遥感领域的通用大模型 2023.11.13在CVPR发表
原文地址:[2311.07113] SpectralGPT: Spectral Foundation Model (arxiv.org)
实验
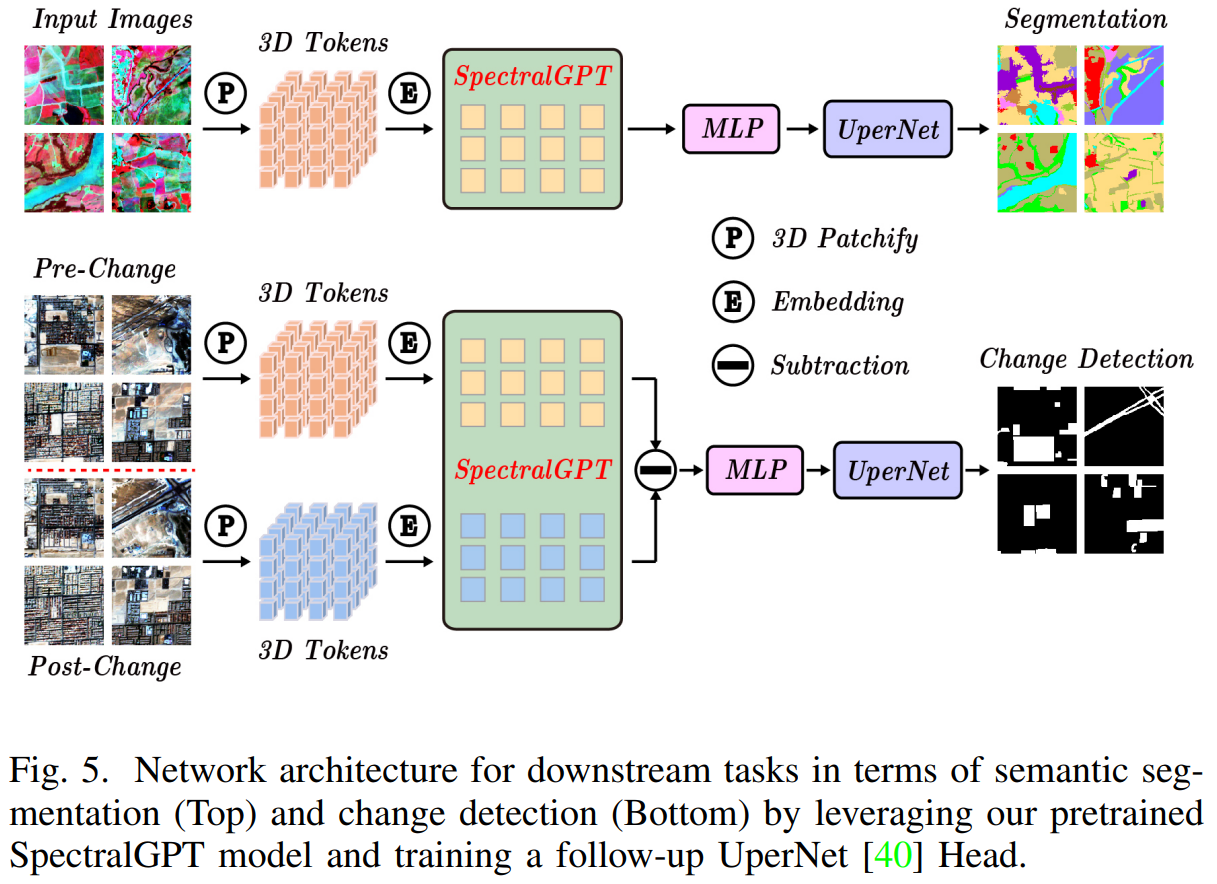
在本节中,我们将严格评估我们的SpectralGPT模型的性能,并对其进行基准测试SOTA基础模型:ResNet50 [36]、SeCo [37]、ViT[22]和SatMAE[30]。此外,我们评估了其在四个下游EO任务中的能力,包括单标签场景分类、多标签场景分类、语义分割和变化检测,以及广泛的消融研究。
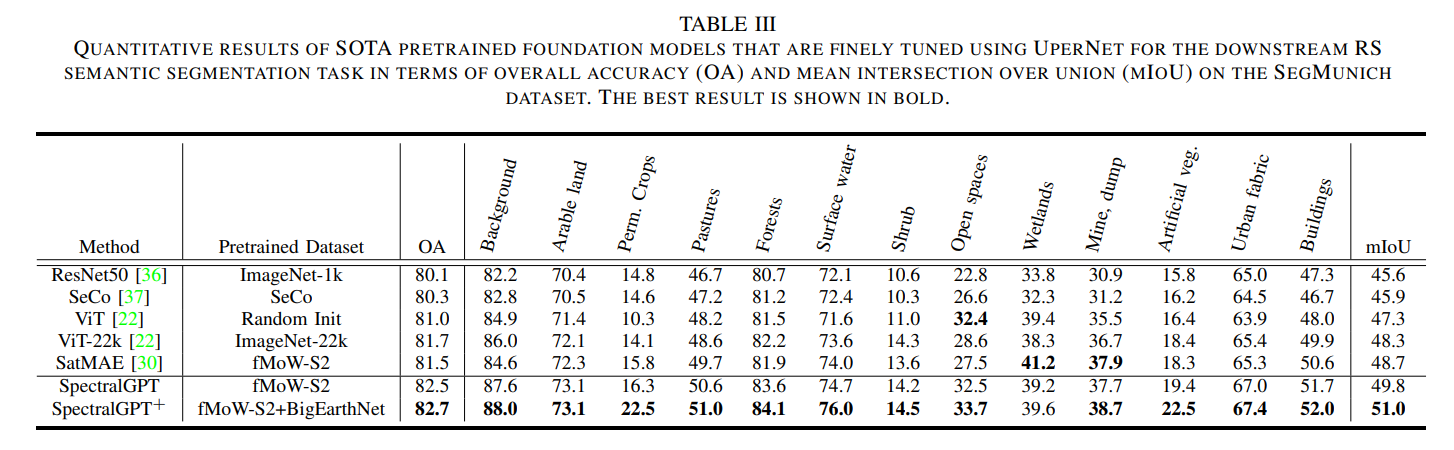
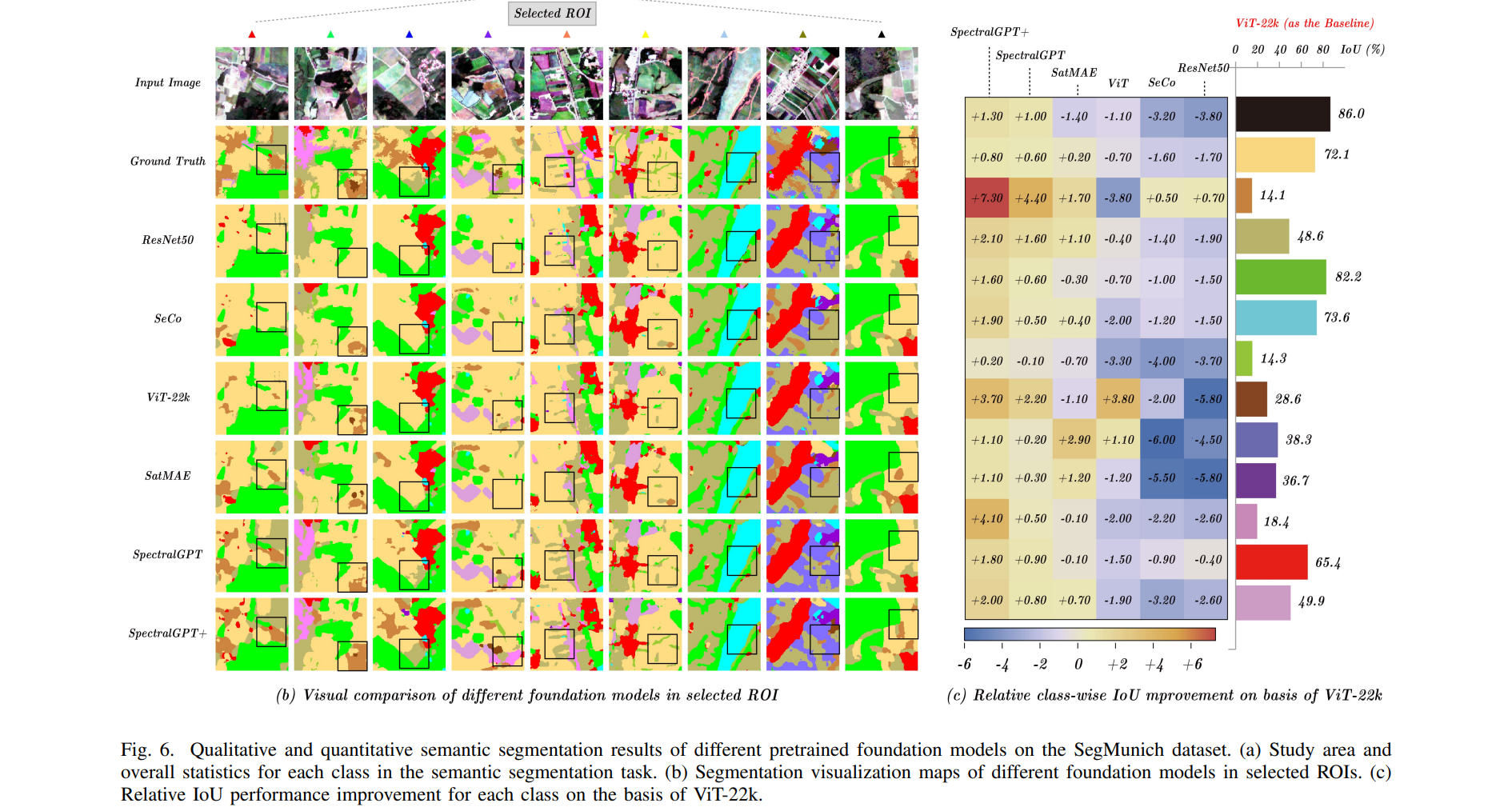
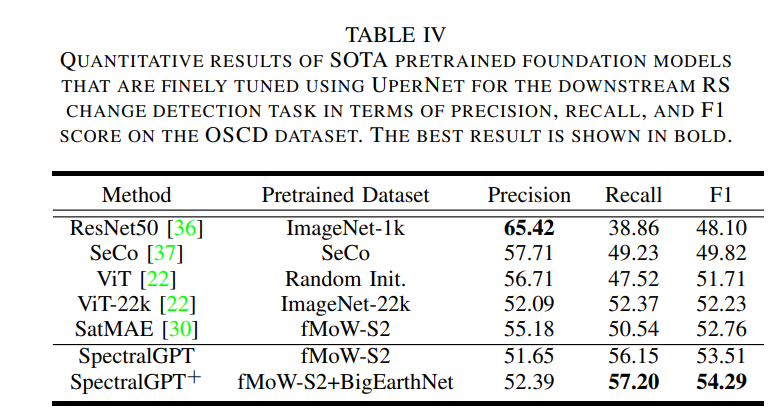
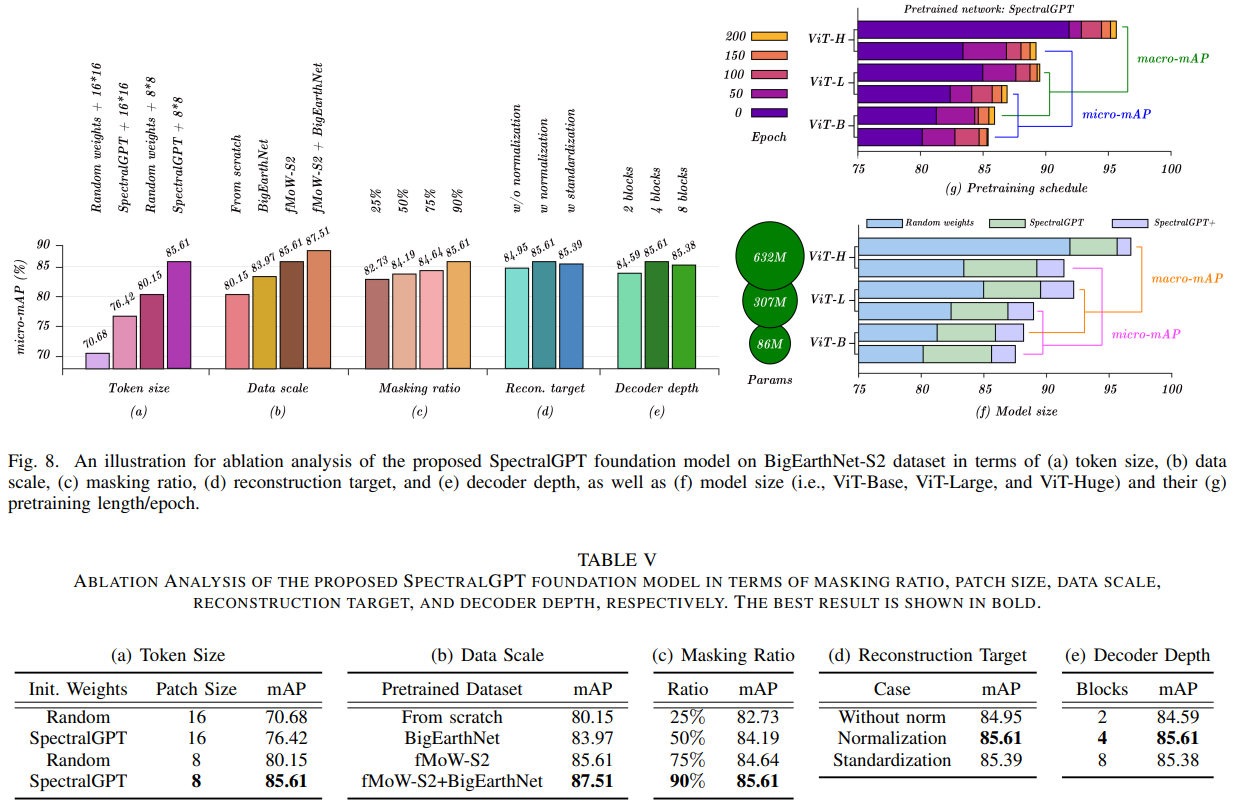
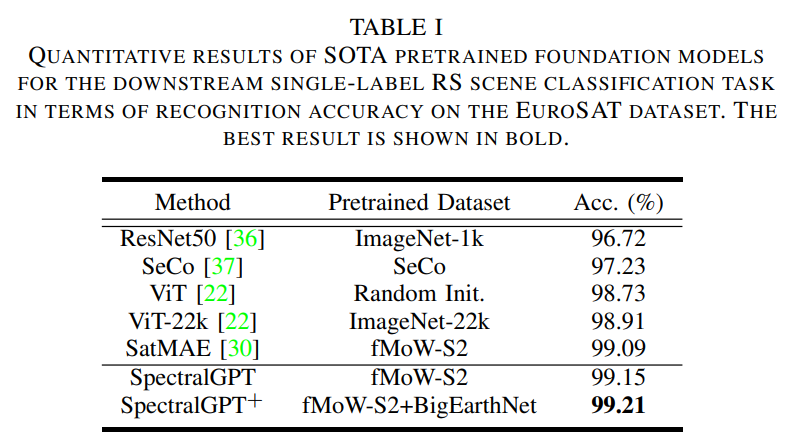
我们定量评估了预训练基础模型在4个下游任务中的性能,包括单标签RS场景分类任务的识别精度、多标签RS场景分类任务的宏观和微观平均精度(mAP),即宏观mAP (micro-mAP)、语义分割任务的总体精度(OA)和平均交联(mIoU),以及变化检测的精度、召回率和F1分数。此外,我们还进行了有见地的消融研究,探索了掩蔽比、解码器深度、模型大小、补丁大小和训练时代等关键因素。利用4个NVIDIA GeForce RTX 4090 gpu的计算能力,我们精心微调下游任务和消融研究的预训练基础模型,从而提供对SpectralGPT在RS域中的能力和适应性的全面见解。
A. EuroSAT上的单标签RS场景分类
对于下游单标签RS场景分类任务,我们使用EuroSAT数据集[38]。这个数据集包括从34个欧洲国家收集的27000张哨兵2号卫星图像。这些图像被分为10个土地使用类别,每个类别包含2000到3000个标记图像。该数据集中的每张图像分辨率为64 × 64像素,包含13个光谱带。值得注意的是,为了与之前的数据处理保持一致,所有图像都排除了B10波段。此外,我们遵循[39]中建议的训练/验证分割。在EuroSAT数据集上,这些预训练的模型经过微调,跨越150个epoch,批量大小为512。这一微调过程采用了基本学习率为2 ×
1
0
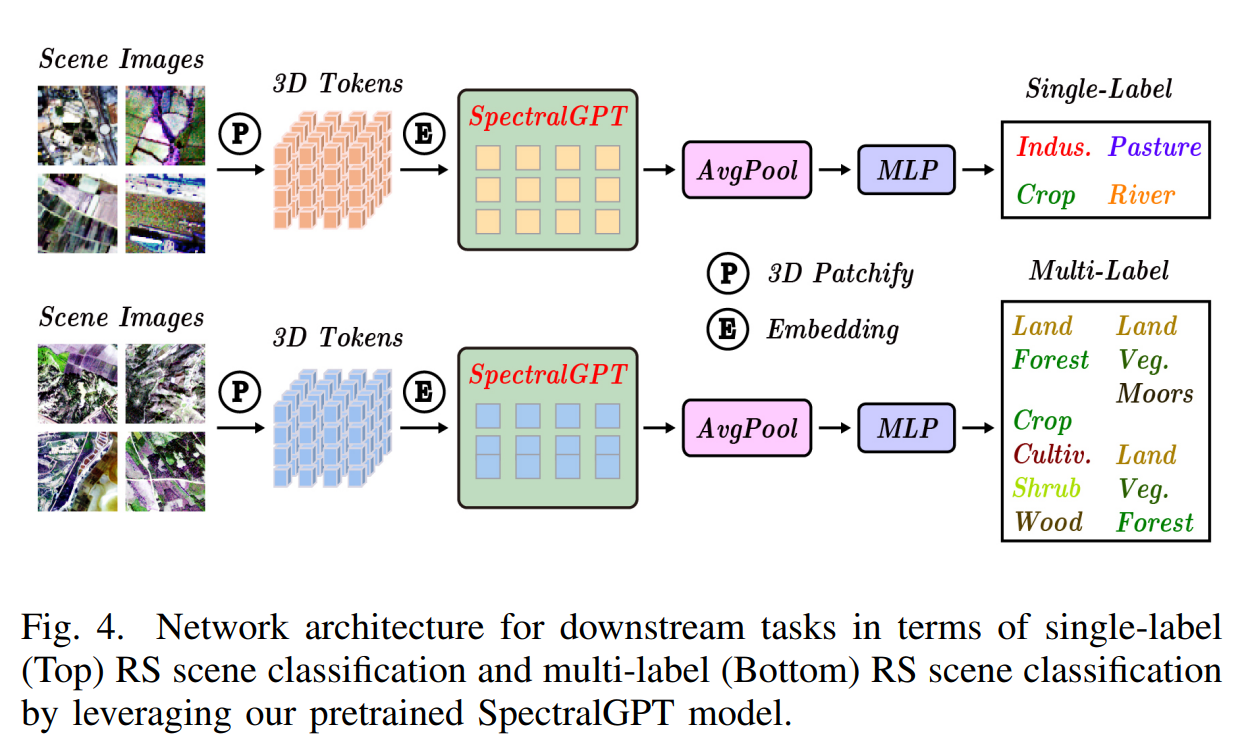
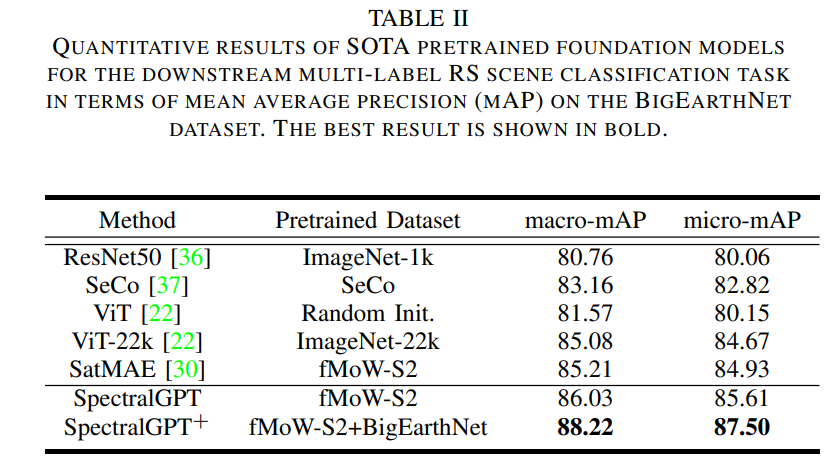
B. BigEarthNet上的多标签遥感场景分类
1
0
−
4
10^{-4}