1 RMDBMS类数据源的实现
1.1 日志抽取模块(Extractor)(0.6.1版本废弃)
我们知道,虽然mysql innodb有自己的log,mysql主备同步是通过binlog来实现的。而binlog同步有三种模式:Row 模式,Statement 模式,Mixed模式。因为statement模式有各种限制,通常生产环境都使用row模式进行复制,使得读取全量日志成为可能。
通常我们的mysql布局是采用 2个master主库(vip)+ 1个slave从库 + 1个backup容灾库 的解决方案,由于容灾库通常是用于异地容灾,实时性不高也不便于部署。
1.2 增量转换模块(Stream)
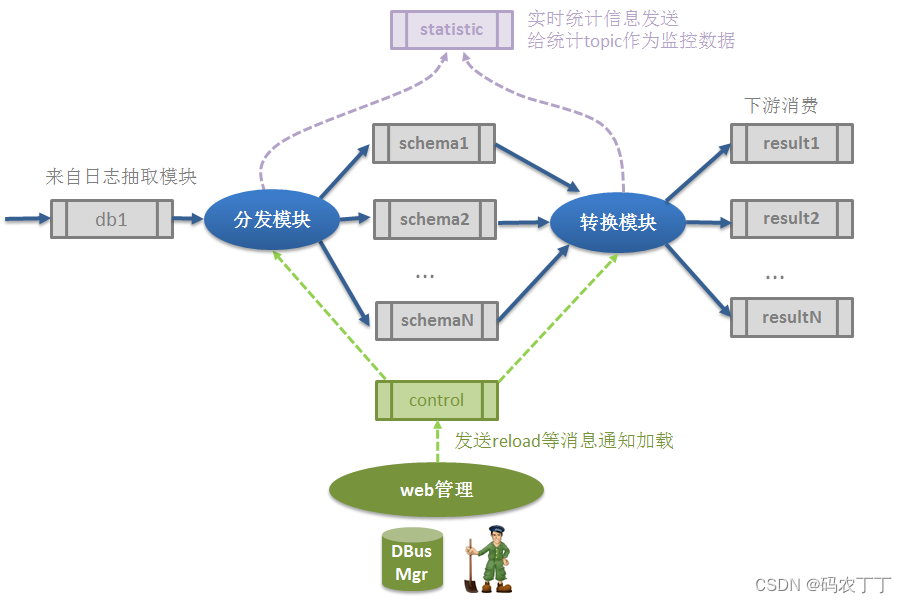
1.3 全量拉取模块(FullPuller)

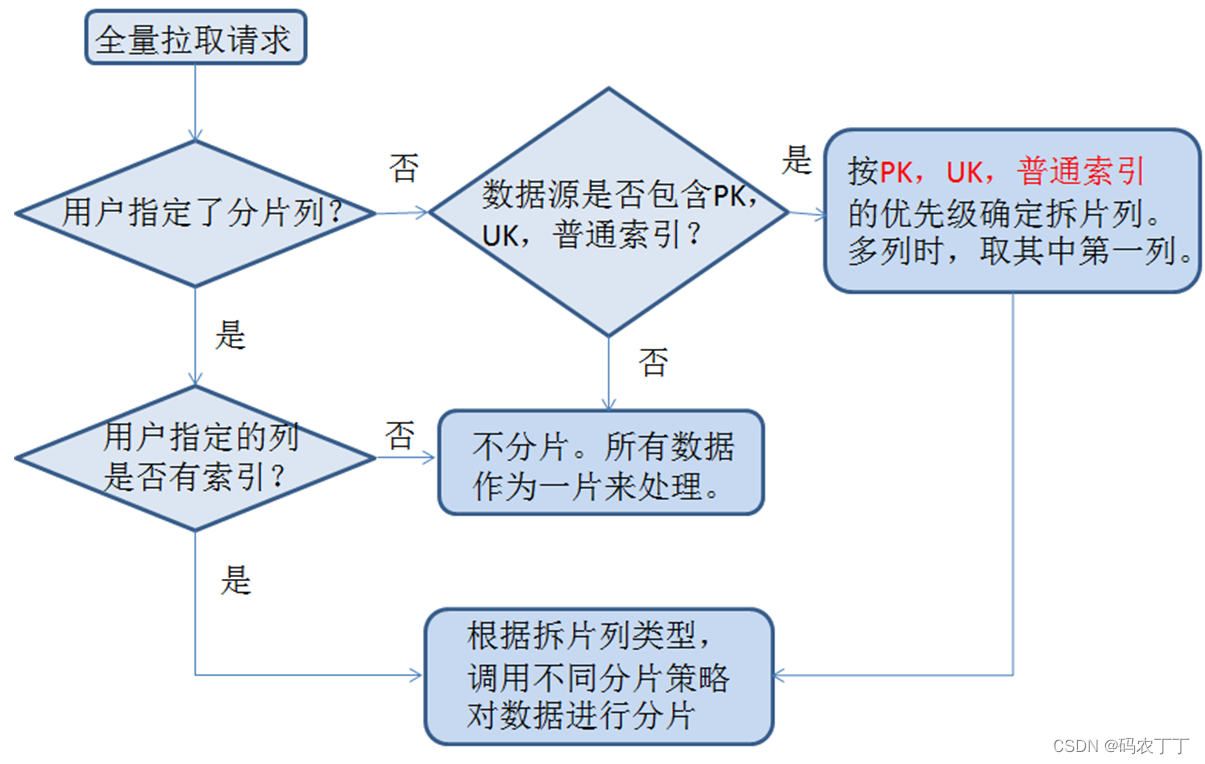
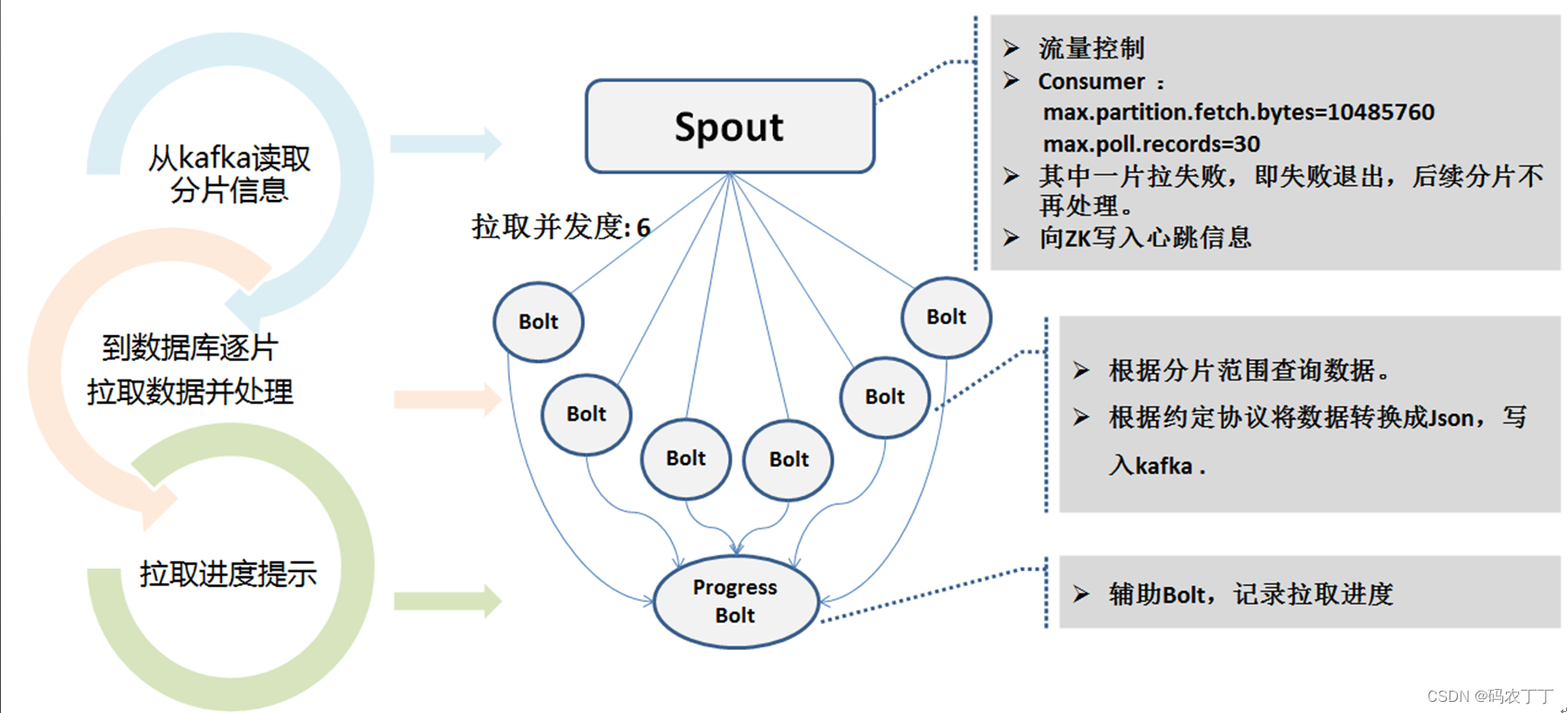
1.3 全量和增量的一致性
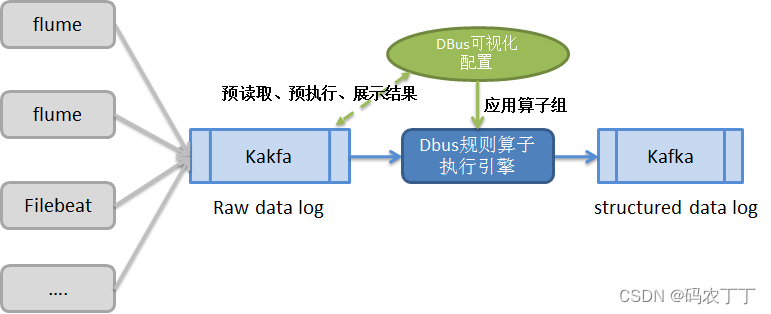
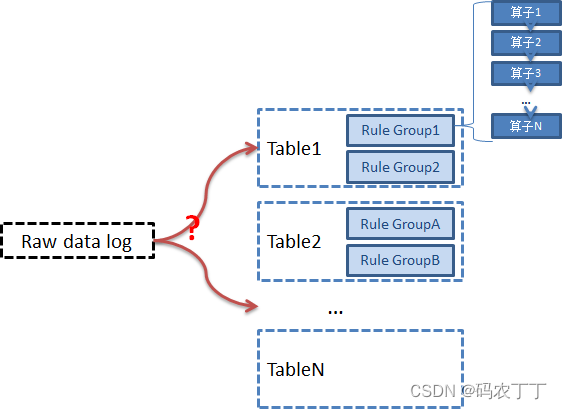
2 日志类数据源的实现

3 UMS统一消息格式

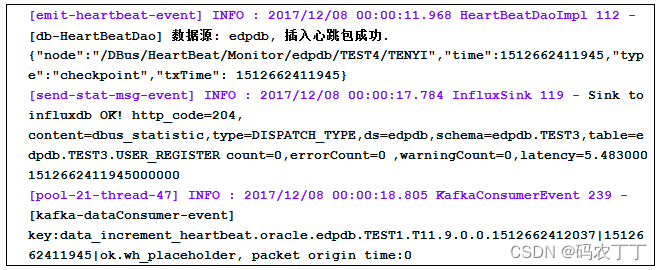
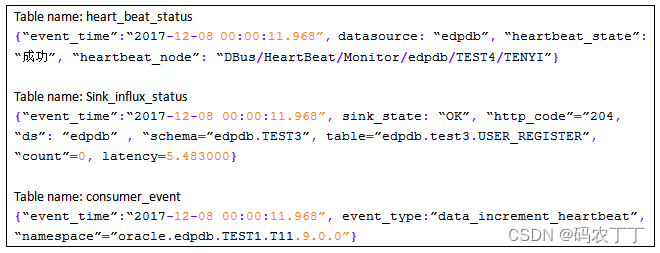
4 心跳监控和预警
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。