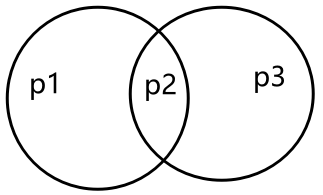
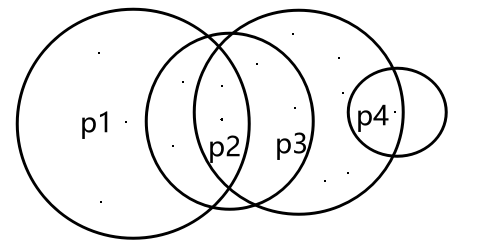
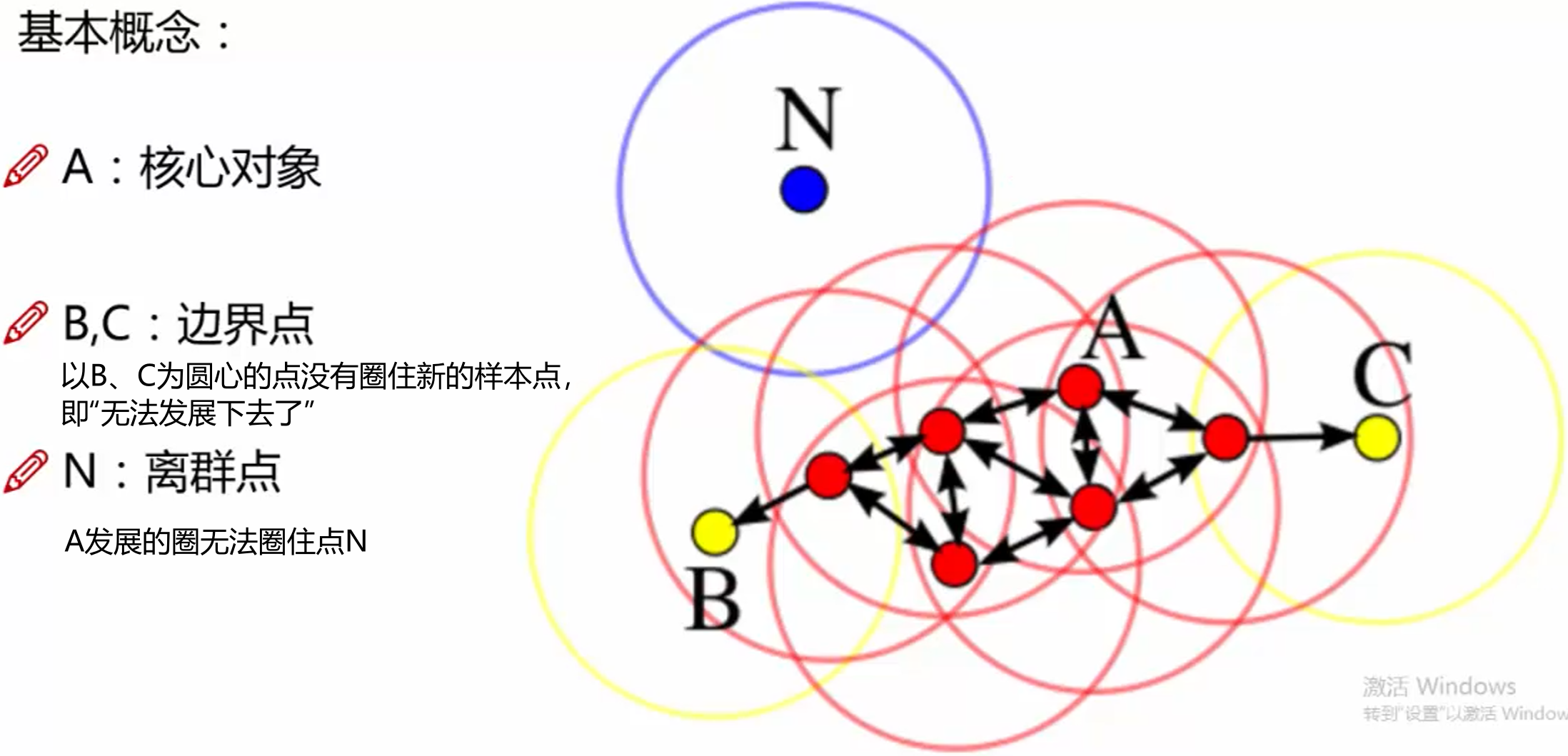
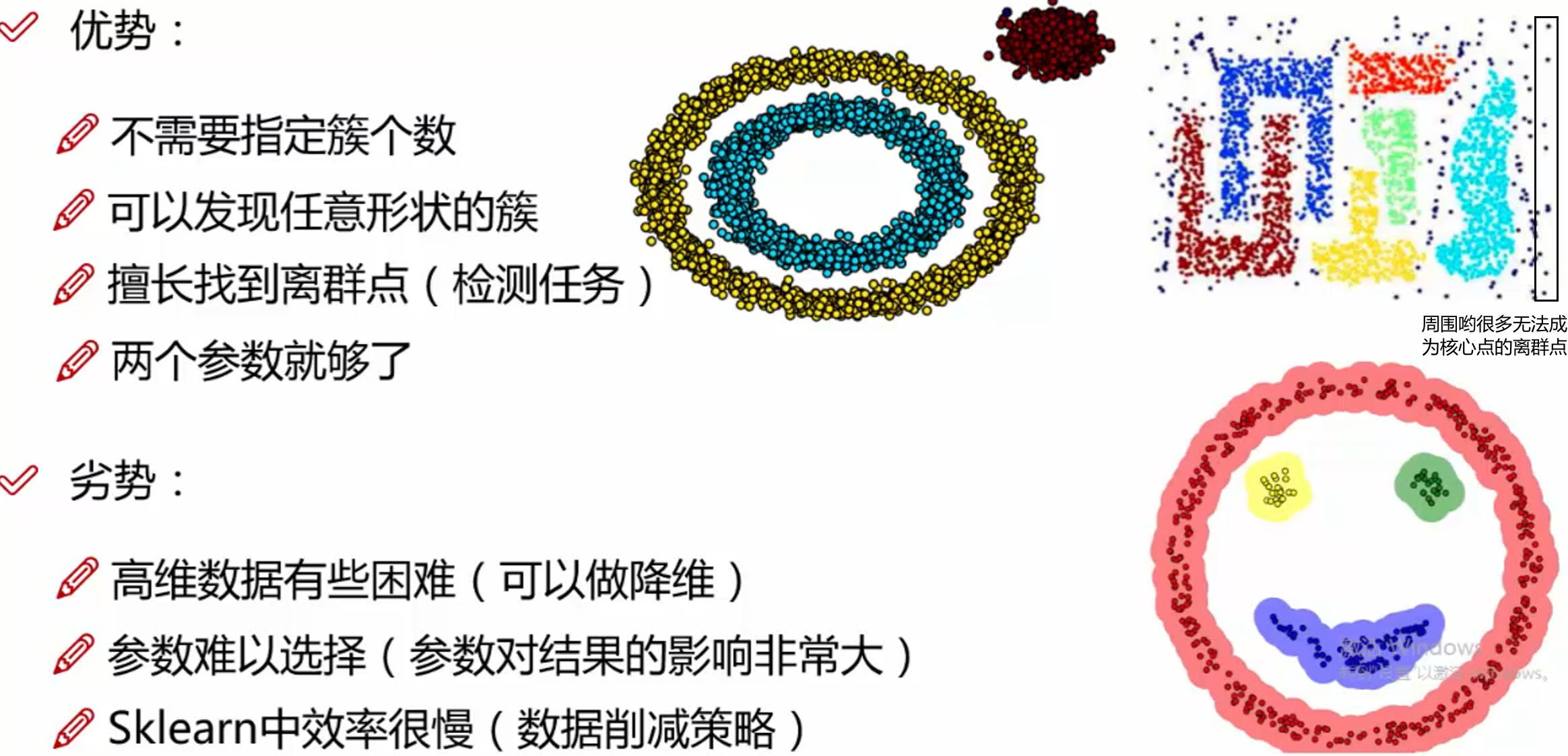
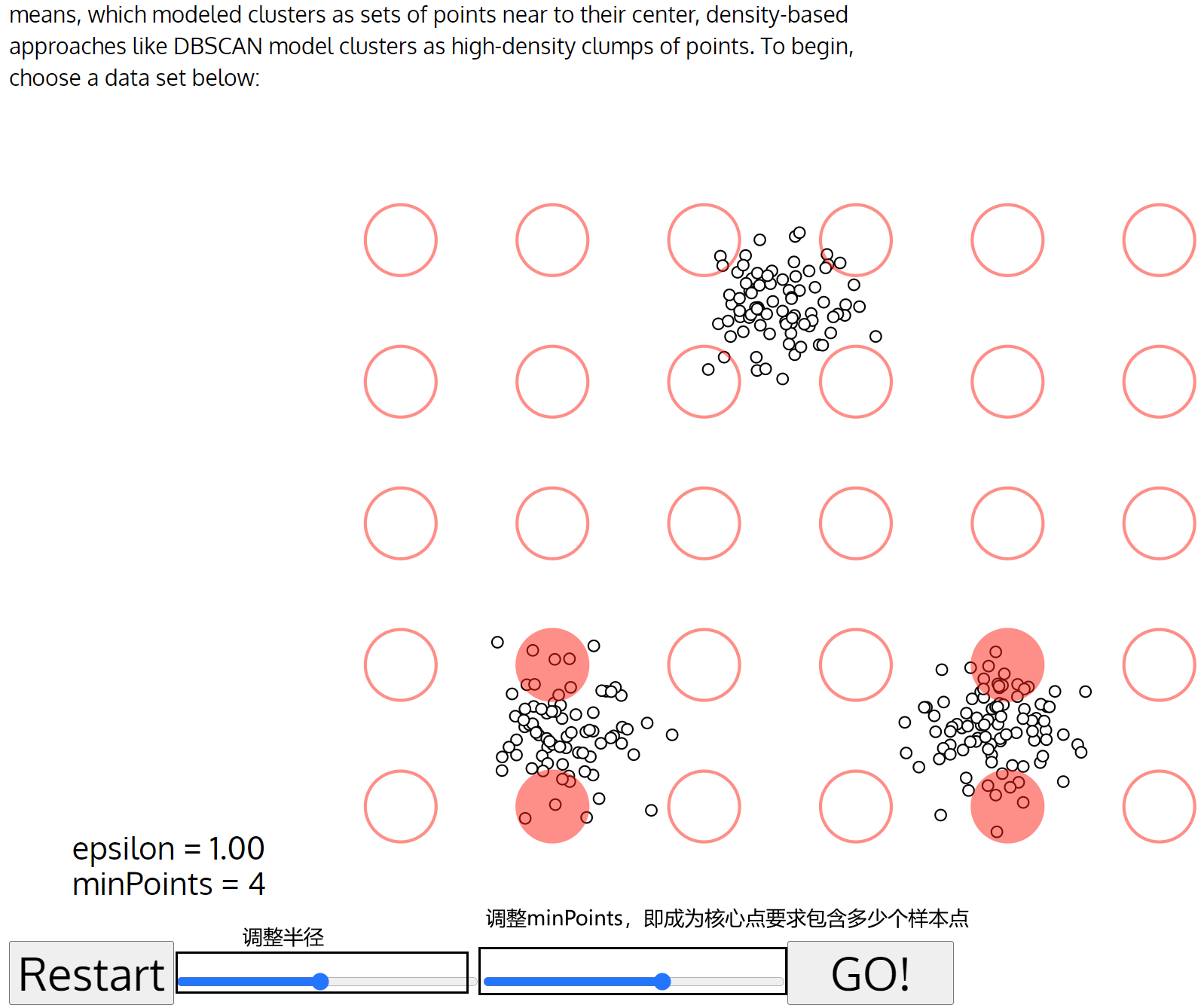
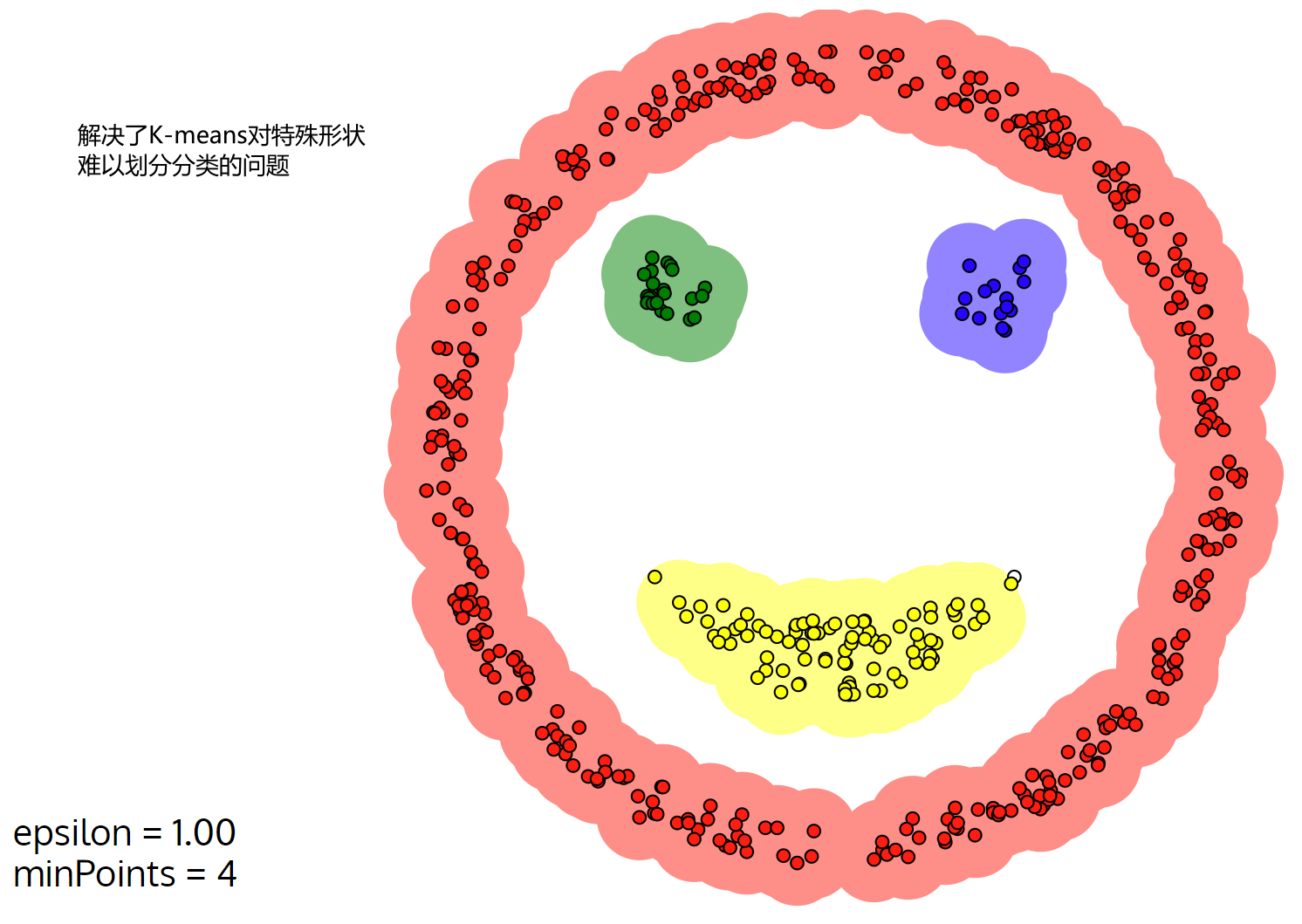
当前位置: 首页互联网正文 本文介绍: 机器学习:DBSCAN算法(效果比K-means好),擅长发现离群点 基本概念 核心对象:以点为圆心半径为r的圆,如果圈里面的样本点大于给定的阈值(minPts),那么这个点就叫做核心点 直接密度可达:点p在q为圆心的圆内 密度可达: p1与p2直接密度可达,p2与p3直接密度可达,所以p1与p3被称为密度可达 边界点: 以p1为核心点的圈含p2,p2自己为核心点也有对应圈,并且圈内有点p3,同样p3也有以p3为核心点的圈,并且有点p4,这说明点p1,p2,p3是可以发展下去的点(我认为可以理解成以之前圈住点为圆心画圈不断圈住新的点) 但是p4就不行了,因为以p4为核心点的圈内没有其他样本点或者说样本点的个数少于规定的阈值MinPts,没有继续“发展”下去 工作流程 算法 需要输入的数据 参数D:输入数据集 参数:指定半径 MinPts:密度阈值 如何选择参数,基本上都是不断尝试 优势和劣势 可视化展示 Visualizing DBSCAN Clustering Gaussian Mixture 如下图所示,调大半径epsilon之后,离群点就变小了 如果想用DESCAN算法找离群点,可以考虑将半径调小 Smiley Face Packed Circles 但对于这种密集区域此时,DBSCAN分类就不如K-means 半径小了,就出现分类很多的情况;半径大了,就出现分类只有一两个的情况,还不如直接K-means直接给定分类的类别 原文地址:https://blog.csdn.net/weixin_50917576/article/details/134651578 本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若转载,请注明出处:http://www.7code.cn/show_13247.html 如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除! 主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网显示所有内容声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。p核心点 代码007普通 打赏 收藏 海报 链接