全新Self-RAG框架亮相,自适应检索增强助力超越ChatGPT与Llama2,提升事实性与引用准确性
1. 基本思想
大型语言模型(LLMs)具有出色的能力,但由于完全依赖其内部的参数化知识,它们经常产生包含事实错误的回答,尤其在长尾知识中。
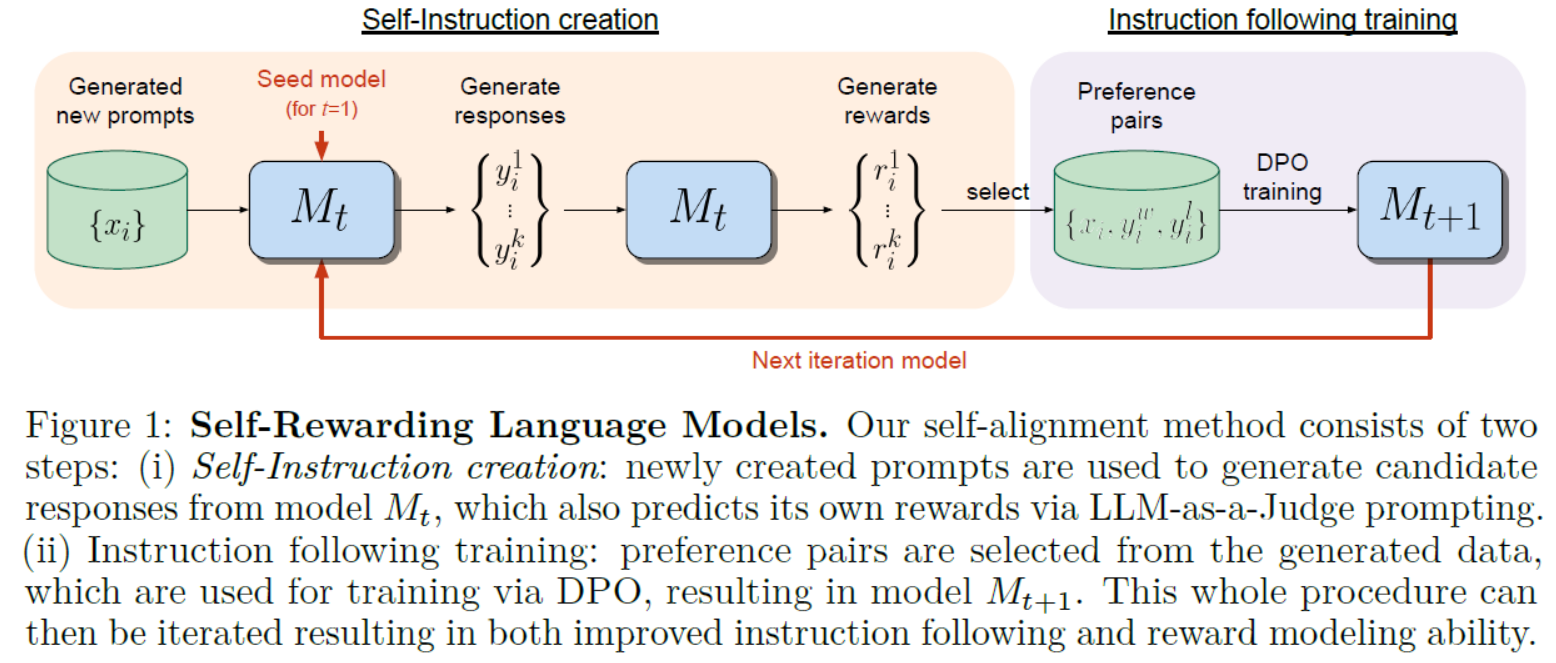
为了进一步改进,作者提出了自反思检索增强生成(Self-RAG, Self-Reflective Retrieval-Augmented Generation)。这是一个新框架,它不仅可以根据需要自适应地检索段落(即:模型可以判断是否有必要进行检索增强),还引入了名为反思令牌(reflection tokens)的特殊令牌,使 LM 在推理阶段可控。
实验结果显示,Self-RAG 在多种任务上,如开放领域的问答、推理和事实验证,均表现得比现有的 LLMs(如 ChatGPT)和检索增强模型(如检索增强的 Llama2-chat)更好,特别是在事实性和引用准确性方面有显著提高。
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。