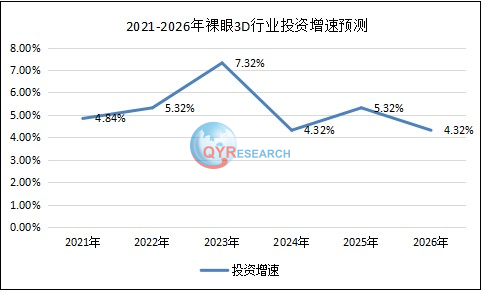
概括主要内容
文章《DeepFusion: Lidar-Camera Deep Fusion for Multi-Modal 3D Object Detection》提出了两种创新技术,以改善多模态3D检测模型的性能,通过更有效地融合相机和激光雷达传感器数据来提高对象检测的准确性,尤其是在行人检测方面。
这两种技术包括:
①InverseAug:该技术通过逆转几何相关的增强,如旋转,使激光雷达点和图像像素之间能够精确地几何对齐。它旨在纠正从两种不同传感器类型的数据组合时可能出现的扭曲和不对齐问题。
②LearnableAlign:该方法利用交叉注意力机制在融合过程中动态捕捉图像和激光雷达特征之间的相关性。它设计确保结合的传感器数据更准确地对齐,从而提升对象检测性能。
重点解释
①InverseAug 的核心思想是逆转几何相关的数据增强,例如随机旋转。在增强阶段,InverseAug会保存这些增强参数,然后在融合阶段逆向应用这些增强来获取3D关键点的原始坐标,最终找到它们在相机空间中的对应2D坐标。这种方法是通用的,可以对齐不同类型的关键点,如体素中心等,尽管为了简化,论文中只采用了激光雷达点。InverseAug通过这种方式显著提高了对齐质量。
②LearnableAlign 则利用交叉注意力机制动态学习激光雷达特征及其相应相机特征之间的相关性。这种方法允许模型在融合过程中学习如何更好地对齐不同传感器的数据,而不是简单地基于原始的激光雷达和相机参数。LearnableAlign通过这种学习机制有助于实现精确的特征级融合,从而提升检测模型的性能。
这两种技术都是简单、通用且高效的,能够在流行的3D点云检测框架(如PointPillars和CenterPoint)中实现与激光雷达点云的有效对齐,而且计算成本较低(即只需要一个交叉注意力层)