一、介绍
HDFS (Hadoop Distributed File System)是 Hadoop 下的分布式文件系统,具有高容错、高吞吐量等特性,可以部署在低成本的硬件上。
二、HDFS设计原理
2.1 HDFS 架构
HDFS 遵循主/从架构,由单个 NameNode(NN) 和多个 DataNode(DN) 组成:
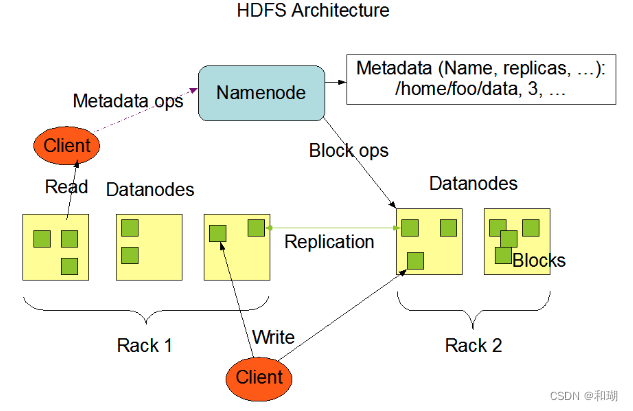
注:
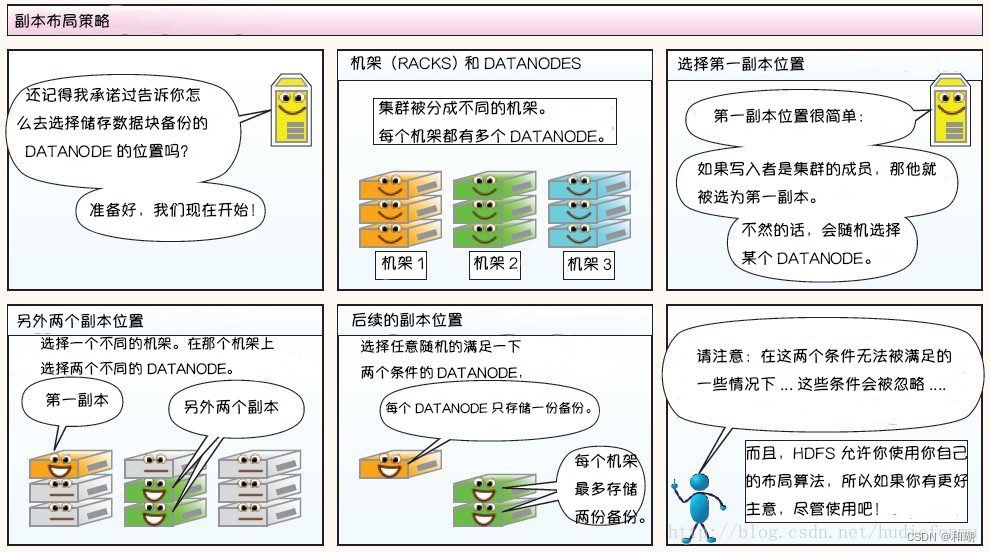
2.2 数据复制
为了保证容错性,HDFS 提供了数据复制机制。HDFS 将每一个文件存储为一系列block,每个块由多个副本来保证容错,块的大小和复制因子可以自行配置(默认情况下,块大小是 128M,默认复制因子是 3)
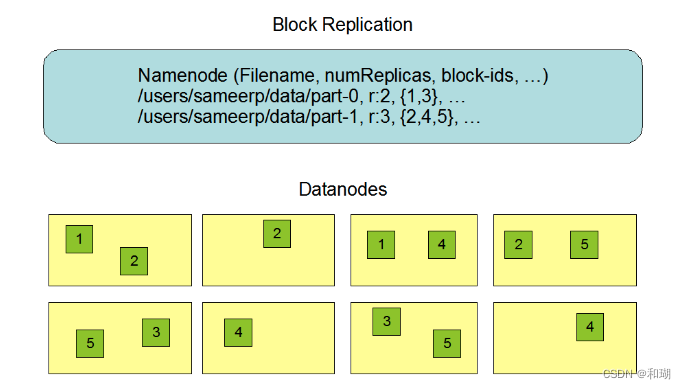
复制的实现原理
大型的 HDFS 实例在通常分布在多个机架的多台服务器上。在大多数情况下,同一机架中的服务器间的网络带宽大于不同机架中的服务器之间的带宽。因此 HDFS 采用机架感知副本放置策略,对于常见情况,当复制因子为 3 时,HDFS 的放置策略是:
- 在写入程序位于 datanode 上时,就优先将写入文件的一个副本放置在该 datanode 上,否则放在随机 datanode 上
- 之后在另一个远程机架上的任意一个节点上放置另一个副本
- 并在该机架上的另一个节点上放置最后一个副本
此策略可以减少机架间的写入流量,从而提高写入性能。
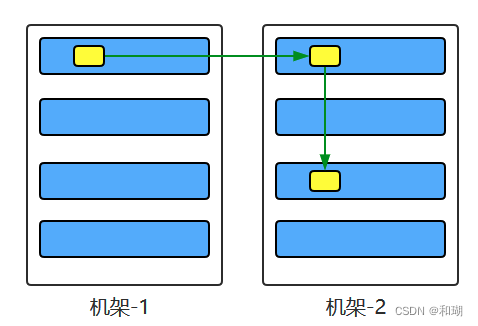
注意:同一个 dataNode 上不允许有同一个块的多个副本
三、HDFS的特点
- 优点
- 缺点
四、图解HDFS存储原理
1. 写过程
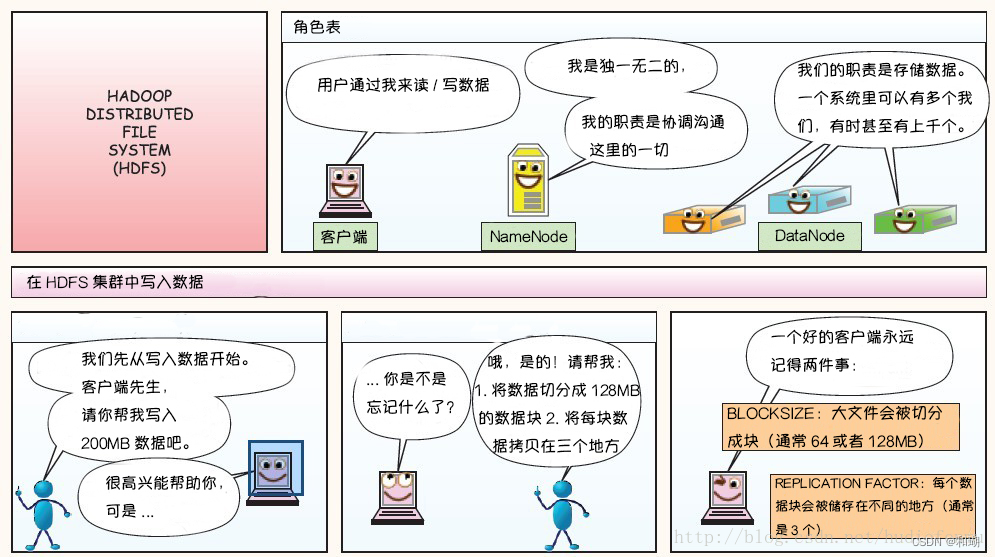
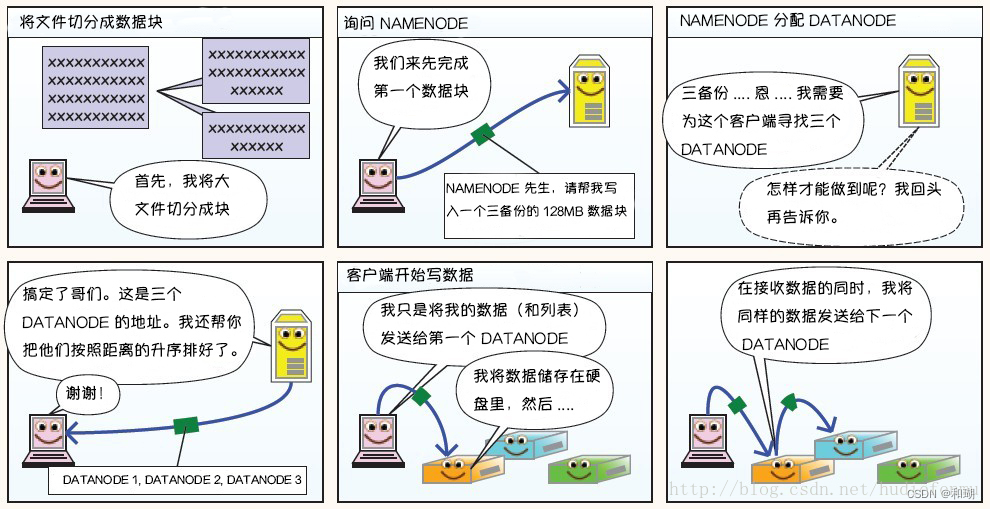
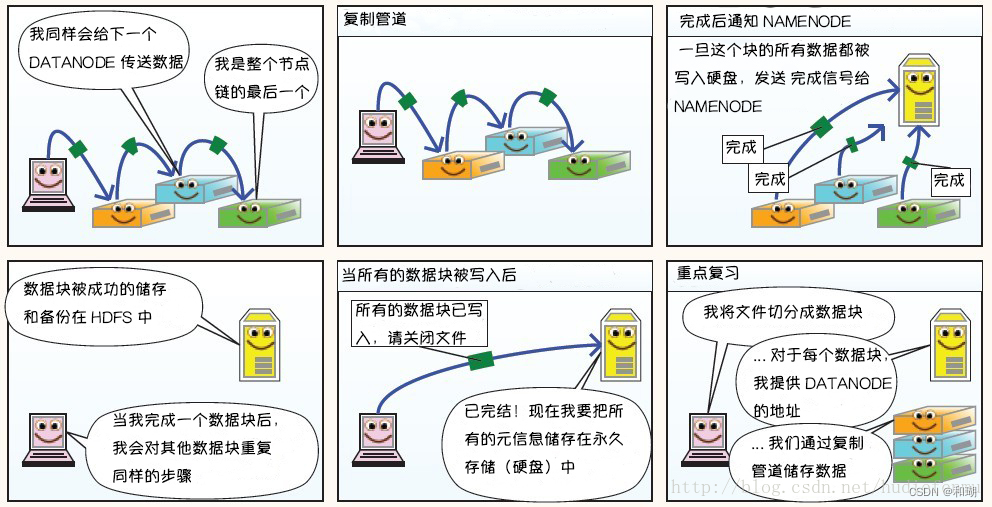
2. 读过程
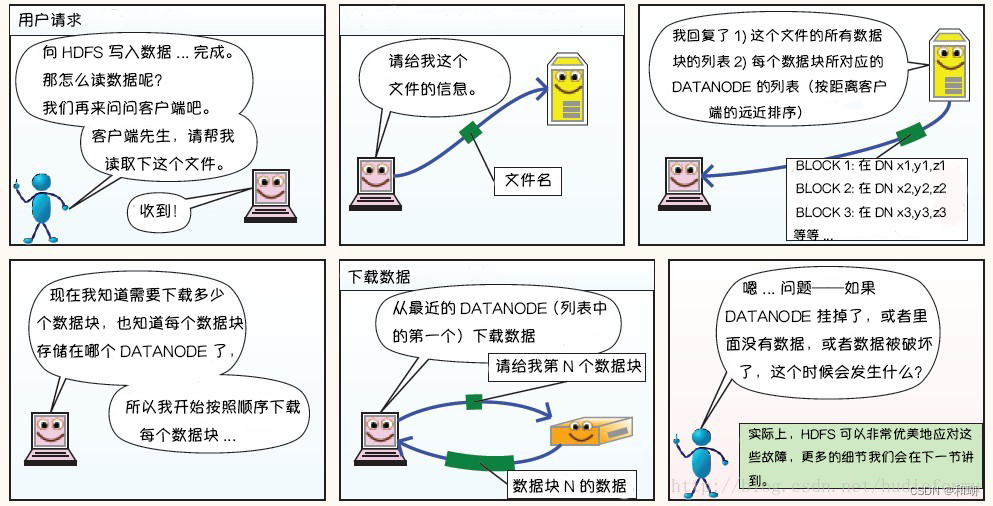
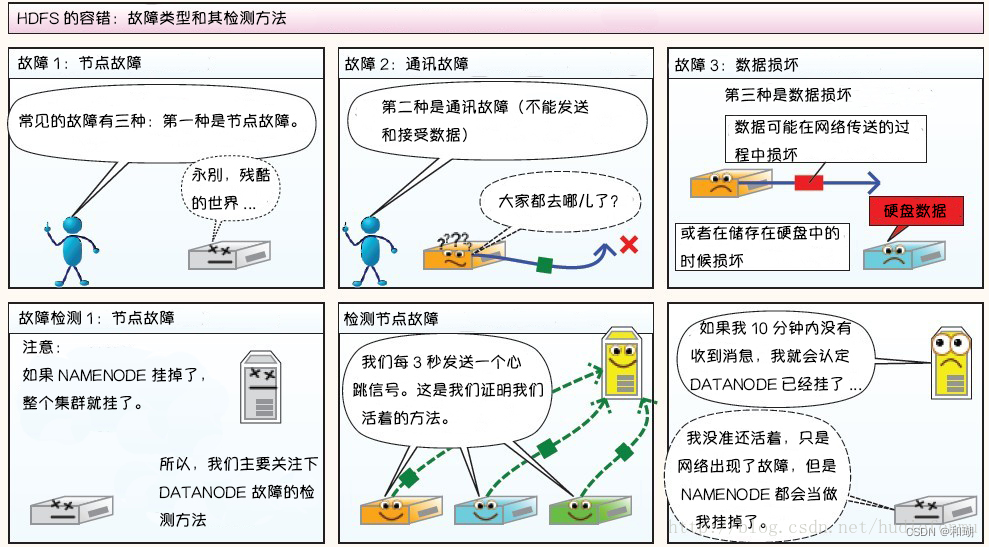
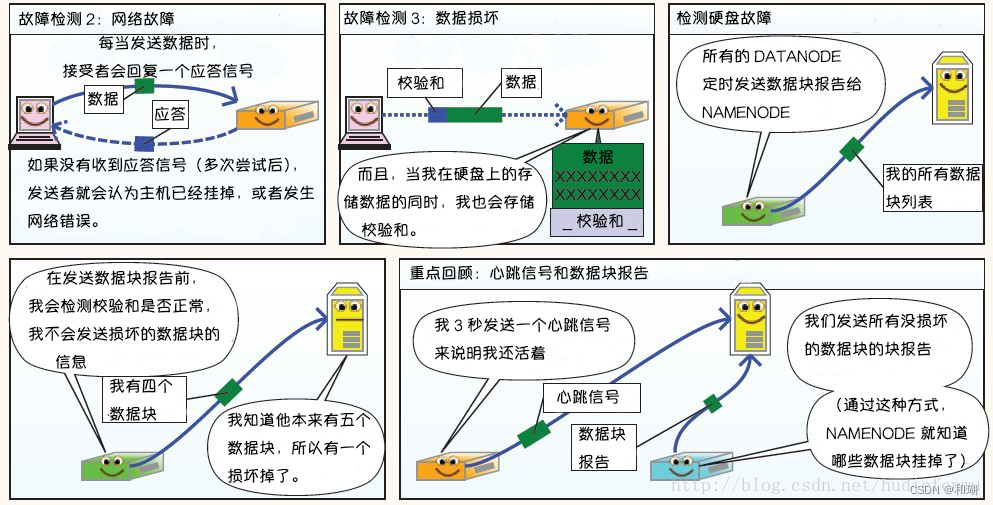
3. HDFS故障类型和其检测方法
故障类型和其检测方法
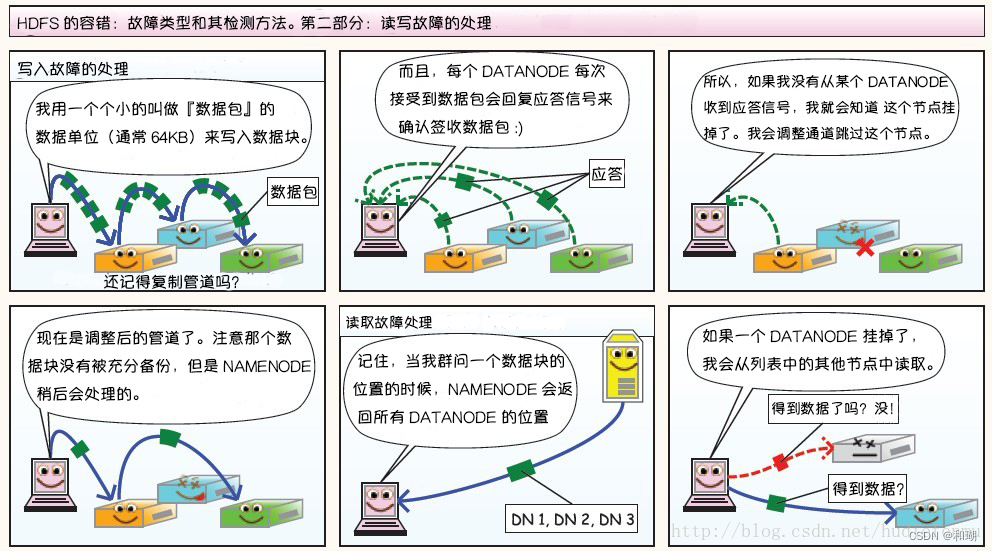
读写故障的处理
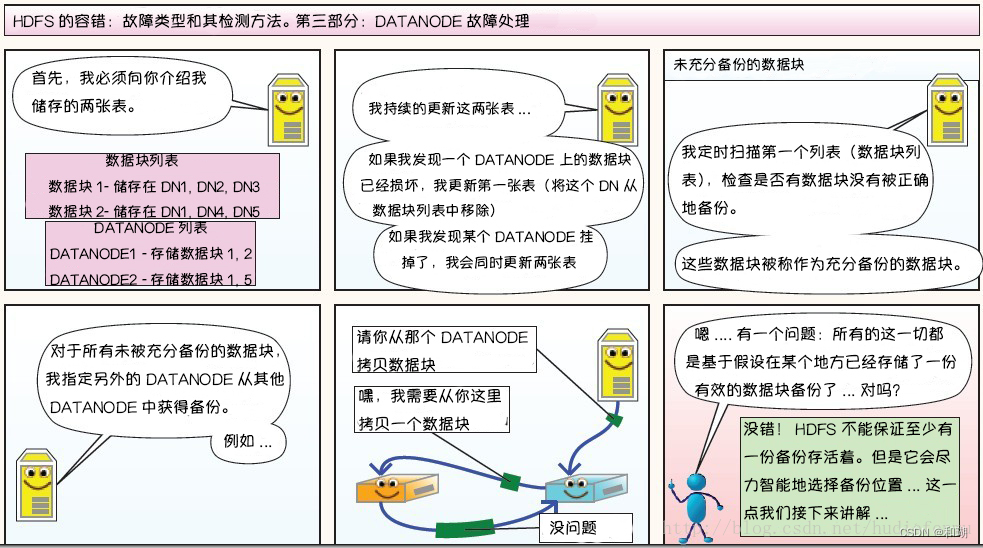
DataNode 故障处理
副本布局策略
原文地址:https://blog.csdn.net/kazuhura/article/details/134629860
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_13371.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。