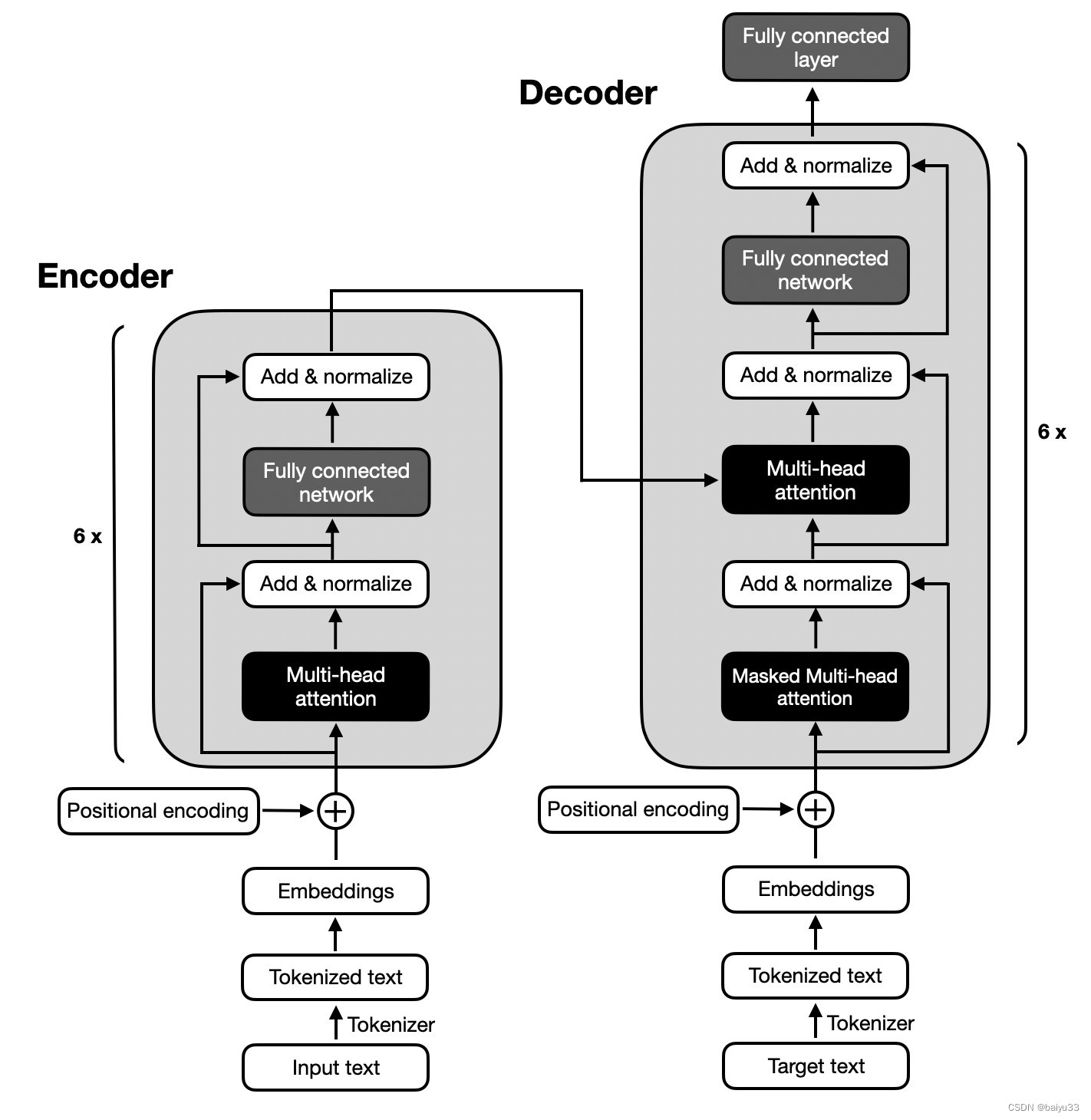
上一篇文章,我们介绍了encoder,这篇文章我们将要介绍decoder
Transformer-encoder
decoder结构:
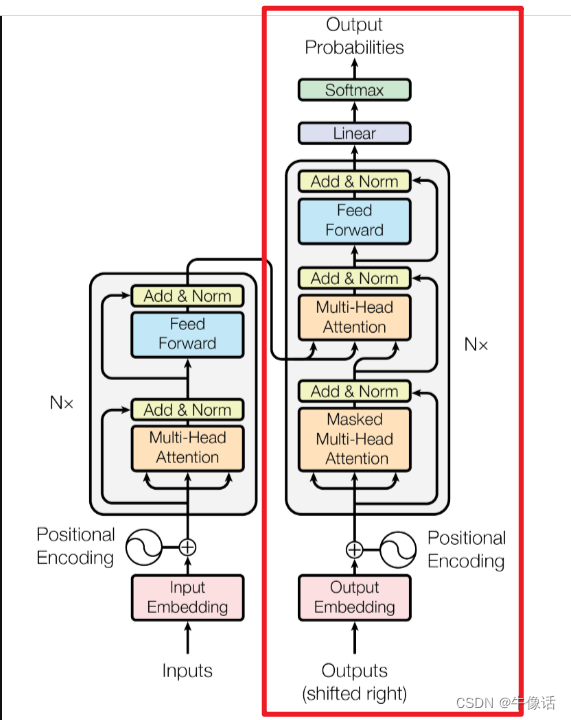
如果看过上一篇文章的同学,肯定对decoder的结构不陌生,从上面框中可以明显的看出:
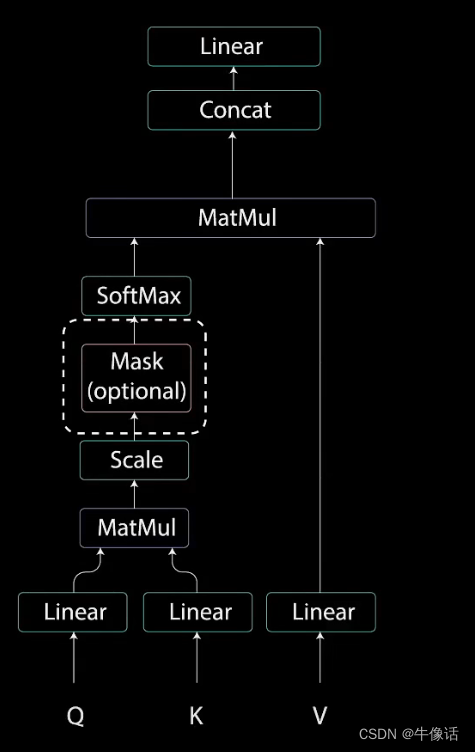
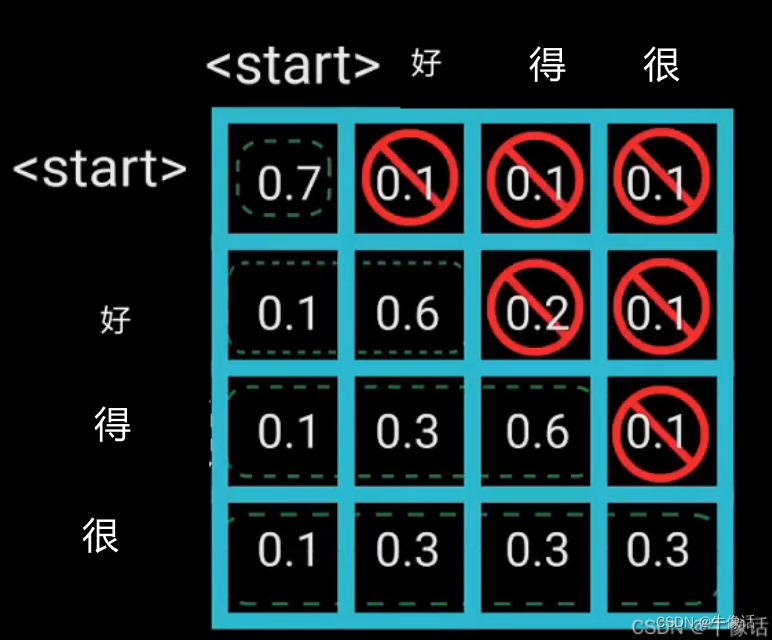
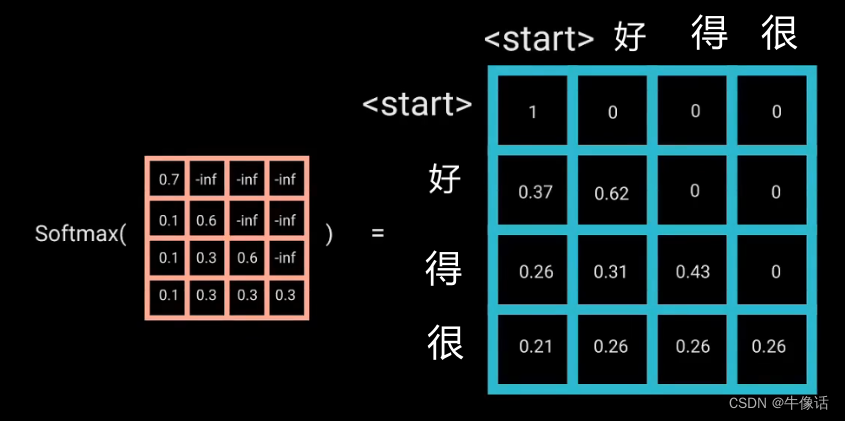
这里我们详细说一下多头掩码注意力模块,其他的和encoder中都一样,就不详细介绍了。
Masked Multi-Head Attention
在下面第9点介绍多头掩码注意力
在介绍之前,我们先来说一下transformer的训练过程,网上搜了很多,没有找到谁具体讲过,所以我就借助“文心一言”来进行了询问,大概了解了这个过程,但是不能保证正确,如果有知道同学看到了,欢迎给我留言。
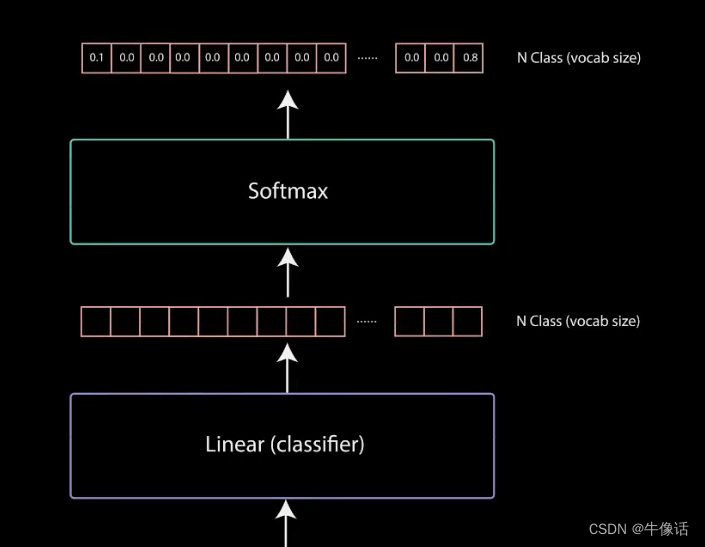 然后
然后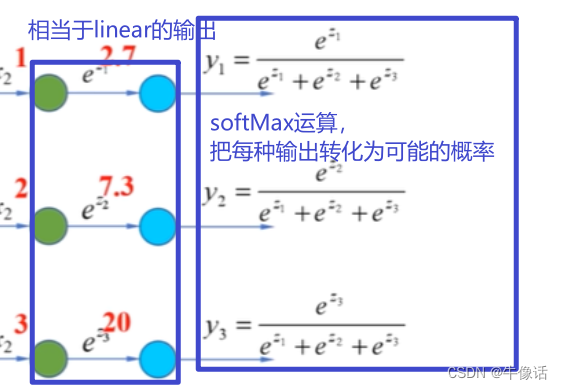
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。