内容提要:
如果说,爬取网页数据的时候,我们使用了异步,那么将数据放入redis里面,其实也需要进行异步;当然,如果使用多线程或者redis线程池技术也是可以的,但那会造成冗余;
因此,在测试完多线程redis搭配异步爬虫的时候,我发现效率直接在redis这里被无限拉低下来!
因此:
最终的redis库,我选择aioredis(redis的异步库);
效果: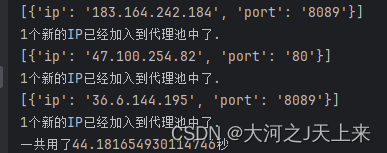
(对上万个ip进行了检测,最终只得到这么几个….)
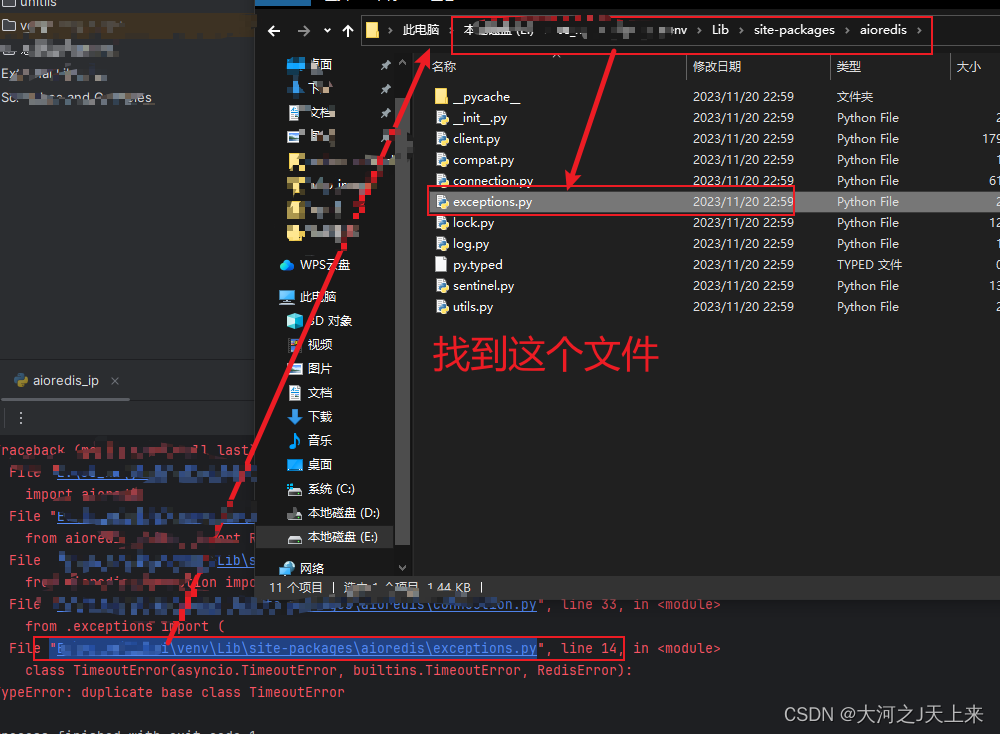
完成aioredis的时候,肯定会遇到一个bug,我先写在这里;当你们遇到的时候,再回头来看,没遇到前先跳过:
aioredis报错: duplicate base class TimeoutError

解决办法:
1.
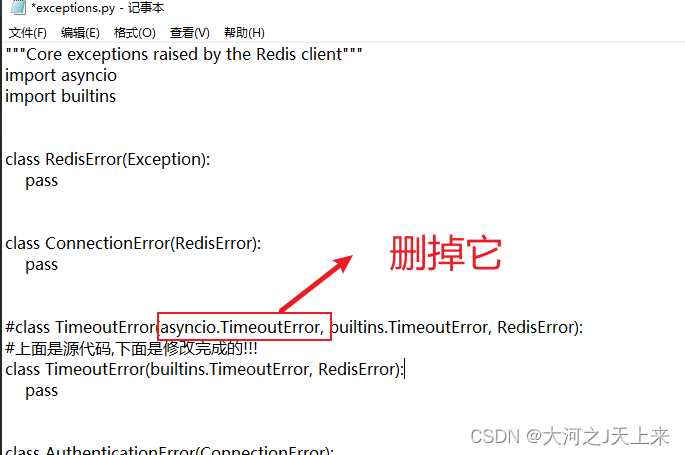
回归正题:
当我们已经完成了网页的爬取和解析并验证完ip之后,会得到了X个有效ip;那么就需要将他存储起来:
aioredis相关代码如下:
import aioredis
# 配置连接 Redis 服务的地址和端口以及数据库索引
redis_host = "localhost"
redis_port = 6379
redis_db = 0
redis_url = f"redis://{redis_host}:{redis_port}/{redis_db}"
# 创建 Redis 连接的异步函数
async def create_redis():
# aioredis 2.0+ 直接连接
return aioredis.from_url(redis_url, encoding="utf-8", decode_responses=True)
# 异步将多个有效代理添加到 Redis 的集合中
async def add_valid_proxies_to_redis(proxies):
redis = await create_redis()
async with redis.client() as conn:
new_proxies_added=0 #sadd对于已经存在的ip是不会放进去的!所以如果需要验证,就需要计数
for proxy in proxies:
proxy_str = f"{proxy['ip']}:{proxy['port']}"
added_count = await conn.sadd("valid_proxies", proxy_str) # 如果被放进去,就会进行修正添加
new_proxies_added += added_count
# 打印实际添加到集合中的新代理数量
print(f"{new_proxies_added}个新的IP实际加入到代理池中了.")
# 异步地从 Redis 随机获取一个有效的代理
async def get_random_proxy():
redis = await create_redis()
async with redis.client() as conn:
random_proxy = await conn.srandmember("valid_proxies")
return random_proxyimport logging
import asyncio
import aiohttp
import time
from bs4 import BeautifulSoup
from db.aioredis_ip import add_valid_proxies_to_redis #引入ip代理添加函数
logger = logging.getLogger(__name__)
logging.basicConfig(level=logging.INFO)
#请求头
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36',
}
# 异步获取URL的函数
async def fetch_url(session, url):
try:
async with session.get(url, timeout=3,headers=headers) as response:
return await response.text()
except aiohttp.ClientError as e:
logger.exception("爬取相关url出错: %s", url)
async def parse_html(html):
'''
解析代码,如果标题包含'89免费代理',
如果包含"快代理"--->就是快代理
:param html:
:return:
'''
soup = BeautifulSoup(html, 'html.parser')
title = soup.find('title')
if '89免费代理' in title.getText():
table = soup.find('table', class_='layui-table')
tbody = table.find('tbody')
proxy_list = []
rows = tbody.find_all('tr')
for row in rows:
proxy = {}
cells = row.find_all('td')
proxy["ip"] = cells[0].text.strip()
proxy["port"] = cells[1].text.strip()
proxy_list.append(proxy)
return proxy_list
async def check_ip(session, proxy):
"""...略去其它注释,同时函数的docstring也要更新..."""
proxy_url = f"http://{proxy['ip']}:{proxy['port']}"
try:
async with session.get(url="http://httpbin.org/ip", timeout=1.5, proxy=proxy_url) as response:
# 返回原始代理信息和有效性状态
return proxy, response.status == 200
except (aiohttp.ClientError, asyncio.TimeoutError):
# 返回原始代理信息和无效状态
return proxy, False
async def check_ip_main(proxies):
"""
检查IP有效性并返回所有有效的IP列表
"""
async with aiohttp.ClientSession() as session:
tasks = [asyncio.create_task(check_ip(session, proxy)) for proxy in proxies]
valid_proxies = [] # 初始化一个空列表来存放有效的代理
for task in asyncio.as_completed(tasks):
proxy, is_valid = await task # 这里我们期望 check_ip 也返回对应的 proxy 信息
if is_valid:
#当返回来是True的时候,他就会加入到valid_proxies里面;
valid_proxies.append(proxy)
return valid_proxies
# 异步操作,在其中打开会话和调用fetch任务
async def main(urls):
async with aiohttp.ClientSession() as session:
tasks = [fetch_url(session, url) for url in urls]
for future in asyncio.as_completed(tasks):
html = await future
if html:
#对html进行解析,获取iplist=[]
proxys = await parse_html(html)
# 检查ip的有效性,这时候继续协程
valid_proxies= await check_ip_main(proxys)
if len(valid_proxies)>0:
#如果在redis里面进行比较>0,会突然增加redis通信的次数造成不必要操作;
# python内存处理比较,会更快一些;
#放入到redis库中
print(valid_proxies)
await add_valid_proxies_to_redis(valid_proxies) # 将有效代理存储到Redis
# URL 列表
urls = ["https://www.89ip.cn/index_{}.html".format(i+1) for i in range(25)]
# 运行协程
stat =time.time()
asyncio.run(main(urls))
end =time.time()
print(f'一共用了{(end-stat)}秒')原文地址:https://blog.csdn.net/m0_56758840/article/details/134521693
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_12437.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。