publishEvent(new DelayMsg(this, msg, specialTopic));
}
}
}
上面的定时任务,直接借助Spring的@Schedule来实现,遍历所有的topic,捞出数据之后,通过spring的 event/listener事件机制来实现消息处理的解耦
3.5 定义消费者注解和切面处理
@Target({ElementType.METHOD, ElementType.ANNOTATION_TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@EventListener
public @interface Consumer {
String topic();
}
注意这个注解上面还有 @EventListener,表明它可以监听的spring的事件
3.6 定义延时业务的切面处理
@Aspect
@Component
public class ConsumerAspect {
@Around("@annotation(consumer)")
public Object around(ProceedingJoinPoint joinPoint, Consumer consumer) throws Throwable {
Object[] args = joinPoint.getArgs();
boolean check = false;
for (Object obj : args) {
if (obj instanceof DelayMsg) {
check = consumer.topic().equals(((DelayMsg) obj).getTopic());
}
}
if (!check) {
// 不满足条件,直接忽略
return null;
}
// topic匹配成功,执行
return joinPoint.proceed();
}
}
3.7 消息监听
//使用自定义的consumer注解监听topic延迟队列
@Consumer(topic = RedisKeyConstant.DELAY_QUEUE)
public void consumer(DelayMsg delayMsg) {
logger.info("预约单延时确认: " + delayMsg.getMsg() + " at:" + System.currentTimeMillis());
//延迟业务具体实现
//...
//...
}
3.8 业务facade层调用延迟处理
经过以上的延迟队列封装处理,在facade层,也就是我们的业务中就可以直接调用:
@Autowired
private DelayListWrapper delayListWrapper;
...
delayListWrapper.publish(RedisKeyConstant.DELAY_QUEUE, xxxId, xxx);
4 总结
本文以redis的zset来实现延时队列,并基于SpringBoot实现了延迟队列的推送和消费。
原文地址:https://blog.csdn.net/qq_38658567/article/details/132214969
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_12433.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!