本文介绍: 1、测试计划 , jmeter的起点和容器2、线程组,代表一定的虚拟用户3、取样器 , 一般会使用http请求 发送请求的最小单元4、 逻辑控制器, if逻辑控制器,用于条件判断5、 前置处理器, 发送请求前要做的事情 请求之前的操作6、 后置处理器, 得到响应数据后要做的事情,比如: json提取器,xpath提取器。请求之后的操作7、 断言, 判断预期结果和实际结果是否一致8、 定时器,一般会同步定时器 主要用于做接口性能测试 是否延迟或者定时发送。

1、 jmeter的介绍
jmeter也是一款接口测试工具,由java语言开发的,主要进行性能测试。
2、jmeter安装
jmeter官网下载链接: https://jmeter.apache.org/download_jmeter.cgi ,查看是否安装成功【jmeter –v】
下载 java jdk1.8,进行安装,测试命令:java –version, https://repo.huaweicloud.com/java/jdk/
3、界面功能介绍
4、jmeter的十大元件
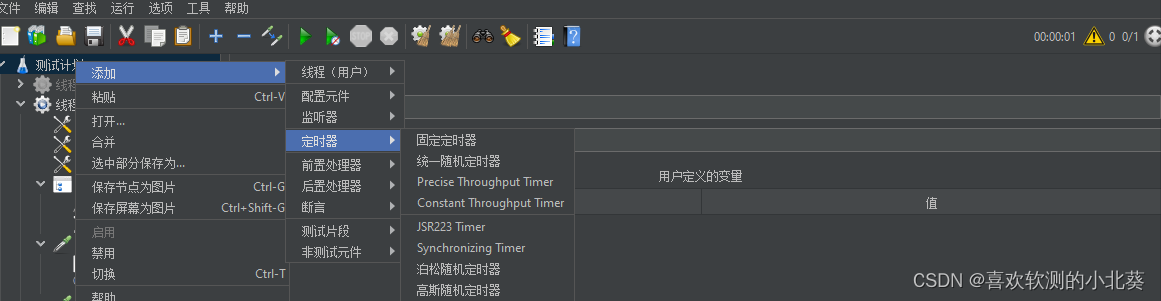
5、作用域
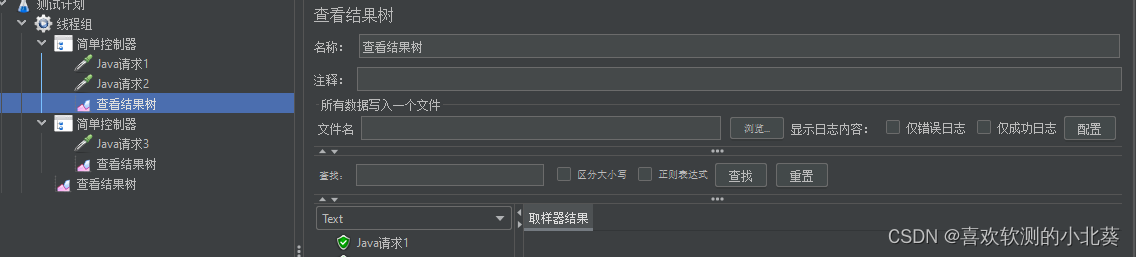
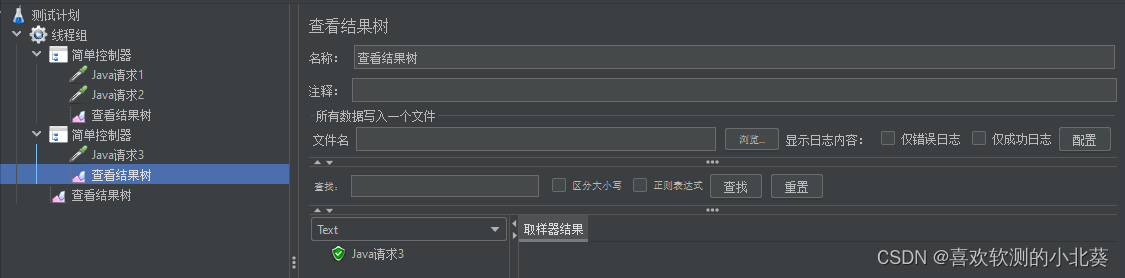
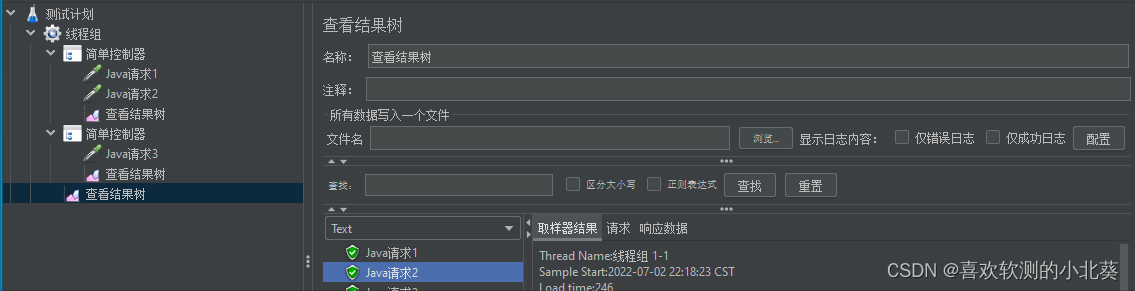
6、进程、线程、线程组
7、jmeter的基本使用
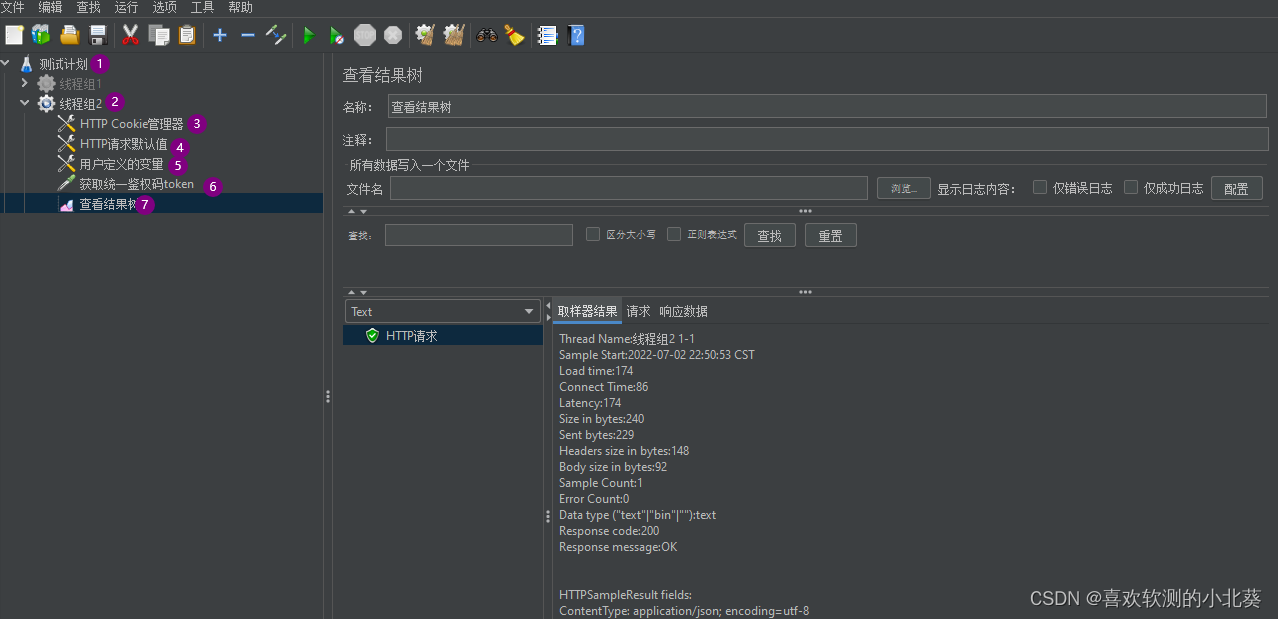
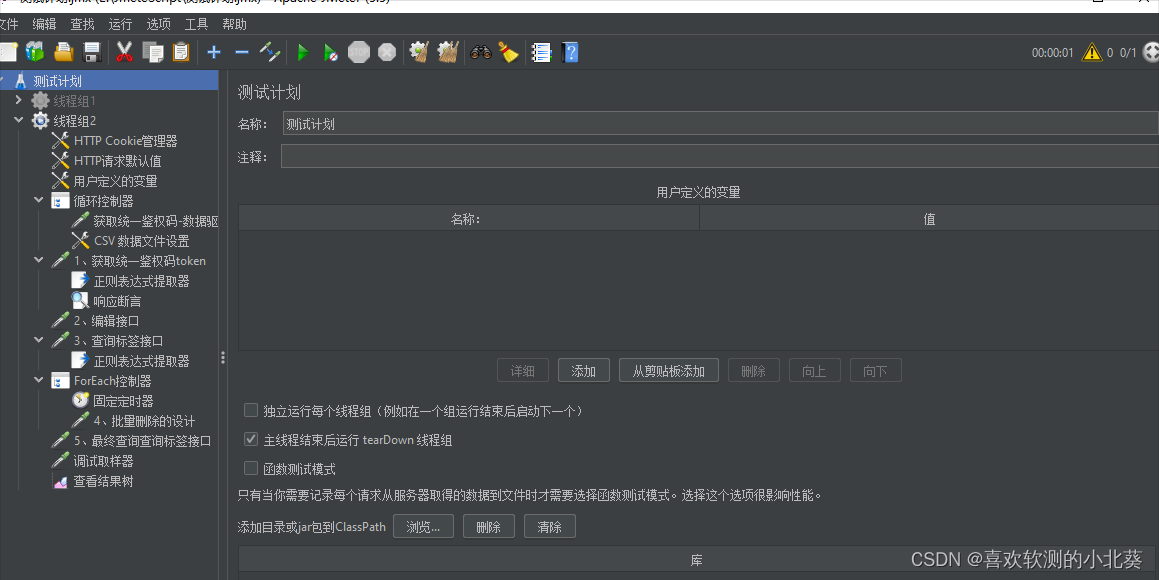
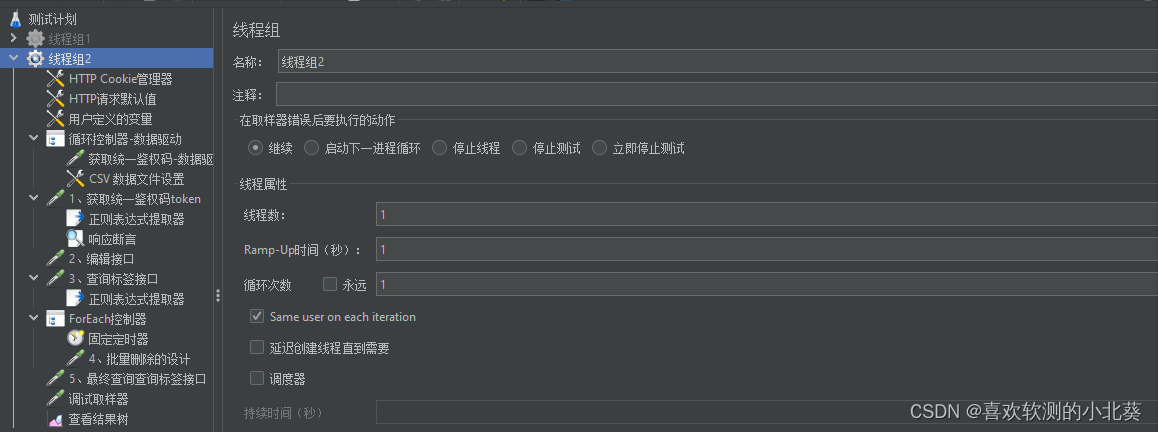
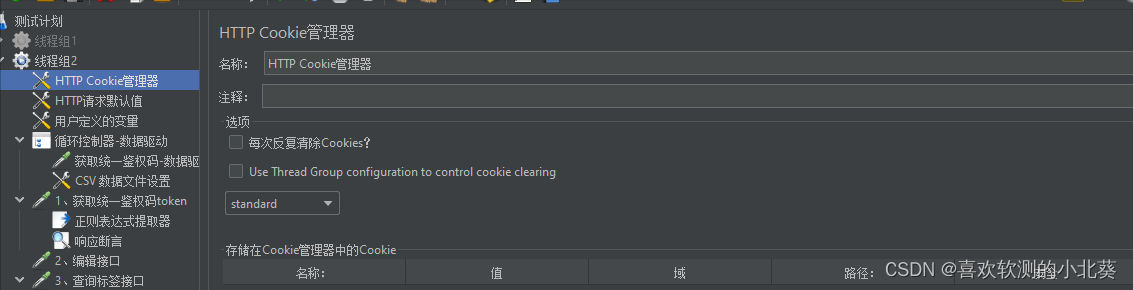
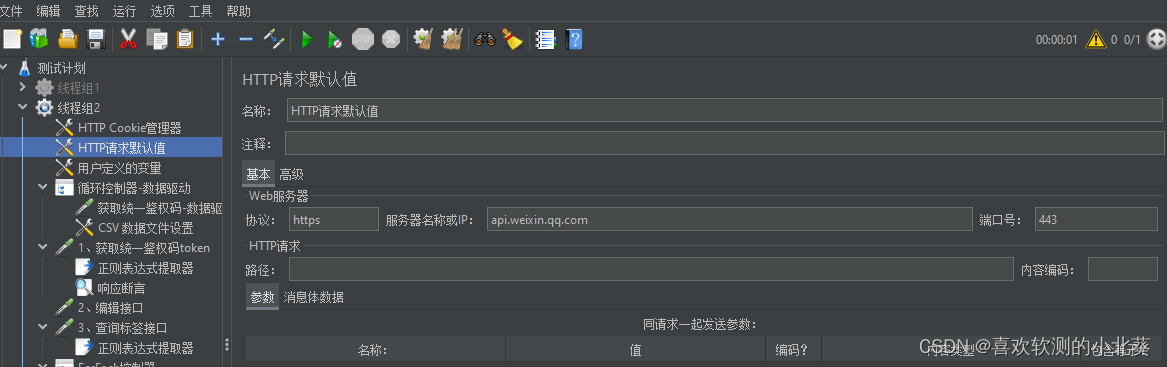



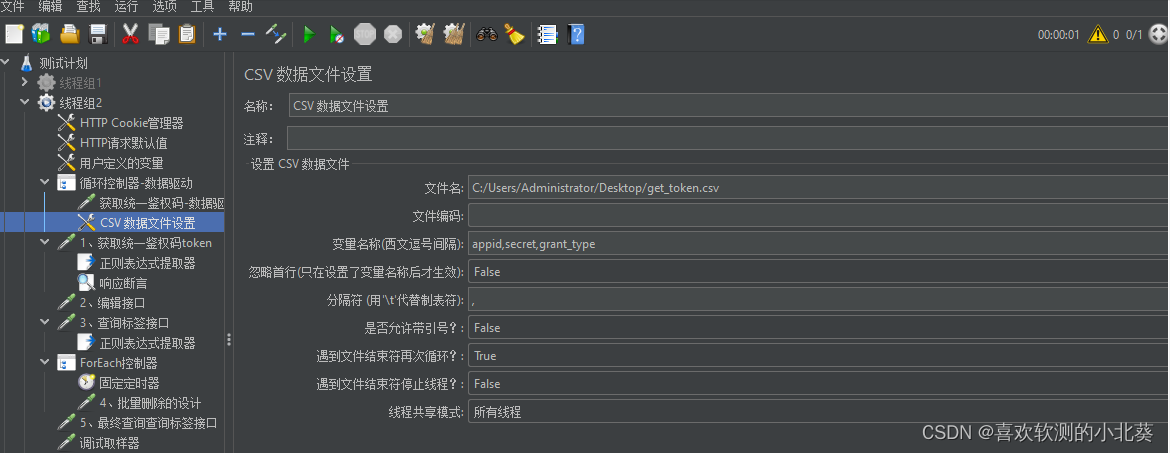
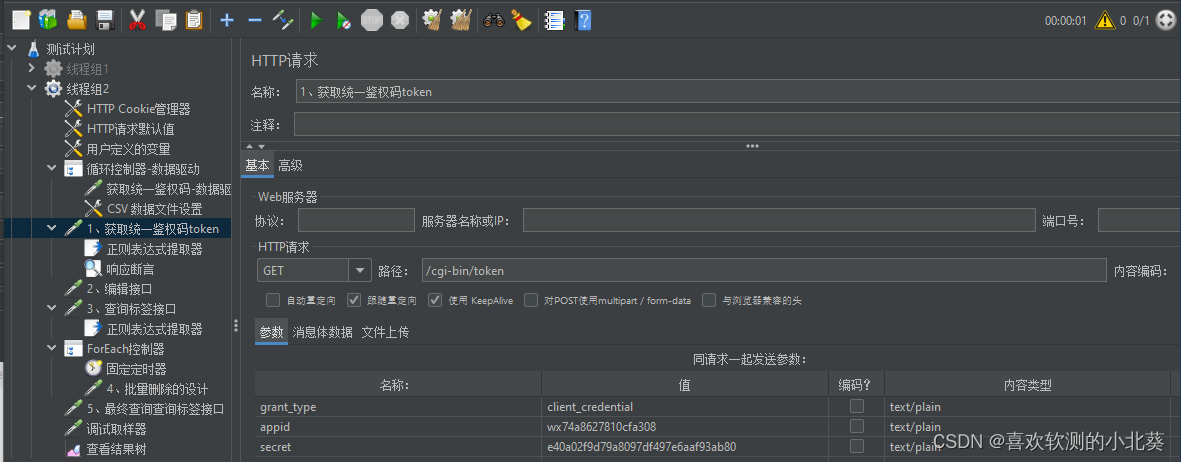
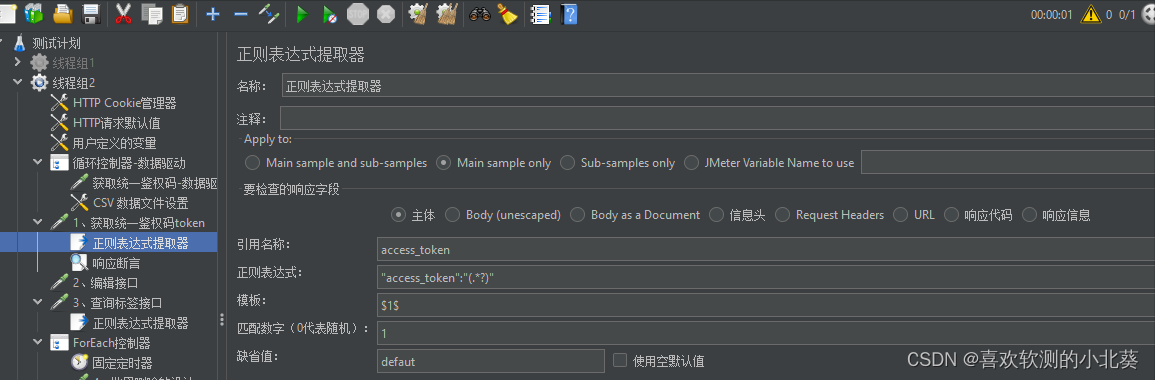
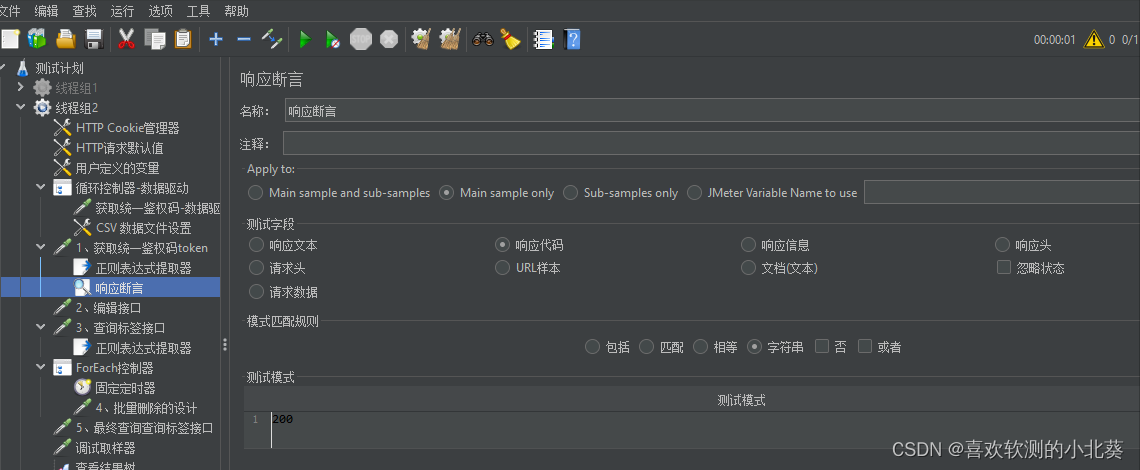
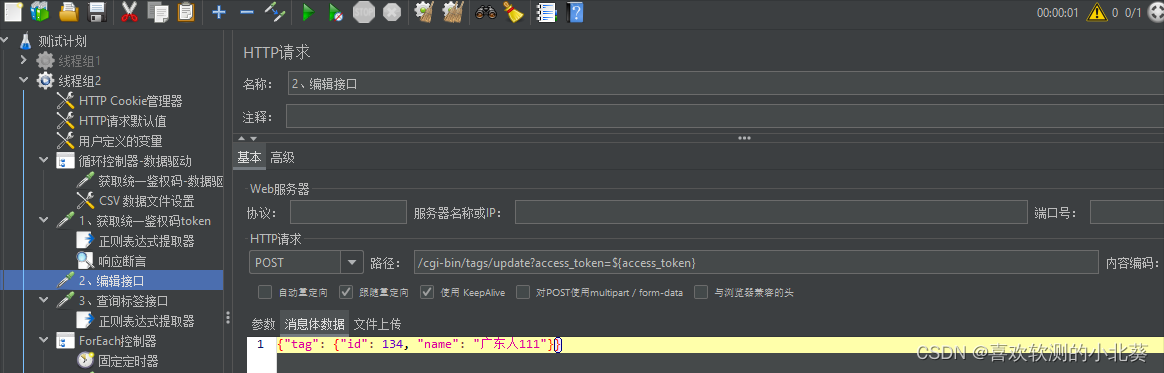
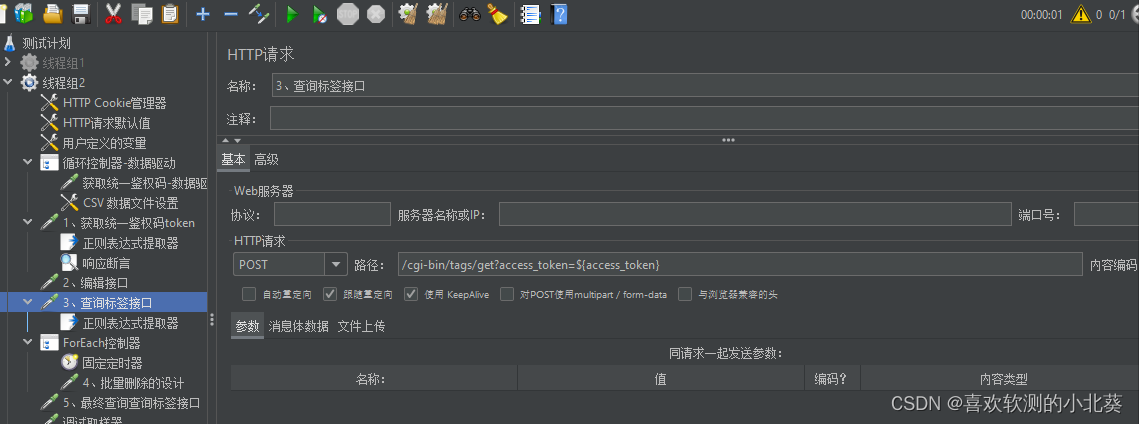
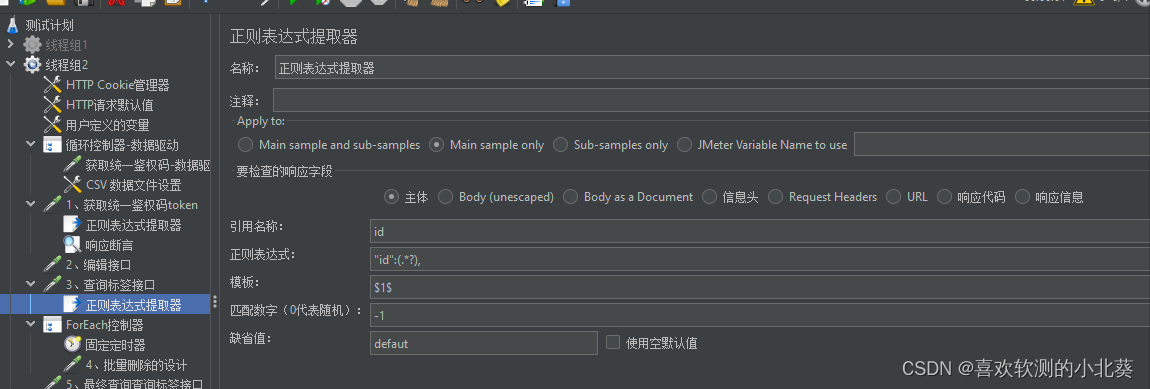
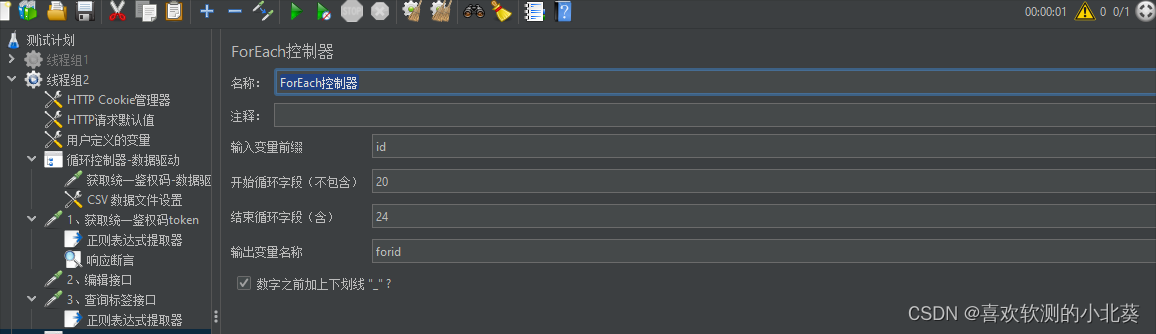

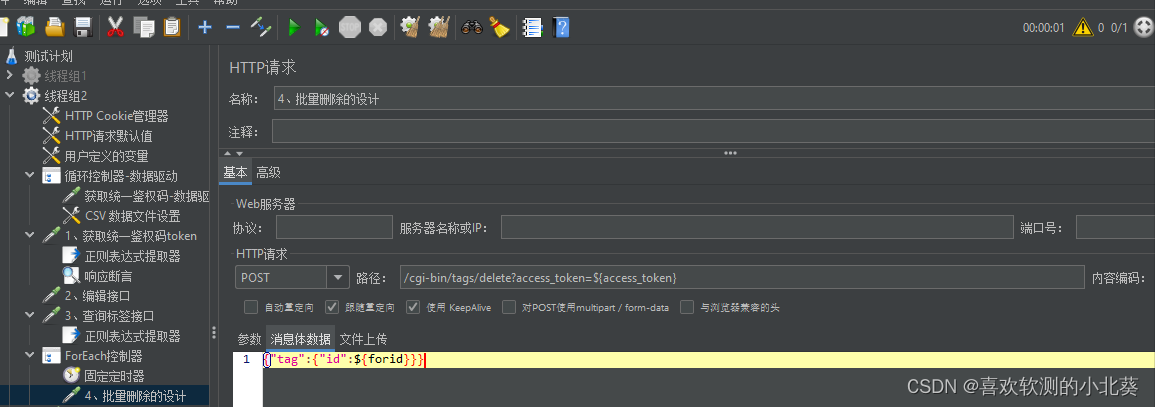
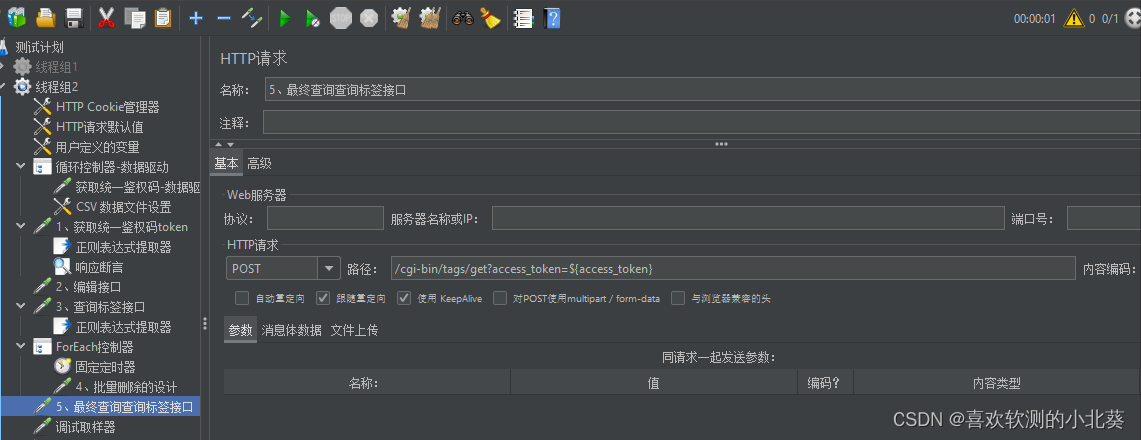
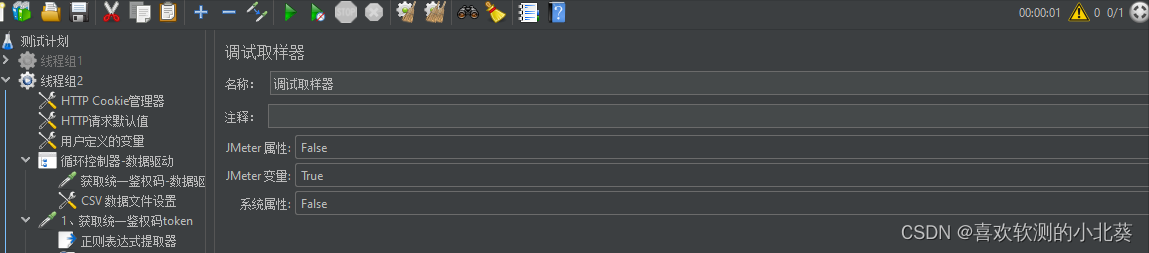
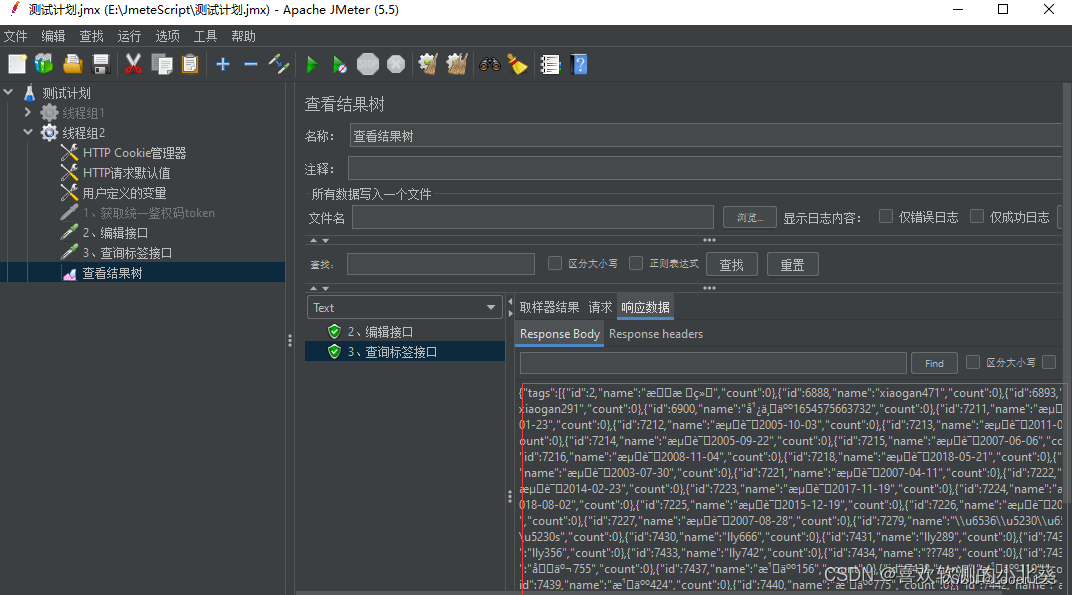
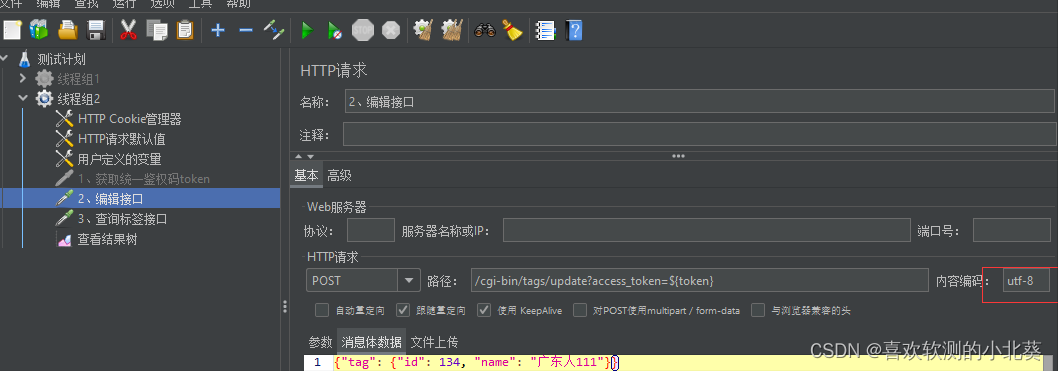

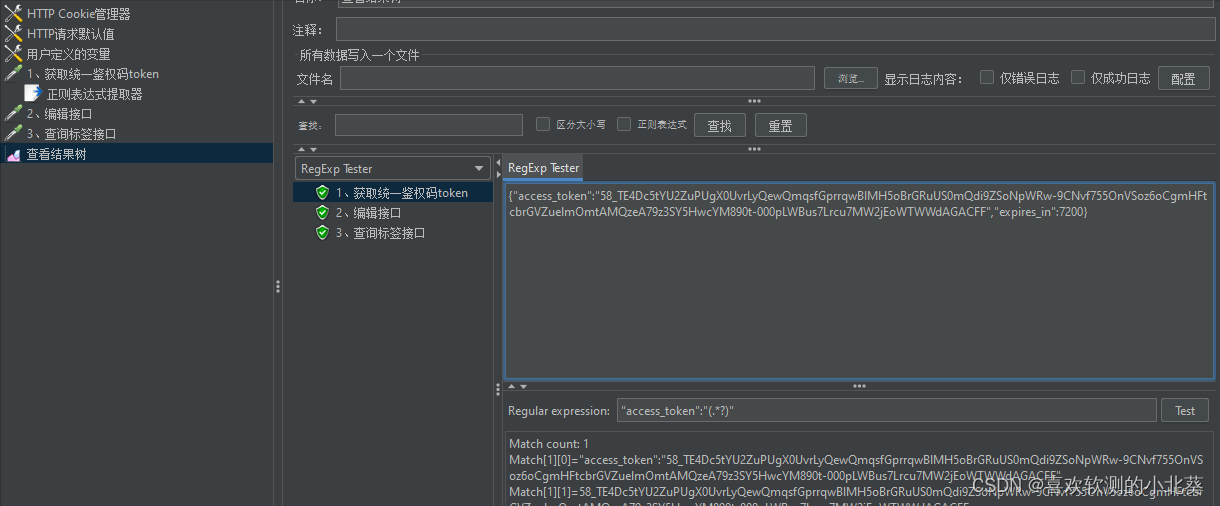
8、接口关联的方式
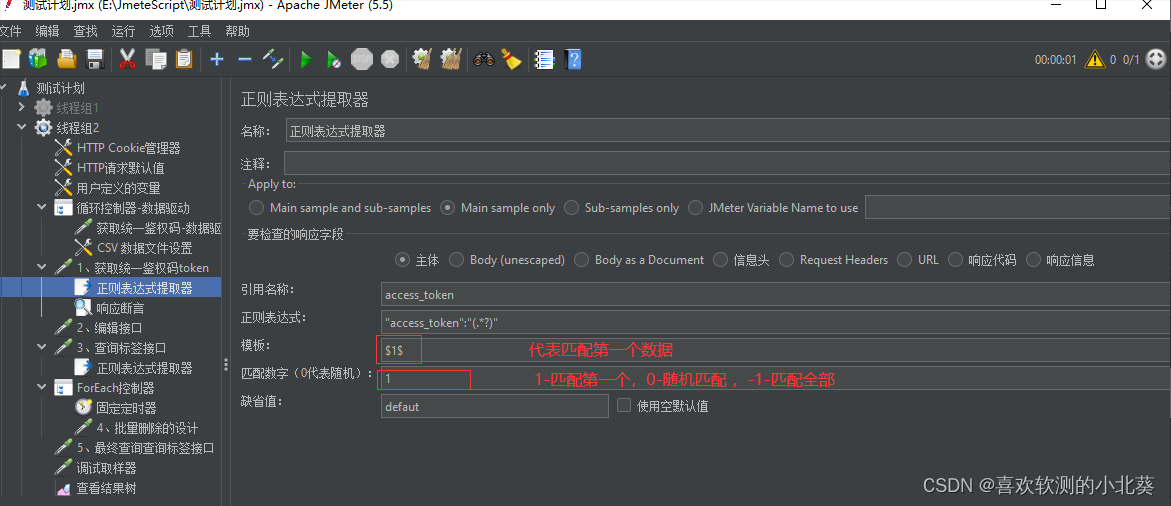
9、setup线程组和teardown线程组
10、http请求默认值
11、参数化
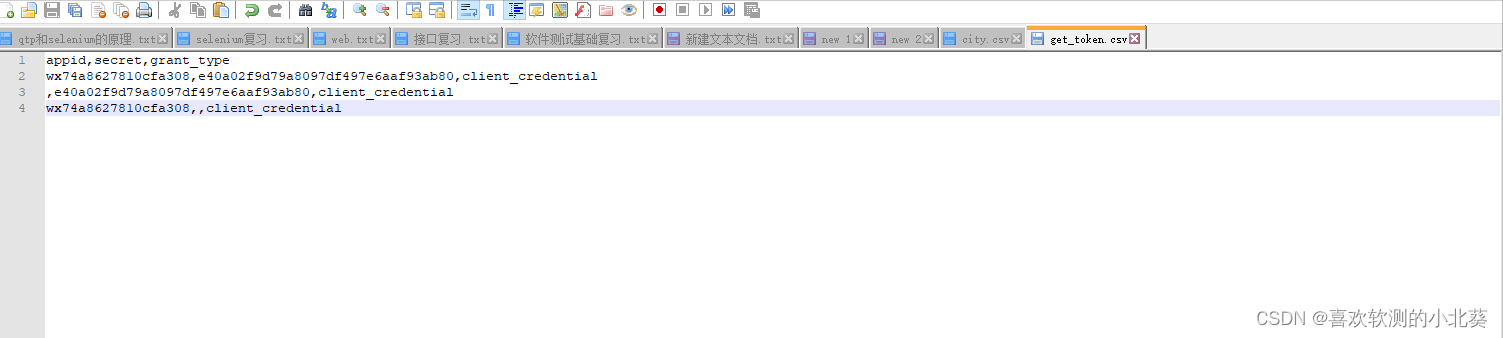
12、jmeter实现操作数据库的原理
13、提取器
14、断言
14、聚合报告
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
![[设计模式Java实现附plantuml源码~行为型]请求的链式处理——职责链模式](https://img-blog.csdnimg.cn/direct/699aac3ed0c446d088772a0ed4c444ed.png)