Go 基础类
GO 语言当中 NEW 和 MAKE 有什么区别吗?
new的作用是初始化一个内置类型的指针new函数是内建函数,函数定义:
⚫使用new函数来分配空间
⚫传递给new函数的是一个类型,而不是一个值
⚫返回值是指向这个新分配的地址的指针
##GO 语言中 MAKE 的作用是什么?
make的作用是为slice, map or chan的初始化 然后返回引用 make函数是内建函数,函数定义:
make(T, args)函数的目的和new(T)不同 仅仅用于创建slice, map, channel 而且返回类型是实例
PRINTF(),SPRINTF(),FPRINTF() 都是格式化输出,有什么不同?
虽然这三个函数,都是格式化输出,但是输出的目标不一样
Printf是标准输出,一般是屏幕,也可以重定向。
Sprintf()是把格式化字符串输 出到指定的字符串中。
Fprintf()是把格式化字符串输出到文件中。
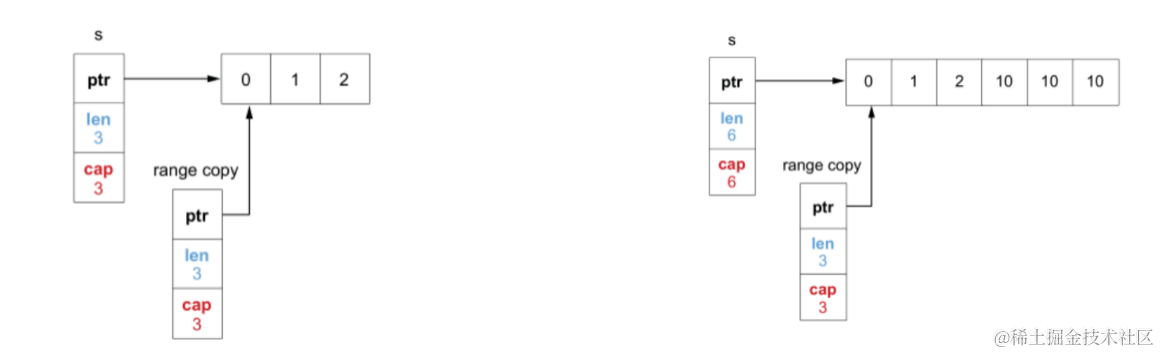
GO 语言当中数组和切片的区别是什么?
数组:
数组固定长度。数组长度是数组类型的一部分,所以[3]int 和[4]int
是两种不同的数组类型数组需要指定大小,不指定也会根据初始化,自动推算出大小,大小不可改变。数组是通过值传递的
切片:
切片可以改变长度。切片是轻量级的数据结构,三个属性,指针,长度,容量不需要指定大小切片是地址传递(引用传递)可以通过数组来初始化,也可以通过内置函数make()来初始化,初始化的时候len=cap,然后进行扩容。
GO 语言当中值传递和地址传递(引用传递)如何运用?有什么区别?举例说明
1.值传递只会把参数的值复制一份放进对应的函数,两个变量的地址不同,不可相互修改。
2.地址传递(引用传递)会将变量本身传入对应的函数,在函数中可以对该变量进行值内容的修改。
GO 语言当中数组和切片在传递的时候的区别是什么?
1.数组是值传递
2.切片是引用传递
Go 语言是如何实现切片扩容的?
func main() {
arr := make([]int, 0)
for i := 0; i < 2000; i++ {
fmt.Println("len为", len(arr), "cap为", cap(arr)) arr = append(arr, i)
}
}
我们可以看下结果 依次是 0,1,2,4,8,16,32,64,128,256,512,1024
但到了1024之后,
就变成了 1024,1280,1696,2304
每次都是扩容了四分之一左右
看下面代码的 defer 的执行顺序是什么? defer的作用和特点是什么?
defer的作用是:
你只需要在调用普通函数或方法前加上关键字defer,就完成了defer所需要的语法。当defer语句被执行时,跟在defer后面的函数会被延迟执行。直到包含该defer语句的函数执行完毕时,defer后的函数才会被执行,不论包含defer语句的函数是通过return正常结束,还是由于panic导致的异常结束。你可以在一个函数中执行多条defer语句,它们的执行顺序与声明顺序相反。
defer的常用场景:
⚫defer语句经常被用于处理成对的操作,如打开、关闭、连接、断开连接、加锁、释放锁。
⚫通过defer机制,不论函数逻辑多复杂,都能保证在任何执行路径下,资源被释放。
⚫释放资源的defer应该直接跟在请求资源的语句后。

剩余部分在面试题文档下链接点击这里免积分下载
Go 并发编程
MUTEX 几种状态
⚫mutexLocked — 表示互斥锁的锁定状态;
⚫mutexWoken — 表示从正常模式被从唤醒;
⚫mutexStarving — 当前的互斥锁进入饥饿状态;
⚫waitersCount — 当前互斥锁上等待的 Goroutine 个数;
MUTEX 正常模式和饥饿模式
正常模式(非公平锁)
正常模式下,所有等待锁的goroutine按照FIFO(先进先出)顺序等待。唤醒的goroutine不会直接拥有锁,而是会和新请求goroutine竞争锁。新请求的goroutine更容易抢占:因为它正在CPU上执行,所以刚刚唤醒的goroutine
20 有很大可能在锁竞争中失败。在这种情况下,这个被唤醒的goroutine会加入到等待队列的前面。
饥饿模式(公平锁)
为了解决了等待goroutine队列的长尾问题 饥饿模式下,直接由unlock把锁交给等待队列中排在第一位的goroutine
(队头),同时,饥饿模式下,新进来的goroutine不会参与抢锁也不会进入自旋状态,会直接进入等待队列的尾部。这样很好的解决了老的goroutine一直抢不到锁的场景。
饥饿模式的触发条件:当一个goroutine等待锁时间超过1毫秒时,或者当前队列只剩下一个goroutine的时候,Mutex切换到饥饿模式。
总结
对于两种模式,正常模式下的性能是最好的,goroutine可以连续多次获取锁,饥饿模式解决了取锁公平的问题,但是性能会下降,这其实是性能和公平的一个平衡模式。
RWMUTEX 实现
通过记录readerCount
读锁的数量来进行控制,当有一个写锁的时候,会将读锁数量设置为负数1<<30。目的是让新进入的读锁等待之前的写锁释放通知读锁。同样的当有写锁进行抢占时,也会等待之前的读锁都释放完毕,才会开始
21 进行后续的操作。 而等写锁释放完之后,会将值重新加上1<<30, 并通知刚才新进入的读锁(rw.readerSem),两者互相限制。
RWMUTEX 注意事项
⚫RWMutex 是单写多读锁,该锁可以加多个读锁或者一个写锁
⚫读锁占用的情况下会阻止写,不会阻止读,多个 Goroutine 可以同时获取读锁
⚫写锁会阻止其他 Goroutine(无论读和写)进来,整个锁由该 Goroutine独占
⚫适用于读多写少的场景
⚫RWMutex 类型变量的零值是一个未锁定状态的互斥锁
⚫RWMutex 在首次被使用之后就不能再被拷贝
⚫RWMutex 的读锁或写锁在未锁定状态,解锁操作都会引发 panic
⚫RWMutex 的一个写锁去锁定临界区的共享资源,如果临界区的共享资源已被(读锁或写锁)锁定,这个写锁操作的 goroutine 将被阻塞直到解锁
⚫RWMutex 的读锁不要用于递归调用,比较容易产生死锁
⚫RWMutex 的锁定状态与特定的 goroutine 没有关联。一个 goroutine 可以 RLock(Lock),另一个 goroutine 可以 RUnlock(Unlock)
⚫写锁被解锁后,所有因操作锁定读锁而被阻塞的 goroutine 会被唤醒,并都可以成功锁定读锁
⚫读锁被解锁后,在没有被其他读锁锁定的前提下,所有因操作锁定写锁而被阻塞的 Goroutine,其中等待时间最长的一个 Goroutine 会被唤醒
WAITGROUP 用法
一个 WaitGroup 对象可以等待一组协程结束。使用方法是:
1.main协程通过调用 wg.Add(delta int) 设置worker协程的个数,然后创建worker协程;
2.worker协程执行结束以后,都要调用 wg.Done();
3.main协程调用 wg.Wait() 且被block,直到所有worker协程全部执行结束后返回。
WAITGROUP 实现原理
⚫WaitGroup主要维护了2个计数器,一个是请求计数器 v,一个是等待计数器 w,二者组成一个64bit的值,请求计数器占高32bit,等待计数器占低32bit。
⚫每次Add执行,请求计数器v加1,Done方法执行,等待计数器减1,v为0时通过信号量唤醒Wait()。
什么是 SYNC.ONCE
⚫Once 可以用来执行且仅仅执行一次动作,常常用于单例对象的初始化场景。
⚫Once 常常用来初始化单例资源,或者并发访问只需初始化一次的共享资源,或者在测试的时候初始化一次测试资源。
⚫sync.Once 只暴露了一个方法 Do,你可以多次调用 Do 方法,但是只有第一次调用 Do 方法时 f 参数才会执行,这里的 f 是一个无参数无返回值的函数。

剩余部分在面试题文档下链接点击这里免积分下载
Go Runtime
GOROUTINE 定义
Golang 在语言级别支持协程,称之为 Goroutine。Golang 标准库提供的所有系统调用操作(包括所有的同步 I/O
操作),都会出让 CPU 给其他 Goroutine。这让 Goroutine 的切换管理不依赖于系统的线程和进程,也不依赖于 CPU
的核心数量,而是交给 Golang 的运行时统一调度。
GMP 指的是什么
G(Goroutine):我们所说的协程,为用户级的轻量级线程,每个Goroutine对象中的sched保存着其上下文信息。
M(Machine):对内核级线程的封装,数量对应真实的CPU数(真正干活的对象)。
P(Processor):即为G和M的调度对象,用来调度G和M之间的关联关系,其数量可通过GOMAXPROCS()来设置,默认为核心数。
GMP 调度流程
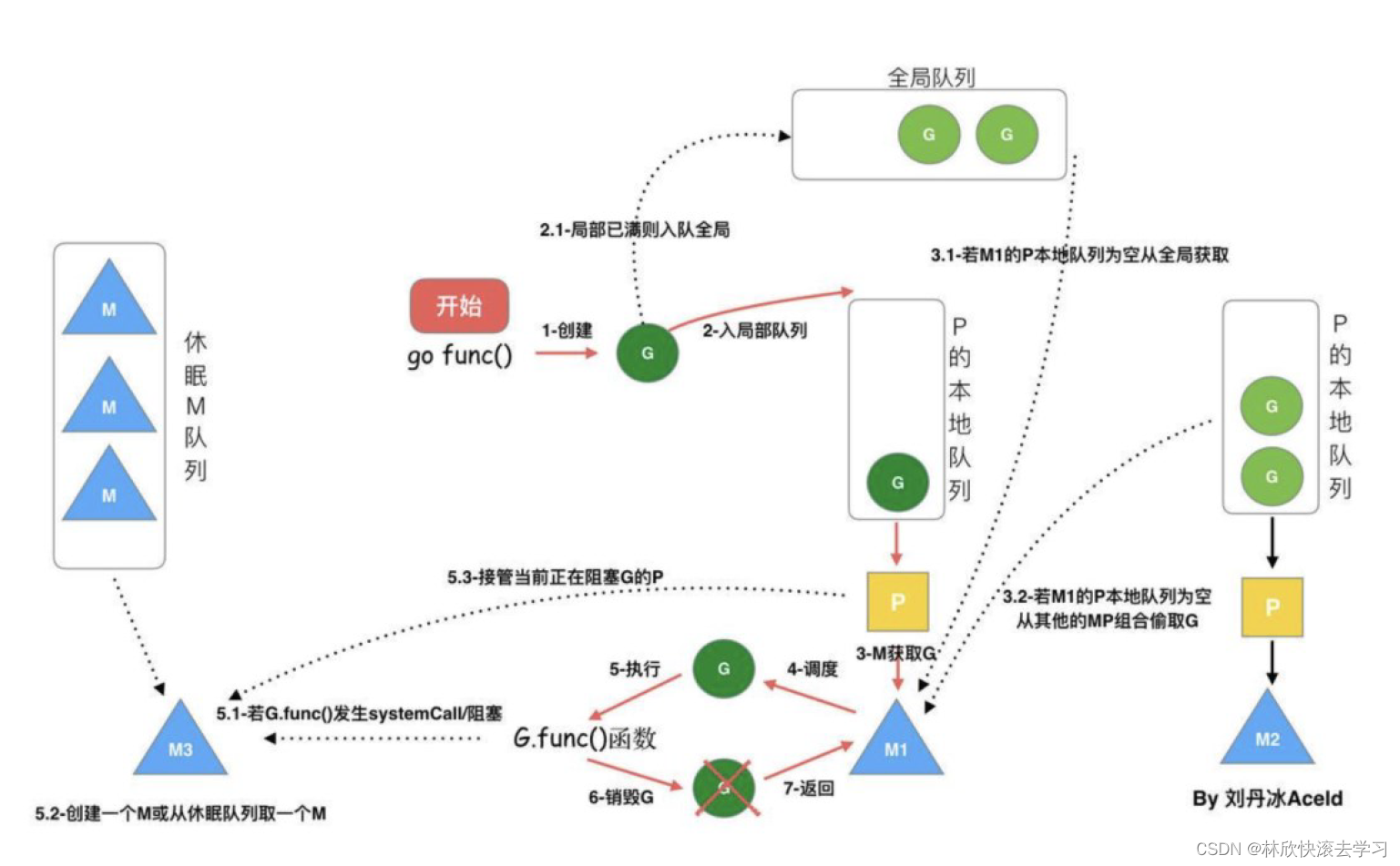
⚫每个P有个局部队列,局部队列保存待执行的goroutine(流程2),当M绑定的P的的局部队列已经满了之后就会把goroutine放到全局队列(流程2-1)
⚫每个P和一个M绑定,M是真正的执行P中goroutine的实体(流程3),M从绑定的P中的局部队列获取G来执行
⚫当M绑定的P的局部队列为空时,M会从全局队列获取到本地队列来执行G(流程3.1),当从全局队列中没有获取到可执行的G时候,M会从其他P的局部队列中偷取G来执行(流程3.2),这种从其他P偷的方式称为work stealing
⚫当G因系统调用(syscall)阻塞时会阻塞M,此时P会和M解绑即handoff,并寻找新的idle的M,若没有idle的M就会新建一个M(流程5.1)
⚫当G因channel或者network I/O阻塞时,不会阻塞M,M会寻找其他runnable的G;当阻塞的G恢复后会重新进入runnable进入P队列等待执行
三色标记原理
我们首先看一张图,大概就会对 三色标记法有一个大致的了解:
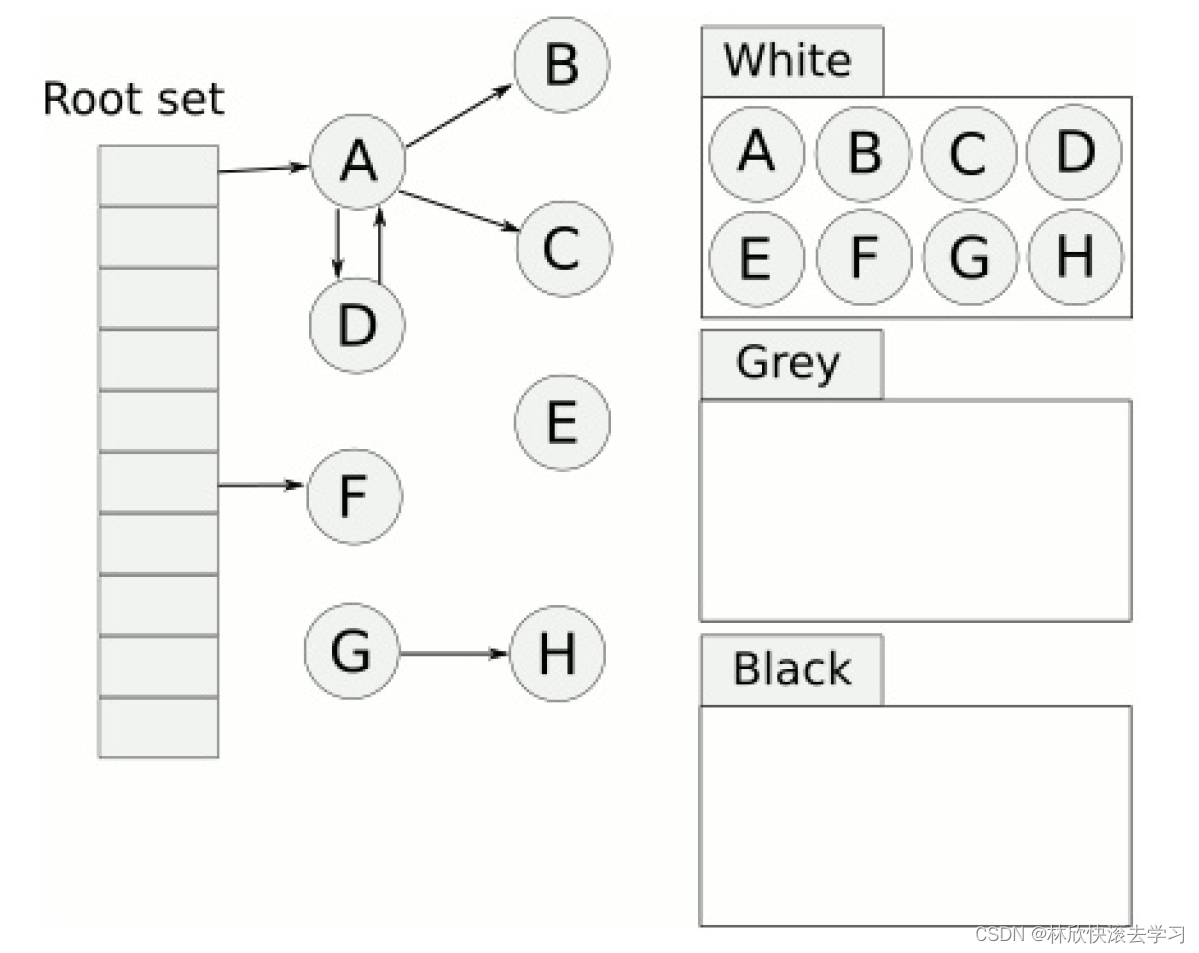
原理:
首先把所有的对象都放到白色的集合中
⚫从根节点开始遍历对象,遍历到的白色对象从白色集合中放到灰色集合中
⚫遍历灰色集合中的对象,把灰色对象引用的白色集合的对象放入到灰色集合中,同时把遍历过的灰色集合中的对象放到黑色的集合中
⚫循环步骤3,知道灰色集合中没有对象
⚫步骤4结束后,白色集合中的对象就是不可达对象,也就是垃圾,进行回收
GC 触发时机
主动触发:调用 runtime.GC 被动触发: 使用系统监控,该触发条件由runtime.forcegcperiod变量控制,默认为 2
分钟。当超过两分钟没有产生任何 GC 时,强制触发 GC。 使用步调(Pacing)算法,其核心思想是控制内存增长的比例。如Go 的 GC
是一种比例 GC, 下一次 GC 结束时的堆大小和上一次 GC 存活堆大小成比例.
GO 语言中 GC 的流程是什么?
Go1.14版本以 STW 为界限,可以将 GC 划分为五个阶段:
GCMark标记准备阶段,为并发标记做准备工作,启动写屏障
STWGCMark扫描标记阶段,与赋值器并发执行,写屏障开启并发GCMarkTermination标记终止阶段,保证一个周期内标记任务完成,停止写屏障
GCoff内存清扫阶段,将需要回收的内存归还到堆中,写屏障关闭
GCoff内存归还阶段,将过多的内存归还给操作系统,写屏障关闭。
框架
Gin
请简要介绍一下Gin框架以及它的优点。
Gin框架是一种基于Go语言的轻量级Web框架,具有高效、快速、易用等优点。Gin采用了类似于Express.js的中间件机制,并提供了简单易用的路由、错误处理、模板引擎等功能
Gin支持哪些HTTP请求方式?
Gin框架支持常见的HTTP请求方式,包括GET、POST、PUT、PATCH、DELETE、HEAD和OPTIONS。这些请求方式可以通过使用gin.Context对象的方法来处理请求,例如c.Request.Method获取当前请求的HTTP方法。
如何在Gin中处理GET和POST请求参数?
在Gin中,可以通过c.Query()方法获取GET请求参数,该方法返回一个字符串类型的值,也可以通过c.DefaultQuery()方法设置默认值。对于POST请求,可以通过c.PostForm()或c.DefaultPostForm()方法获取POST请求参数,其中c.PostForm()方法只能解析Content-Type为application/x-www–form–urlencoded的表单数据,而c.DefaultPostForm()方法除了可以解析该类型的表单数据外,还可以解析multipart/form–data类型的表单数据。
Gin框架中如何实现路由?
Gin框架通过路由来确定函数执行的路径,可以使用router :=
gin.Default()创建默认路由组,然后使用router.GET()、router.POST()等方法添加不同请求方式的路由。路由可以包含参数,例如/:name可以匹配任意名称的路径片段,并将该片段存储在name变量中。
如何在Gin中处理文件上传?
Gin框架可以通过c.SaveUploadedFile()方法来处理文件上传,该方法需要传递两个参数:表单中的文件字段名和保存的文件名。此外,Gin框架还可通过c.FormFile()方法来获取上传的文件对象,该方法返回一个multipart.FileHeader类型的值。
微服务
您对微服务有何了解?
微服务,又称微服务架构,是一种架构风格,它将应用程序构建为以业务领域为模型的小型自治服务集合。
通俗地说,你必须看到蜜蜂如何通过对齐六角形蜡细胞来构建它们的蜂窝状物。他们最初从使用各种材料的小部分开始,并继续从中构建一个大型蜂箱。这些细胞形成图案,产生坚固的结构,将蜂窝的特定部分固定在一起。
这里,每个细胞独立于另一个细胞,但它也与其他细胞相关。这意味着对一个细胞的损害不会损害其他细胞,因此,蜜蜂可以在不影响完整蜂箱的情况下重建这些细胞。
说说微服务架构的优势

微服务有哪些特点?
⚫解耦—系统内的服务很大程度上是分离的。因此,整个应用程序可以轻松构建,更改和扩展
⚫组件化—微服务被视为可以轻松更换和升级的独立组件
⚫业务能力—微服务非常简单,专注于单一功能
⚫自治—开发人员和团队可以彼此独立工作,从而提高速度
⚫持续交付—通过软件创建,测试和批准的系统自动化,允许频繁发布软件
⚫责任—微服务不关注应用程序作为项目。相反,他们将应用程序视为他们负责的产品
⚫分散治理—重点是使用正确的工具来做正确的工作。这意味着没有标准化模式或任何技术模式。开发人员可以自由选择最有用的工具来解决他们的问题
⚫敏捷—微服务支持敏捷开发。任何新功能都可以快速开发并再次丢弃
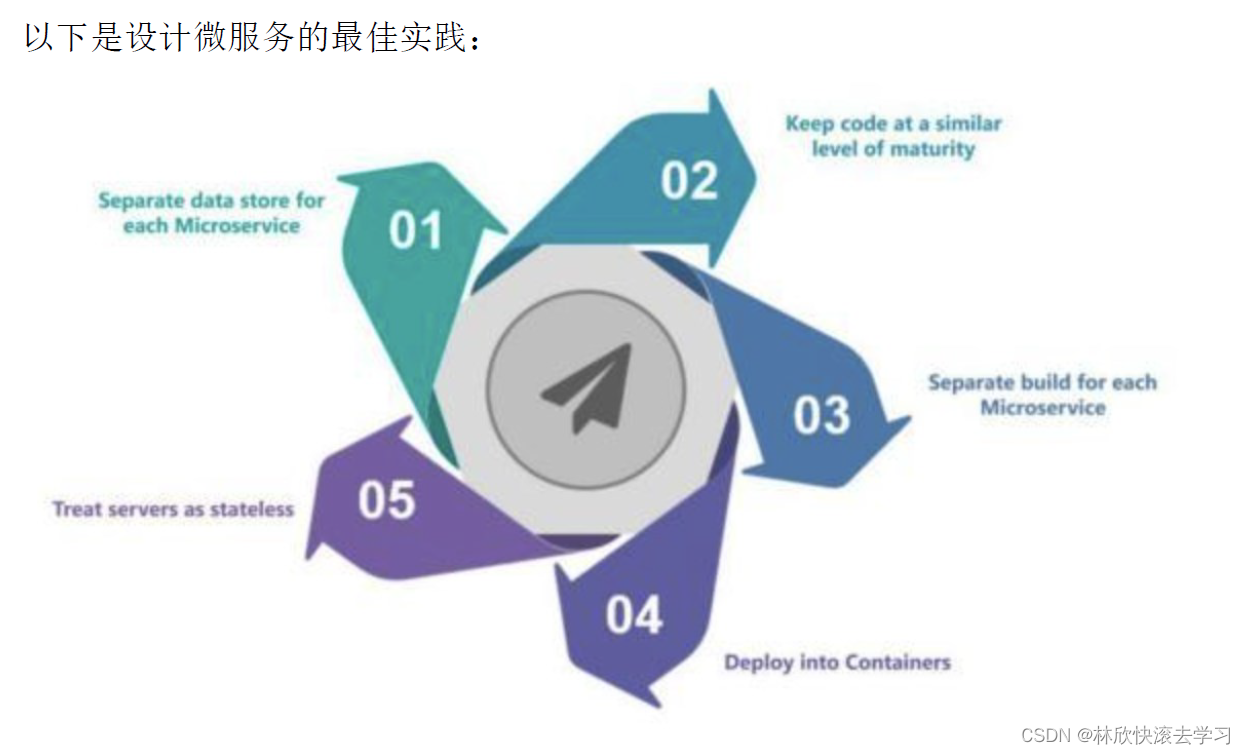
设计微服务的最佳实践是什么?
微服务架构如何运作?
微服务架构具有以下组件:
⚫客户端 – 来自不同设备的不同用户发送请求。
⚫身份提供商 – 验证用户或客户身份并颁发安全令牌。
⚫API 网关 – 处理客户端请求。
⚫静态内容 – 容纳系统的所有内容。
⚫管理 – 在节点上平衡服务并识别故障。
⚫服务发现 – 查找微服务之间通信路径的指南。
⚫网络 – 代理服务器及其数据中心的分布式网络。
⚫远程服务 – 启用驻留在 IT 设备网络上的远程访问信息。

容器技术

Redis

Mysql

LINUX

缓存

网络和操作系统

消息队列

分布式

原文地址:https://blog.csdn.net/m0_73728511/article/details/132720666
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_13711.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!