大数据分析与应用实验任务九
实验目的
实验任务
进入pyspark实验环境,打开命令行窗口,输入pyspark,完成下列任务:
在实验环境中自行选择路径新建以自己姓名拼音命名的文件夹,后续代码中涉及的文件请保存到该文件夹下(需要时文件夹中可以创建新的文件夹)。
一、参考书中相应代码,练习RDD持久性、分区及写入文件(p64、67、80页相应代码)。
1.持久化
迭代计算经常需要多次重复使用同一组数据。下面就是多次计算同一个RDD的例子。
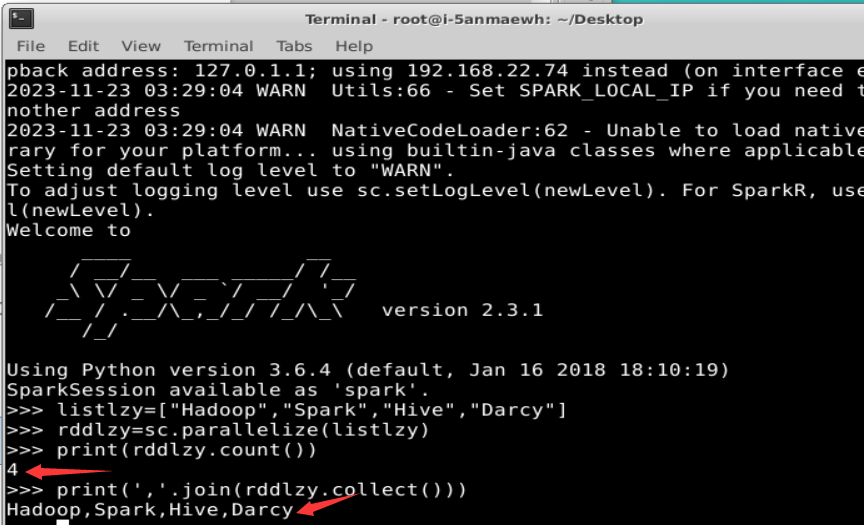
一般而言,使用cache()方法时,会调用persist(MEMORY_ONLY)。针对上面的实例,增加持久化语句以后的执行过程如下:
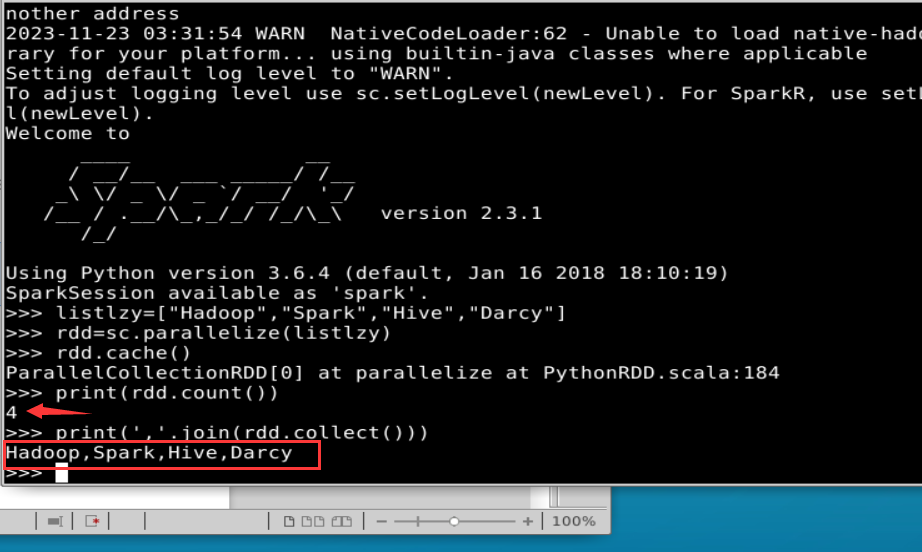
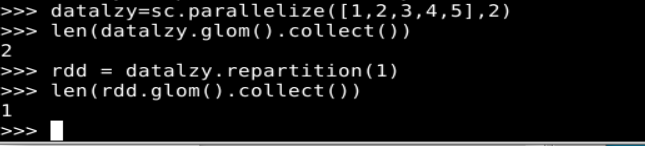
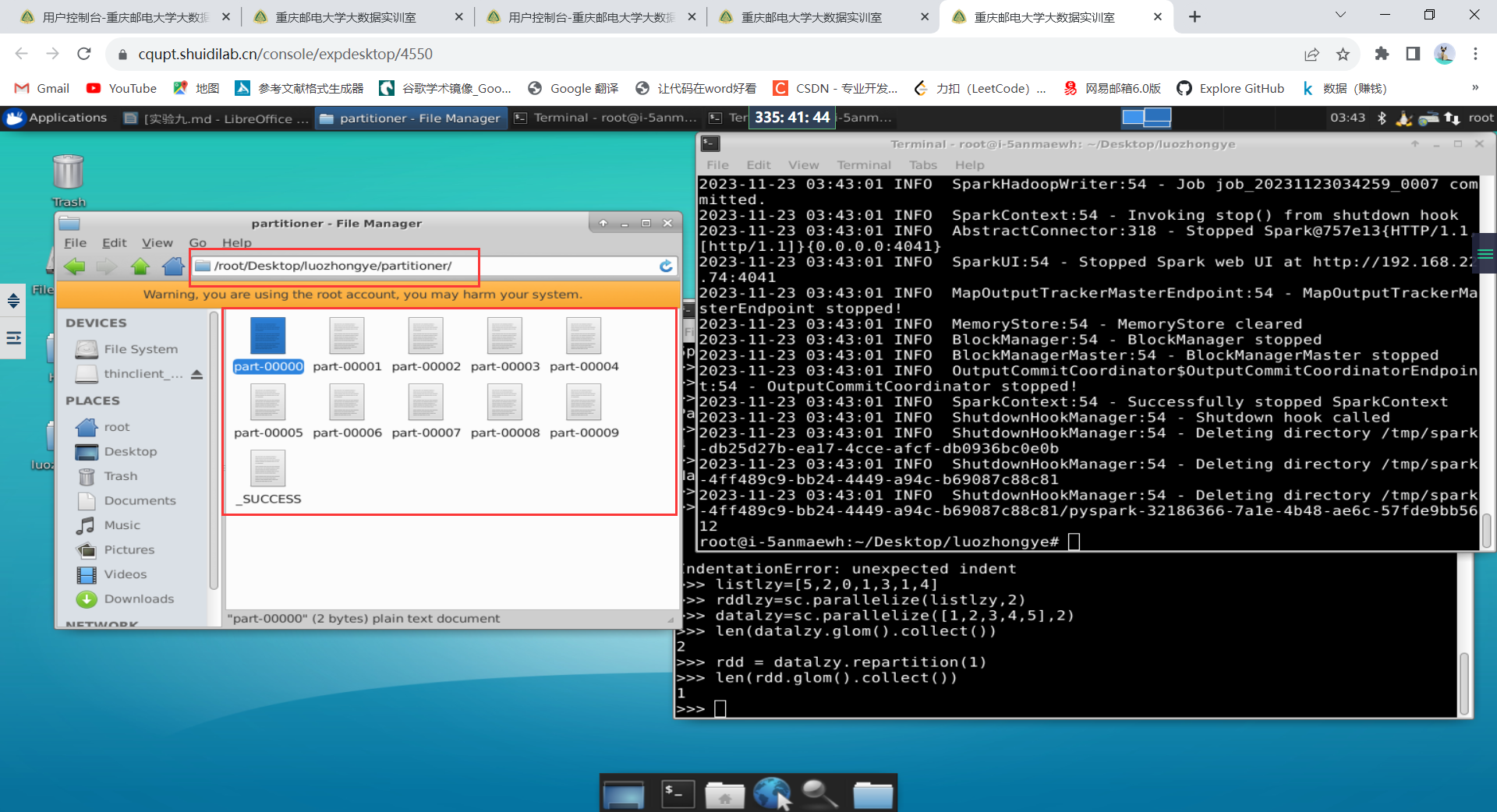
2.分区

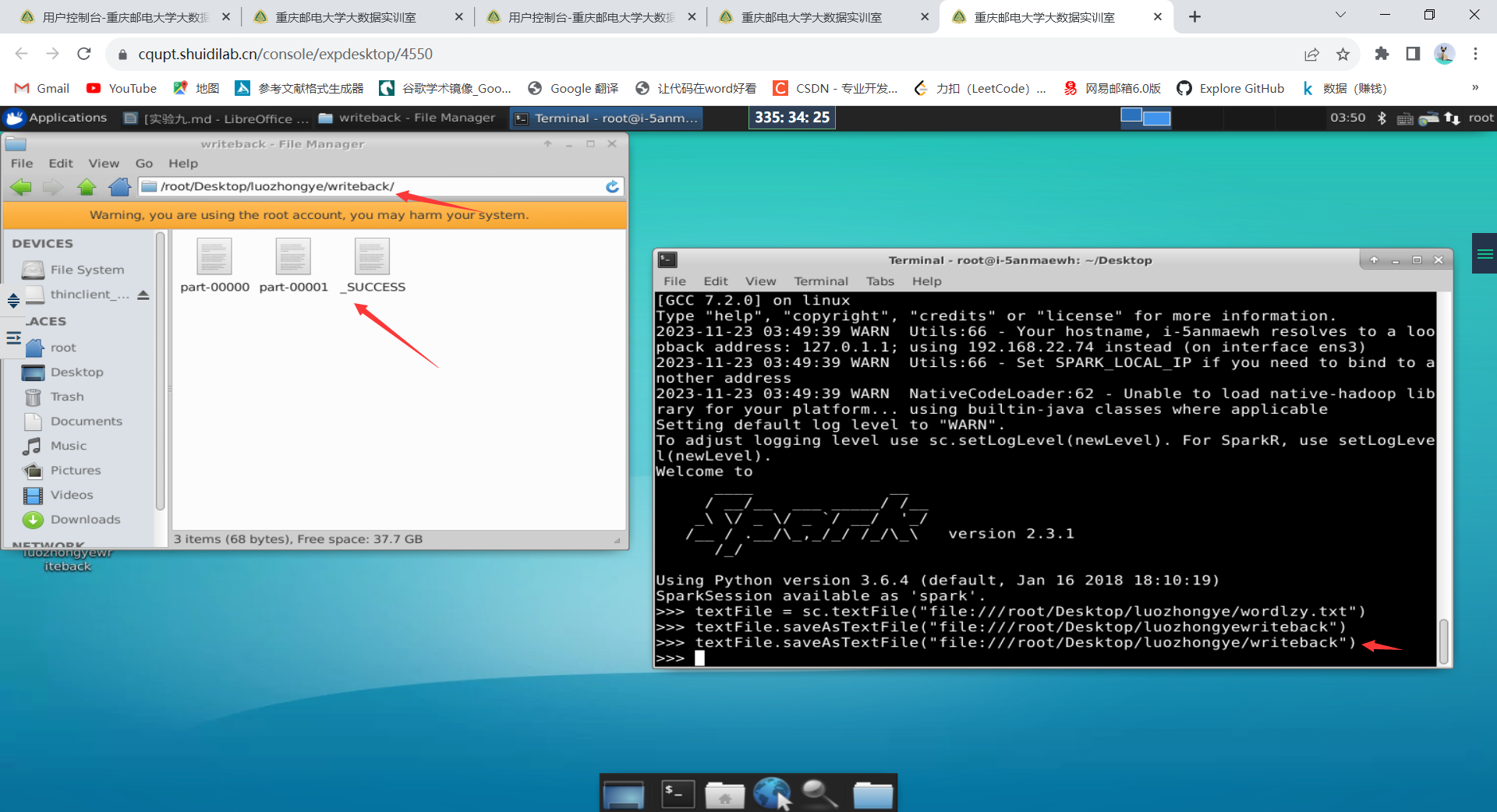
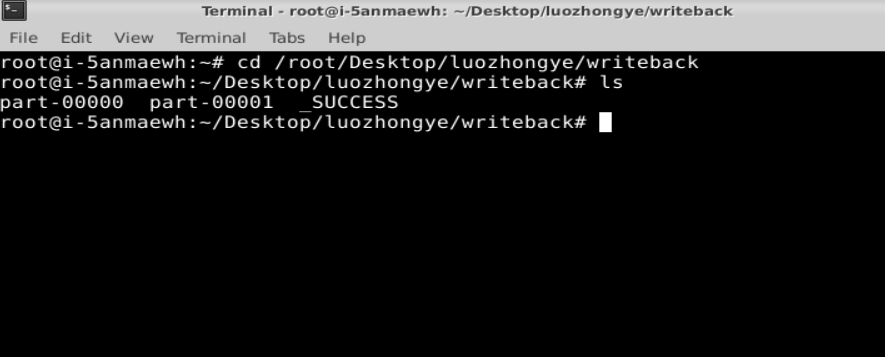
3.文件数据写入

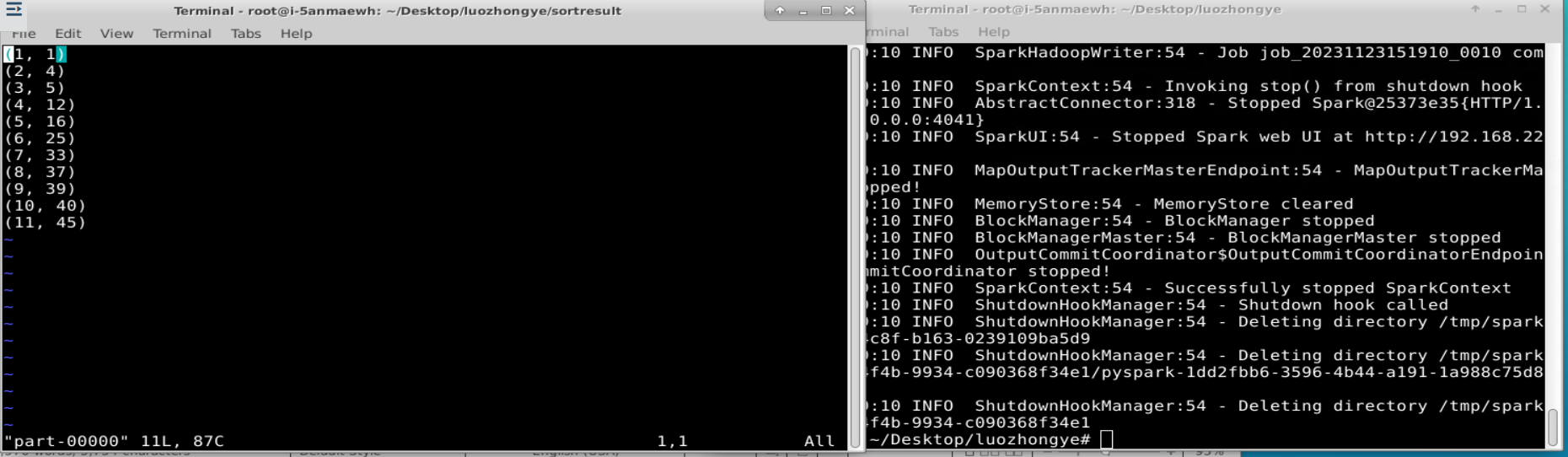
二、逐行理解并运行4.4.2实例“文件排序”。
三、完成p96实验内容3,即“编写独立应用程序实现求平均值问题”,注意每位同学自己修改题目中的数据。

实验心得
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。