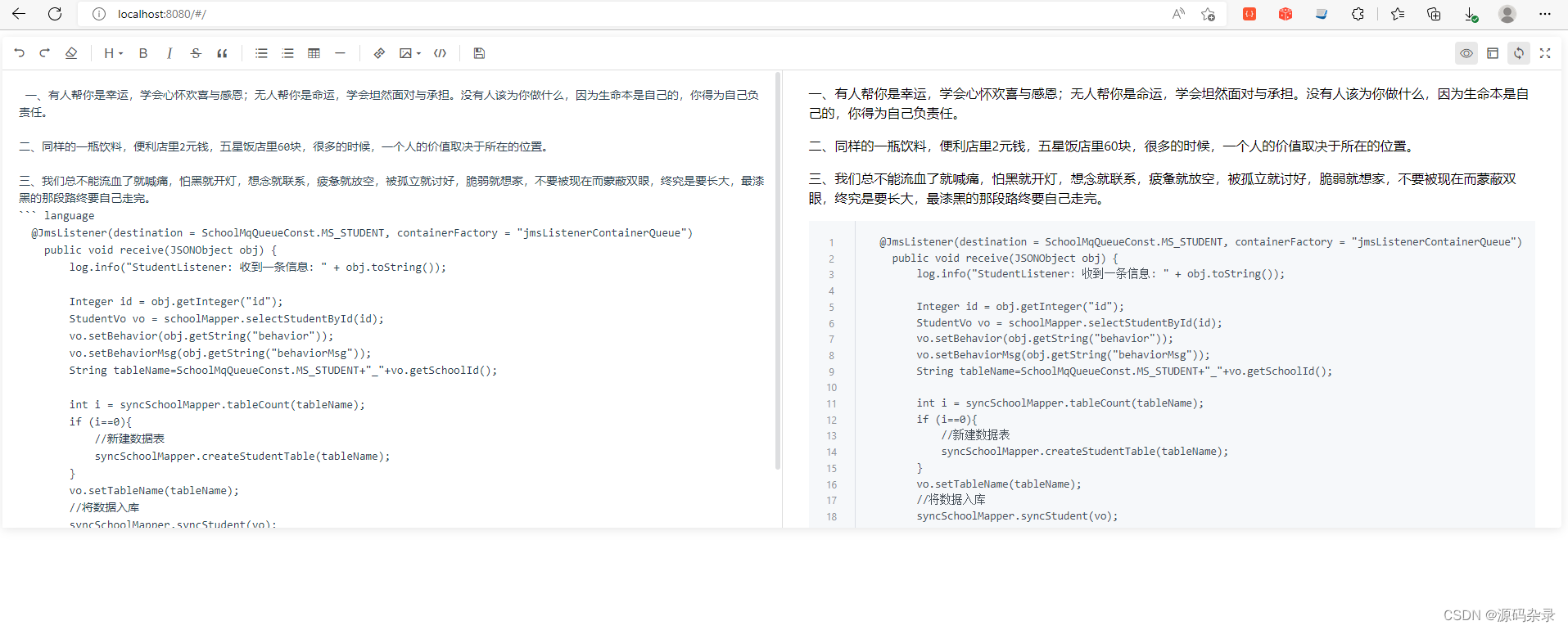
MAV3D 是 Meta AI 研究者们在今年年初提出的一种从文本描述生成三维动态场景的方法。根据文本生成的动态视频可以从任意位置和角度查看,并且可以合成到 3D 环境中。1

一. 预备知识
MAV3D 论文直接阅读会比较困难,本节参考 [论文代码阅读]TensoRF: Tensorial Radiance Fields、[论文阅读]HexPlane: A Fast Representation for Dynamic Scenes、[论文代码阅读]MAKE-A-VIDEO:TEXT-TO-VIDEO GENERATION WITHOUT TEXT-VIDEO DATA,对需要用到的预备知识进行梳理。
1. TensoRF
TensoRF 2 是 ECCV 2022 最具影响力论文,改进了神经辐射场 (NeRF) 的 MLP 表示,将其视为 4D 张量 (tensor) 场(4D 代表 NeRF 的四维输出:RGB +
σ



2. HexPlane


3. MAV
二. 研究思路
1. 场景表示
2. 场景优化
3. 分辨率扩展
4. MAV3D pipeline

三. 场景表示
f
θ
(
x
,
y
,
z
,
t
)
f_{theta}(x,y,z,t)
fθ(x,y,z,t),其中
θ
{
C
t
}
t
=
1
T
{C_t}_{t=1}^{T}
{Ct}t=1T,使用
f
θ
fθ 渲染的图像为
I
t
=
R
(
f
θ
,
t
,
C
t
)
I_t=mathcal{R}(f_{theta},t,C_t)
It=R(fθ,t,Ct),将其堆叠合成视频
V
V
p 和合成视频
V
V
V 传入 T2V 模型,以计算其匹配程度。然后使用 SDS 计算场景参数
θ
theta
四. 场景优化
五. 分辨率扩展
六. 实验结果


七. 总结
-
Chen A, Xu Z, Geiger A, et al. Tensorf: Tensorial radiance fields[C]//European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2022: 333-350. ↩︎
-
Carroll, J.D., Chang, J.J.: Analysis of individual differences in multidimensional scaling via an n-way generalization of “eckart-young” decomposition. Psychometrika 35(3), 283–319 (1970) ↩︎
-
Cao A, Johnson J. Hexplane: A fast representation for dynamic scenes[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 130-141. ↩︎
-
Poole, B., Jain, A., Barron, J. T., and Mildenhall, B. Dream-Fusion: Text-to-3d using 2d diffusion. arXiv, 2022. ↩︎