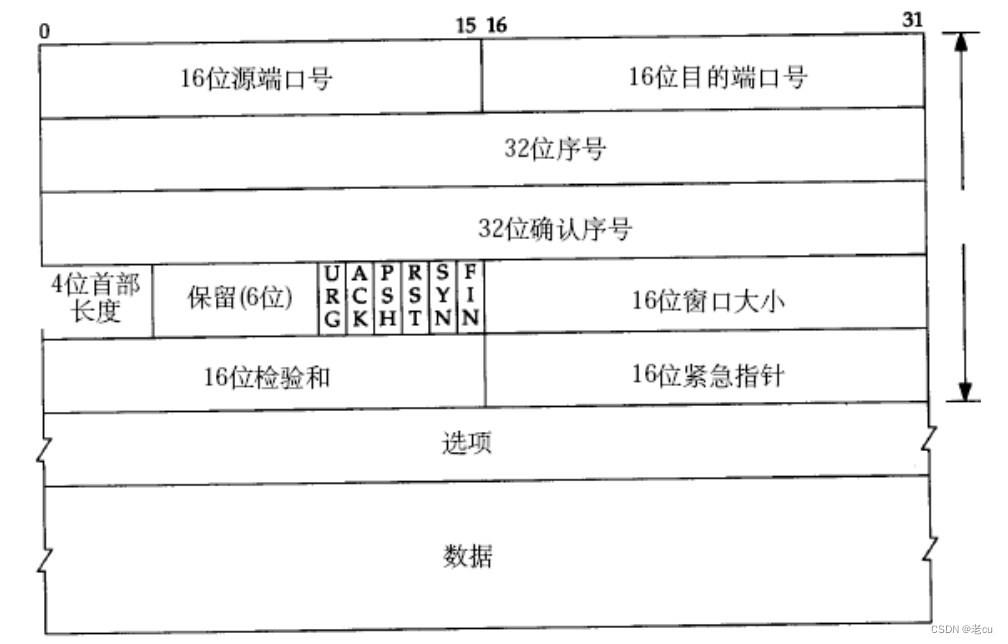
文章目录
- 1. 三次握手
- 2. 四次挥手
- 3. 报文丢失会怎么样
- 4. 为什么每次建立 TCP 连接时,初始化的序列号都要求不一样呢?
- 5. 初始序列号 ISN 是如何随机产生的?
- 6. 什么是 SYN 攻击?如何避免 SYN 攻击?
- 7. 如果已经建立了连接,但是客户端突然出现故障了怎么办?
- 8. 如果已经建立了连接,但是服务端的进程崩溃会发生什么?
- 9. TCP 连接一端崩溃或者宕机会发生什么?
- 7. 使用 TCP 一定不会造成丢包吗?
- 8. TCP 中的数据结构
- 9. Socket 编程
- 10. TCP 可靠传输的工作原理
- 11. TCP 可靠传输的实现
- 12. 聊聊 tcp 的流量控制
- 13. tcp 的拥塞控制的常用方法
- 14. TCP 与 UDP 的分片发生在哪里
1. 三次握手
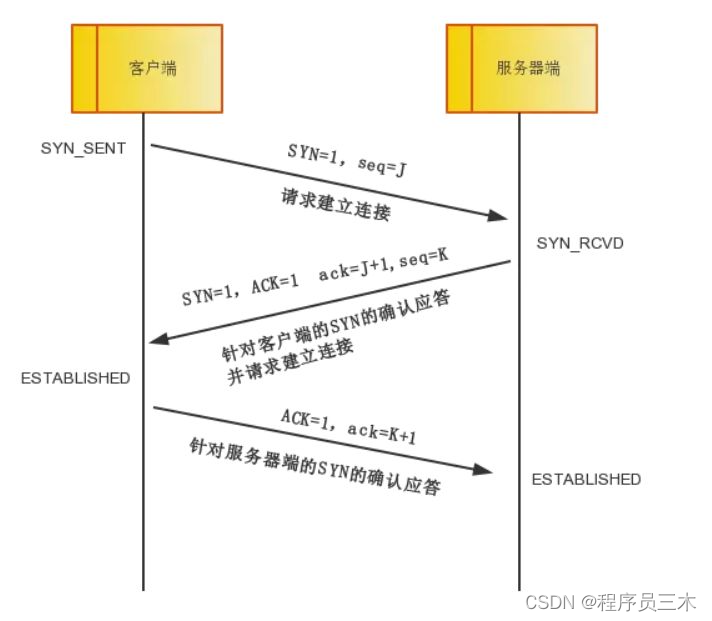
说一下三次握手的过程
第 1 次握手建立连接时,客户端向服务器发送 SYN 报文(SEQ=x,SYN=1),并进入 SYN_SENT 状态,等待服务器确认。
● 服务器收到了客户端的请求,向客户端回复一个确认信息(ACK=x+1)。
● 服务器再向客户端发送一个 SYN 包(SEQ=y)建立连接的请求,此时服务器进入 SYN_RECV 状态。
此时,客户端也要向服务器发送确认包(ACK)。此包发送完毕客户端和服务器进入 ESTABLISHED 状态,完成 3 次握手。
而且值得注意的是,只有报文中的大ACK=1(确认 ACK ACKnowledgment),小ack才有效。
为什么是三次握手
这个问题的本质原因就是,信道不可靠, 因此通信双发需要就某个问题达成一致。
而要解决这个问题, 无论你在消息中包含什么信息, 三次通信是理论上的最小值。所以三次握手是为了满足 “在不可靠信道上进行可靠传输” 这一需求所导致的。
● 「两次握手」:无法防止历史连接的建立,会造成双方资源的浪费,也无法可靠的同步双方序列号;
● 「四次握手」:三次握手就已经理论上最少可靠连接建立,所以不需要使用更多的通信次数。
为什么不能是两次
如果只有两次,为了双方都能进入连接态,只能丢弃 SYN_RCVD中间状态。这样的话,当堵塞于网络中的旧初始化连接请求到来时,服务端会误认为旧连接是正常连接,而进入 established连接状态,导致套接字空等,造成资源浪费。
2. 四次挥手
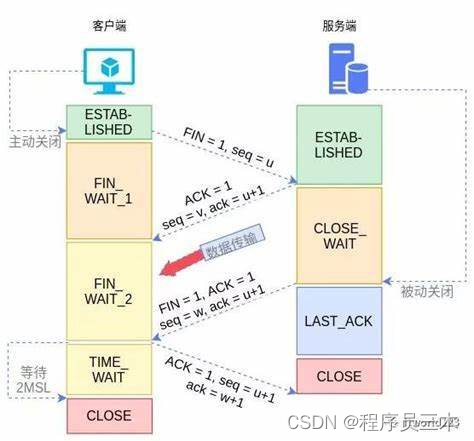
说一下四次挥手的过程
假设存在 client 跟 server 端,挥手请求由 client发起。
第一次挥手: Client 端发起挥手请求,向 Server 端发送标志位是FIN报文段,设置序列号 seq,此时,Client 端进入FIN_WAIT_1状态。表示Client端没有数据要发送给Server端了。
第二次挥手:Server 端收到了 Client 端发送的 FIN 报文段,向 Client 端返回一个标志位是 ACK 的报文段,ack 设为 seq 加1,Client 端进入FIN_WAIT_2状态。表示 Server 端知道 Clent 端关闭连接。
第三次挥手: Server 端向 Client 端发送标志位是 FIN 的报文段,请求关闭连接,同时 Client 端进入LAST_ACK状态。表示 Server 端也没有数据要发送给 Client 了。
第四次挥手 : Client 端收到 Server 端发送的 FIN 报文段,向 Server 端发送确认报文,然后Client端进入TIME_WAIT状态。Server端收到Client端的ACK报文段以后,就关闭连接。Client端等待 2MSL 的时间后依然没有收到回复,则证明Server端已正常关闭,Client 端关闭连接。
为什么需要四次挥手
因为 TCP 是一个全双工的通信协议,也就是说双方可以同时传输数据。而断开连接需要有人发起,有人确认,所以双方都断开连接就需要四次挥手了。
有可能出现三次挥手吗,什么时候会出现呢?
在 Linux 环境开发的时候,通过 tcpdump 进行抓包,可以发现经常会出现 第二次挥手跟第三次挥手合并成为一个报文发送的情况。主要是因为现在 TCP 有延迟确认的机制,且是默认开启的。
为什么 TIME_WAIT 等待的时间是 2MSL?
主要有两个原因,
第二,防止已失效的连接请求报文出现在本连接。因为发送完最后一个 ACK 报文后,再经过 2MSL ,理论上就可以使得本链接所产生的所有报文都从网络中消失。
MSL(Maximum Segment Lifetime),最长报文段寿命。也就是说 MSL 时间内,报文没有到达对端,就认为报文已丢失。
2MSL 可以保证可以接收到重传报文。
为什么需要 TIME_WAIT 状态?
主动发起关闭连接的一方,才会有 TIME-WAIT 状态。
需要 TIME-WAIT 状态,主要是两个原因:
TIME_WAIT 过多有什么危害?
注意:
只有先发起 Fin 报文的端点才会有 TIME_WAIT 状态。
过多的 TIME-WAIT 状态主要的危害有两种:
第二是占用端口资源,端口资源也是有限的,一般可以开启的端口为 32768~61000,也可以通过 net.ipv4.ip_local_port_range参数指定范围。
客户端和服务端 TIME_WAIT 过多,造成的影响是不同的。
如果客户端(主动发起关闭连接方)的 TIME_WAIT 状态过多,占满了所有端口资源,那么就无法对「目的 IP+ 目的 PORT」都一样的服务器发起连接了,但是被使用的端口,还是可以继续对另外一个服务器发起连接的。具体可以看我这篇文章:客户端的端口可以重复使用吗?(opens new window)
因此,客户端(发起连接方)都是和「目的 IP+ 目的 PORT 」都一样的服务器建立连接的话,当客户端的 TIME_WAIT 状态连接过多的话,就会受端口资源限制,如果占满了所有端口资源,那么就无法再跟「目的 IP+ 目的 PORT」都一样的服务器建立连接了。
不过,即使是在这种场景下,只要连接的是不同的服务器,端口是可以重复使用的,所以客户端还是可以向其他服务器发起连接的,这是因为内核在定位一个连接的时候,是通过四元组(源IP、源端口、目的IP、目的端口)信息来定位的,并不会因为客户端的端口一样,而导致连接冲突。
如果服务端(主动发起关闭连接方)的 TIME_WAIT 状态过多,并不会导致端口资源受限,因为服务端只监听一个端口,而且由于一个四元组唯一确定一个 TCP 连接,因此理论上服务端可以建立很多连接,但是 TCP 连接过多,会占用系统资源,比如文件描述符、内存资源、CPU 资源、线程资源等。
如何优化 TIME_WAIT?
这里给出优化 TIME-WAIT 的几个方式,都是有利有弊:
● 打开 net.ipv4.tcp_tw_reuse 和 net.ipv4.tcp_timestamps 选项;
● net.ipv4.tcp_max_tw_buckets
● 程序中使用 SO_LINGER ,应用强制使用 RST 关闭。
方式一:net.ipv4.tcp_tw_reuse 和 tcp_timestamps
如下的 Linux 内核参数开启后,则可以复用处于 TIME_WAIT 的 socket 为新的连接所用。
有一点需要注意的是,tcp_tw_reuse 功能只能用客户端(连接发起方),因为开启了该功能,在调用 connect() 函数时,内核会随机找一个 time_wait 状态超过 1 秒的连接给新的连接复用。
使用这个选项,还有一个前提,需要打开对 TCP 时间戳的支持,即
net.ipv4.tcp_timestamps=1 (默认即为 1)
这个时间戳的字段是在 TCP 头部的「选项」里,它由一共 8 个字节表示时间戳,其中第一个 4 字节字段用来保存发送该数据包的时间,第二个 4 字节字段用来保存最近一次接收对方发送到达数据的时间。
由于引入了时间戳,我们在前面提到的 2MSL 问题就不复存在了,因为重复的数据包会因为时间戳过期被自然丢弃。
这个值默认为 18000,当系统中处于 TIME_WAIT 的连接一旦超过这个值时,系统就会将后面的 TIME_WAIT 连接状态重置,这个方法比较暴力。
我们可以通过设置 socket 选项,来设置调用 close 关闭连接行为。
struct linger so_linger;
so_linger.l_onoff = 1;
so_linger.l_linger = 0;
setsockopt(s, SOL_SOCKET, SO_LINGER, &so_linger,sizeof(so_linger));
如果l_onoff为非 0, 且l_linger值为 0,那么调用close后,会立该发送一个RST标志给对端,该 TCP 连接将跳过四次挥手,也就跳过了TIME_WAIT状态,直接关闭。
但这为跨越TIME_WAIT状态提供了一个可能,不过是一个非常危险的行为,不值得提倡。
前面介绍的方法都是试图越过 TIME_WAIT状态的,这样其实不太好。虽然 TIME_WAIT 状态持续的时间是有一点长,显得很不友好,但是它被设计来就是用来避免发生乱七八糟的事情。
《UNIX网络编程》一书中却说道:TIME_WAIT 是我们的朋友,它是有助于我们的,不要试图避免这个状态,而是应该弄清楚它。
如果服务端要避免过多的 TIME_WAIT 状态的连接,就永远不要主动断开连接,让客户端去断开,由分布在各处的客户端去承受 TIME_WAIT。
3. 报文丢失会怎么样
源于 [小林coding]
第一次握手报文丢失
当客户端想和服务端建立 TCP 连接的时候,首先第一个发的就是 SYN 报文,然后进入到 SYN_SENT 状态。
在这之后,如果客户端迟迟收不到服务端的 SYN-ACK 报文(第二次握手),就会触发「超时重传」机制,重传 SYN 报文,而且重传的 SYN 报文的序列号都是一样的。
不同版本的操作系统可能超时时间不同,有的 1 秒的,也有 3 秒的,这个超时时间是写死在内核里的,如果想要更改则需要重新编译内核,比较麻烦。
当客户端在 1 秒后没收到服务端的 SYN-ACK 报文后,客户端就会重发 SYN 报文,那到底重发几次呢?
在 Linux 里,客户端的 SYN 报文最大重传次数由 tcp_syn_retries内核参数控制,这个参数是可以自定义的,默认值一般是 5。
# cat /proc/sys/net/ipv4/tcp_syn_retries
centos 7.x 是6
通常,第一次超时重传是在 1 秒后,第二次超时重传是在 2 秒,第三次超时重传是在 4 秒后,第四次超时重传是在 8 秒后,第五次是在超时重传 16 秒后。没错,每次超时的时间是上一次的 2 倍。
当第五次超时重传后,会继续等待 32 秒,如果服务端仍然没有回应 ACK,客户端就不再发送 SYN 包,然后断开 TCP 连接。
所以,总耗时是 1+2+4+8+16+32=63 秒,大约 1 分钟左右。
第二次握手报文丢失
当服务端收到客户端的第一次握手后,就会回 SYN-ACK 报文给客户端,这个就是第二次握手,此时服务端会进入 SYN_RCVD 状态。
第二次握手的 SYN-ACK 报文其实有两个目的 :
● 第二次握手里的 ACK, 是对第一次握手的确认报文;
● 第二次握手里的 SYN,是服务端发起建立 TCP 连接的报文;
所以,如果第二次握手丢了,就会发生比较有意思的事情,具体会怎么样呢?
因为第二次握手报文里是包含对客户端的第一次握手的 ACK 确认报文,所以,如果客户端迟迟没有收到第二次握手,那么客户端就觉得可能自己的 SYN 报文(第一次握手)丢失了,于是客户端就会触发超时重传机制,重传 SYN 报文。
然后,因为第二次握手中包含服务端的 SYN 报文,所以当客户端收到后,需要给服务端发送 ACK 确认报文(第三次握手),服务端才会认为该 SYN 报文被客户端收到了。
那么,如果第二次握手丢失了,服务端就收不到第三次握手,于是服务端这边会触发超时重传机制,重传 SYN-ACK 报文。
在 Linux 下,SYN-ACK 报文的最大重传次数由 tcp_synack_retries内核参数决定,默认值是 5。
# cat /proc/sys/net/ipv4/tcp_synack_retries
因此,当第二次握手丢失了,客户端和服务端都会重传:
● 客户端会重传 SYN 报文,也就是第一次握手,最大重传次数由 tcp_syn_retries内核参数决定;
● 服务端会重传 SYN-ACK 报文,也就是第二次握手,最大重传次数由 tcp_synack_retries 内核参数决定。
注:tcp_syn_retries 一般比 tcp_synack_retries稍微大一点。
第三次握手报文丢失
客户端收到服务端的 SYN-ACK 报文后,就会给服务端回一个 ACK 报文,也就是第三次握手,此时客户端状态进入到 ESTABLISH 状态。
因为这个第三次握手的 ACK 是对第二次握手的 SYN 的确认报文,所以当第三次握手丢失了,如果服务端那一方迟迟收不到这个确认报文,就会触发超时重传机制,重传 SYN-ACK 报文,直到收到第三次握手,或者达到最大重传次数。
注意,ACK 报文是不会有重传的,当 ACK 丢失了,就由对方重传对应的报文。
第一次挥手报文丢失
当客户端(主动关闭方)调用 close 函数后,就会向服务端发送 FIN 报文,试图与服务端断开连接,此时客户端的连接进入到 FIN_WAIT_1 状态。
正常情况下,如果能及时收到服务端(被动关闭方)的 ACK,则会很快变为 FIN_WAIT_2 状态。
如果第一次挥手丢失了,那么客户端迟迟收不到被动方的 ACK 的话,也就会触发超时重传机制,重传 FIN 报文,重发次数由 tcp_orphan_retries 参数控制。
# cat /proc/sys/net/ipv4/tcp_orphan_retries
当客户端重传 FIN 报文的次数超过 tcp_orphan_retries 后,就不再发送 FIN 报文,则会在等待一段时间(时间为上一次超时时间的 2 倍),如果还是没能收到第二次挥手,那么直接进入到 close 状态。
第二次挥手报文丢失
当服务端收到客户端的第一次挥手后,就会先回一个 ACK 确认报文,此时服务端的连接进入CLOSE_WAIT 状态。
在前面我们也提了,ACK 报文是不会重传的,所以如果服务端的第二次挥手丢失了,客户端就会触发超时重传机制,重传 FIN 报文,直到收到服务端的第二次挥手,或者达到最大的重传次数。
第三次挥手报文丢失
当服务端(被动关闭方)收到客户端(主动关闭方)的 FIN 报文后,内核会自动回复 ACK,同时连接处于 CLOSE_WAIT 状态,顾名思义,它表示等待应用进程调用 close 函数关闭连接。
此时,内核是没有权利替代进程关闭连接,必须由进程主动调用 close 函数来触发服务端发送 FIN 报文。
服务端处于 CLOSE_WAIT 状态时,调用了 close 函数,内核就会发出 FIN 报文,同时连接进入 LAST_ACK 状态,等待客户端返回 ACK 来确认连接关闭。
如果迟迟收不到这个 ACK,服务端就会重发 FIN 报文,重发次数仍然由 tcp_orphan_retries 参数控制,这与客户端重发 FIN 报文的重传次数控制方式是一样的。
第四次挥手报文丢失
当客户端收到服务端的第三次挥手的 FIN 报文后,就会回 ACK 报文,也就是第四次挥手,此时客户端连接进入 TIME_WAIT 状态。
在 Linux 系统,TIME_WAIT 状态会持续 2MSL 后才会进入关闭状态。
然后,服务端(被动关闭方)没有收到 ACK 报文前,还是处于 LAST_ACK 状态。
如果第四次挥手的 ACK 报文没有到达服务端,服务端就会重发 FIN 报文,重发次数仍然由前面介绍过的 tcp_orphan_retries 参数控制。
报文丢失重传达到最大次数之后,会发生什么?
假设重传的最大次数是3.
如果重传三次后还未收到该报文的确认,那么就不再尝试重传,直接发送 reset 报文重置该TCP连接,但有些要求很高的业务应用系统,则会不断的重传被丢弃的报文,以尽最大可能保证业务数据的正常交互。
4. 为什么每次建立 TCP 连接时,初始化的序列号都要求不一样呢?
主要原因有两个方面:
● 为了防止历史报文被下一个相同四元组的连接接收(主要方面);
● 为了安全性,防止黑客伪造的相同序列号的 TCP 报文被对方接收;
5. 初始序列号 ISN 是如何随机产生的?
起始 ISN 是基于时钟的,每 4 微秒 + 1,转一圈要 4.55 个小时。
RFC793 提到初始化序列号 ISN 随机生成算法:ISN = M + F(localhost, localport, remotehost, remoteport)。
● M 是一个计时器,这个计时器每隔 4 微秒加 1。
● F 是一个 Hash 算法,根据源 IP、目的 IP、源端口、目的端口生成一个随机数值。要保证 Hash 算法不能被外部轻易推算得出,用 MD5 算法是一个比较好的选择。
可以看到,随机数是会基于时钟计时器递增的,基本不可能会随机成一样的初始化序列号。
6. 什么是 SYN 攻击?如何避免 SYN 攻击?
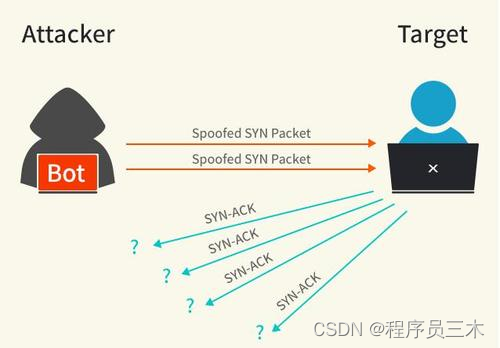
我们都知道 TCP 连接建立是需要三次握手,假设攻击者短时间伪造不同 IP 地址的 SYN 报文,服务端每接收到一个 SYN 报文,就进入SYN_RCVD 状态,但服务端发送出去的 ACK + SYN 报文,无法得到未知 IP 主机的 ACK 应答,久而久之就会占满服务端的半连接队列,使得服务器不能为正常用户服务。
避免 SYN 攻击方式,可以有以下四种方法:
● 调大 netdev_max_backlog;
● 增大 TCP 半连接队列;
● 开启 tcp_syncookies;
● 减少 SYN+ACK 重传次数
方式一:调大 netdev_max_backlog
当网卡接收数据包的速度大于内核处理的速度时,会有一个队列保存这些数据包。控制该队列的最大值如下参数,默认值是 1000,我们要适当调大该参数的值,比如设置为 10000:
net.core.netdev_max_backlog = 10000
方式二:增大 TCP 半连接队列
增大 TCP 半连接队列,要同时增大下面这三个参数:
● 增大 net.ipv4.tcp_max_syn_backlog
● 增大 listen() 函数中的 backlog
● 增大 net.core.somaxconn
具体为什么是三个参数决定 TCP 半连接队列的大小,可以看这篇:可以看这篇:TCP 半连接队列和全连接队列满了会发生什么?又该如何应对?(opens new window)
方式三:开启 net.ipv4.tcp_syncookies
开启 syncookies 功能就可以在不使用 SYN 半连接队列的情况下成功建立连接,相当于绕过了 SYN 半连接来建立连接。
具体过程:
● 当 「 SYN 队列」满之后,后续服务器收到 SYN 包,不会丢弃,而是根据算法,计算出一个 cookie 值;
● 将 cookie 值放到第二次握手报文的「序列号」里,然后服务端回第二次握手给客户端;
● 服务端接收到客户端的应答报文时,服务器会检查这个 ACK 包的合法性。如果合法,将该连接对象放入到「 Accept 队列」。
● 最后应用程序通过调用 accpet() 接口,从「 Accept 队列」取出的连接。
可以看到,当开启了 tcp_syncookies 了,即使受到 SYN 攻击而导致 SYN 队列满时,也能保证正常的连接成功建立。
net.ipv4.tcp_syncookies 参数主要有以下三个值:
● 0 值,表示关闭该功能;
● 1 值,表示仅当 SYN 半连接队列放不下时,再启用它;
● 2 值,表示无条件开启功能;
那么在应对 SYN 攻击时,只需要设置为 1 即可。
$ echo 1 > /proc/sys/net/ipv4/tcp_syncookies
方式四:减少 SYN+ACK 重传次数
当服务端受到 SYN 攻击时,就会有大量处于 SYN_REVC 状态的 TCP 连接,处于这个状态的 TCP 会重传 SYN+ACK ,当重传超过次数达到上限后,就会断开连接。
那么针对 SYN 攻击的场景,我们可以减少 SYN-ACK 的重传次数,以加快处于 SYN_REVC 状态的 TCP 连接断开。
SYN-ACK 报文的最大重传次数由 tcp_synack_retries内核参数决定(默认值是 5 次),比如将 tcp_synack_retries 减少到 2 次:
$ echo 2 > /proc/sys/net/ipv4/tcp_synack_retries
7. 如果已经建立了连接,但是客户端突然出现故障了怎么办?
TCP 有一个机制是保活机制。这个机制的原理是这样的:
定义一个时间段,在这个时间段内,如果没有任何连接相关的活动,TCP 保活机制会开始作用,每隔一个时间间隔,发送一个探测报文,该探测报文包含的数据非常少,如果连续几个探测报文都没有得到响应,则认为当前的 TCP 连接已经死亡,系统内核将错误信息通知给上层应用程序。
注意:
我们也可以像websocket 通信那样,自己实现心跳机制来实现。
在 Linux 内核可以有对应的参数可以设置保活时间、保活探测的次数、保活探测的时间间隔,以下都为默认值:
● tcp_keepalive_time=7200:表示保活时间是 7200 秒(2小时),也就 2 小时内如果没有任何连接相关的活动,则会启动保活机制
● tcp_keepalive_intvl=75:表示每次检测间隔 75 秒;
● tcp_keepalive_probes=9:表示检测 9 次无响应,认为对方是不可达的,从而中断本次的连接。
注意,应用程序若想使用 TCP 保活机制需要通过 socket 接口设置 SO_KEEPALIVE 选项才能够生效,如果没有设置,那么就无法使用 TCP 保活机制。
如果开启了 TCP 保活,需要考虑以下几种情况:
● 第一种,对端程序是正常工作的。当 TCP 保活的探测报文发送给对端, 对端会正常响应,这样 TCP 保活时间会被重置,等待下一个 TCP 保活时间的到来。
● 第二种,对端程序崩溃并重启。当 TCP 保活的探测报文发送给对端后,对端是可以响应的,但由于没有该连接的有效信息,会产生一个 RST 报文,这样很快就会发现 TCP 连接已经被重置。
● 第三种,是对端程序崩溃,或对端由于其他原因导致报文不可达。当 TCP 保活的探测报文发送给对端后,石沉大海,没有响应,连续几次,达到保活探测次数后,TCP 会报告该 TCP 连接已经死亡。
8. 如果已经建立了连接,但是服务端的进程崩溃会发生什么?
TCP 的连接信息是由内核维护的,所以当服务端的进程崩溃后,内核需要回收该进程的所有 TCP 连接资源,于是内核会发送第一次挥手 FIN 报文,后续的挥手过程也都是在内核完成,并不需要进程的参与,所以即使服务端的进程退出了,还是能与客户端完成 TCP四次挥手的过程。
我自己做了个实验,使用 kill -9 来模拟进程崩溃的情况,发现在 kill 掉进程后,服务端会发送 FIN 报文,与客户端进行四次挥手。
9. TCP 连接一端崩溃或者宕机会发生什么?
如果「客户端进程崩溃」,客户端的进程在发生崩溃的时候,内核会发送 FIN 报文,与服务端进行四次挥手。
但是,「客户端主机宕机」,那么是不会发生四次挥手的,具体后续会发生什么?还要看服务端会不会发送数据?
● 如果服务端会发送数据,由于客户端已经不存在,收不到数据报文的响应报文,服务端的数据报文会超时重传,当重传总间隔时长达到一定阈值(内核会根据 tcp_retries2 设置的值计算出一个阈值)后,会断开 TCP 连接;
● 如果服务端一直不会发送数据,再看服务端有没有开启 TCP keepalive 机制?
○ 如果有开启,服务端在一段时间没有进行数据交互时,会触发 TCP keepalive 机制,探测对方是否存在,如果探测到对方已经消亡,则会断开自身的 TCP 连接;
○ 如果没有开启,服务端的 TCP 连接会一直存在,并且一直保持在 ESTABLISHED 状态。
7. 使用 TCP 一定不会造成丢包吗?
● 数据从发送端到接收端,链路很长,任何一个地方都可能发生丢包,几乎可以说丢包不可避免。
● 平时没事也不用关注丢包,大部分时候TCP的重传机制保证了消息可靠性。
● 当你发现服务异常的时候,比如接口延时很高,总是失败的时候,可以用ping或者mtr命令看下是不是中间链路发生了丢包。
● TCP只保证传输层的消息可靠性,并不保证应用层的消息可靠性。如果我们还想保证应用层的消息可靠性,就需要应用层自己去实现逻辑做保证。
8. TCP 中的数据结构
队列
半连接和全连接队列
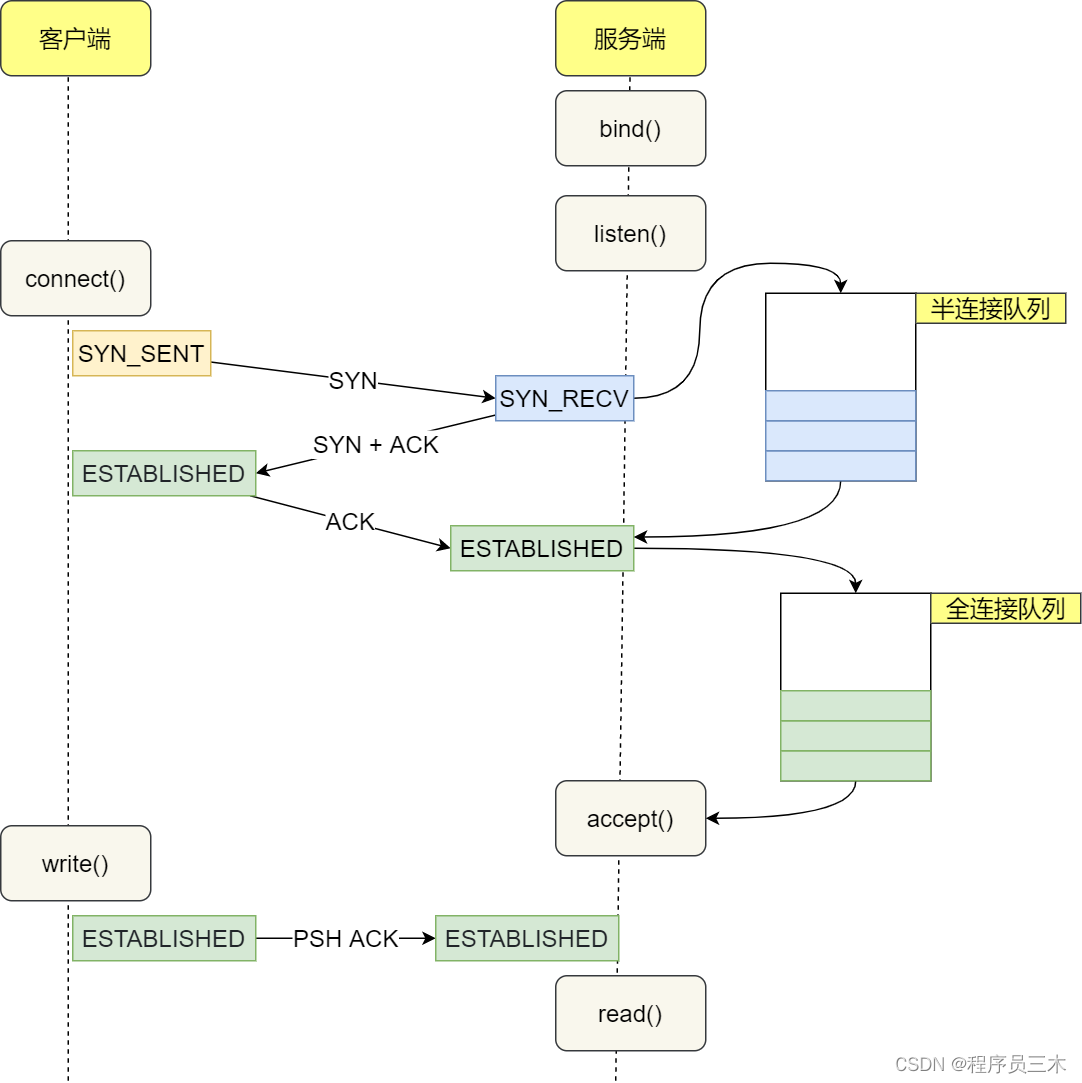
在 TCP 三次握手的时候,Linux 内核会维护两个队列,分别是:
● 半连接队列,也称 SYN 队列;
● 全连接队列,也称 accept 队列;
服务端收到客户端发起的 SYN 请求后,内核会把该连接存储到半连接队列,并向客户端响应 SYN+ACK,接着客户端会返回 ACK,服务端收到第三次握手的 ACK 后,内核会把连接从半连接队列移除,然后创建新的完全的连接,并将其添加到 accept 队列,等待进程调用 accept 函数时把连接取出来。
不管是半连接队列还是全连接队列,都有最大长度限制,超过限制时,内核会直接丢弃,或返回 RST 包。
链表
双向链表
https://blog.51cto.com/u_13045346/4553142
9. Socket 编程
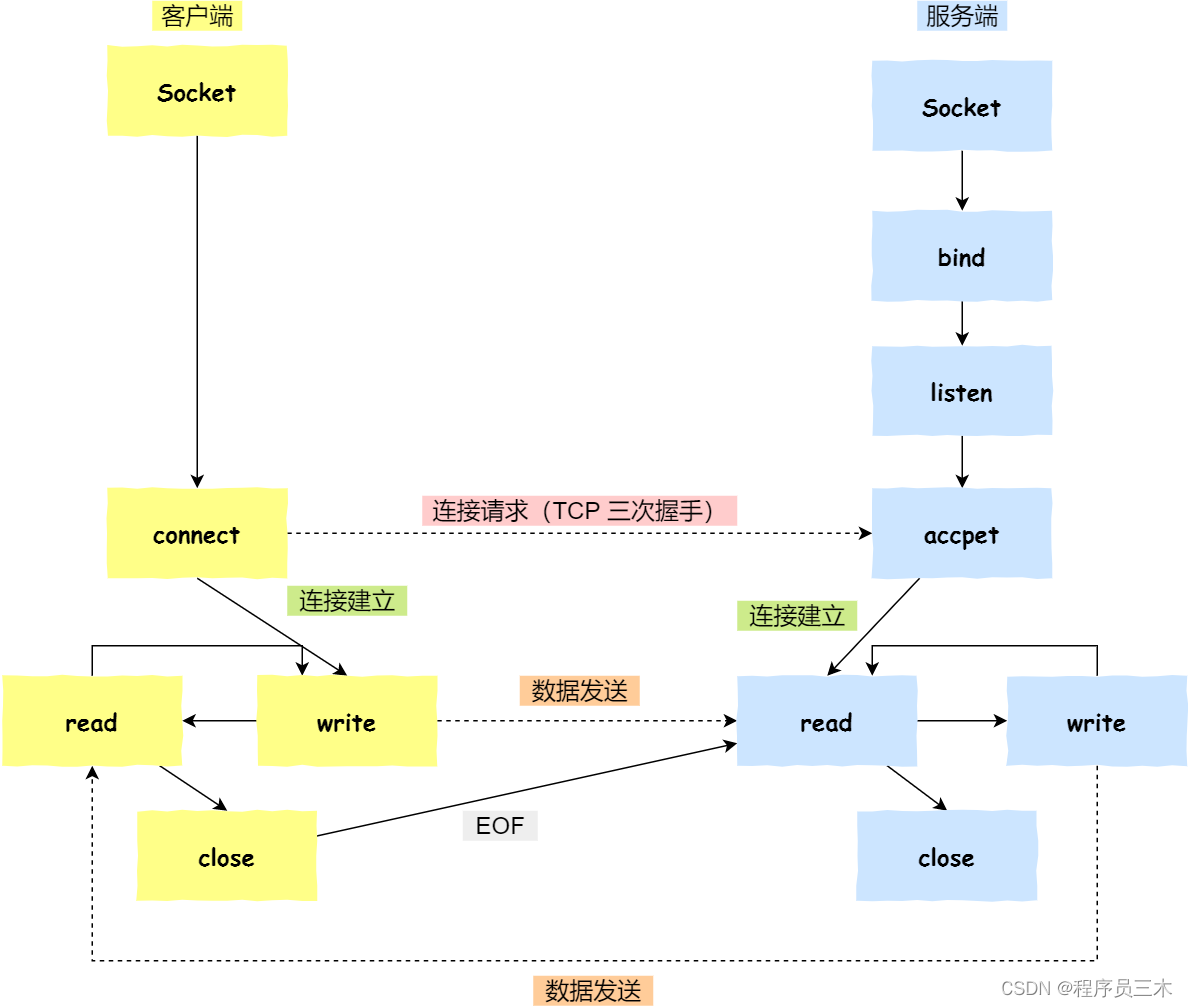
针对 TCP 应该如何 Socket 编程?
● 服务端和客户端初始化 socket,得到文件描述符;
● 服务端调用 bind,将 socket 绑定在指定的 IP 地址和端口;
● 服务端调用 listen,进行监听;
● 服务端调用 accept,等待客户端连接;
● 客户端调用 connect,向服务器端的地址和端口发起连接请求;
● 服务端 accept 返回用于传输的 socket 的文件描述符;
● 客户端调用 write 写入数据;服务端调用 read 读取数据;
● 客户端断开连接时,会调用 close,那么服务端 read 读取数据的时候,就会读取到了 EOF,待处理完数据后,服务端调用 close,表示连接关闭。
这里需要注意的是,服务端调用 accept 时,连接成功了会返回一个已完成连接的 socket,后续用来传输数据。
所以,监听的 socket 和真正用来传送数据的 socket,是「两个」 socket,一个叫作监听 socket,一个叫作已完成连接 socket。
成功连接建立之后,双方开始通过 read 和 write 函数来读写数据,就像往一个文件流里面写东西一样。
listen 的时候参数 backlog 的意义?
Linux内核中会维护两个队列:
● 半连接队列(SYN 队列):接收到一个 SYN 建立连接请求,处于 SYN_RCVD 状态;
● 全连接队列(Accpet 队列):已完成 TCP 三次握手过程,处于 ESTABLISHED 状态;
int listen (int socketfd, int backlog)
● 参数一 socketfd 为 socketfd 文件描述符
● 参数二 backlog,这参数在历史版本有一定的变化
在早期 Linux 内核 backlog 是 SYN 队列大小,也就是未完成的队列大小。
在 Linux 内核 2.2 之后,backlog 变成 accept 队列,也就是已完成连接建立的队列长度,所以现在通常认为 backlog 是 accept 队列。
但是上限值是内核参数 somaxconn 的大小,也就说 accpet 队列长度 = min(backlog, somaxconn)。
accept 发生在三次握手的哪一步?
我们先看看客户端连接服务端时,发送了什么?
● 客户端的协议栈向服务器端发送了 SYN 包,并告诉服务器端当前发送序列号 client_isn,客户端进入 SYN_SENT 状态;
● 服务器端的协议栈收到这个包之后,和客户端进行 ACK 应答,应答的值为 client_isn+1,表示对 SYN 包 client_isn 的确认,同时服务器也发送一个 SYN 包,告诉客户端当前我的发送序列号为 server_isn,服务器端进入 SYN_RCVD 状态;
● 客户端协议栈收到 ACK 之后,使得应用程序从 connect 调用返回,表示客户端到服务器端的单向连接建立成功,客户端的状态为 ESTABLISHED,同时客户端协议栈也会对服务器端的 SYN 包进行应答,应答数据为 server_isn+1;
● ACK 应答包到达服务器端后,服务器端的 TCP 连接进入 ESTABLISHED 状态,同时服务器端协议栈使得 accept 阻塞调用返回,这个时候服务器端到客户端的单向连接也建立成功。至此,客户端与服务端两个方向的连接都建立成功。
从上面的描述过程,我们可以得知客户端 connect 成功返回是在第二次握手,服务端 accept 成功返回是在三次握手成功之后。
客户端调用 close 了,连接是断开的流程是什么?
我们看看客户端主动调用了 close,会发生什么?
● 客户端调用 close,表明客户端没有数据需要发送了,则此时会向服务端发送 FIN 报文,进入 FIN_WAIT_1 状态;
● 服务端接收到了 FIN 报文,TCP 协议栈会为 FIN 包插入一个文件结束符 EOF 到接收缓冲区中,应用程序可以通过 read 调用来感知这个 FIN 包。这个 EOF 会被放在已排队等候的其他已接收的数据之后,这就意味着服务端需要处理这种异常情况,因为 EOF 表示在该连接上再无额外数据到达。此时,服务端进入 CLOSE_WAIT 状态;
● 接着,当处理完数据后,自然就会读到 EOF,于是也调用 close 关闭它的套接字,这会使得服务端发出一个 FIN 包,之后处于 LAST_ACK 状态;
● 客户端接收到服务端的 FIN 包,并发送 ACK 确认包给服务端,此时客户端将进入 TIME_WAIT 状态;
● 服务端收到 ACK 确认包后,就进入了最后的 CLOSE 状态;
● 客户端经过 2MSL 时间之后,也进入 CLOSE 状态;
10. TCP 可靠传输的工作原理
tcp 发送的报文段是交给 ip 层传送的,但是 IP 层只能提供尽最大努力服务(不可靠)。
首先,可靠传输意味着 无差错,不丢失,不重复,不乱序。那么接下来我也会从这几个方面来介绍可靠传输的工作原理。
1. 为了解决数据差错问题,TCP 的校验数据部分包含首部和数据,而 ip 层只校验首部。
2. 为了解决数据丢失问题,TCP 数据时,会设置一个超时计时器,超时没有收到确认报文则会重传当前报文。
3. 为了解决数据重复问题,TCP 有确认迟到的机制,也就是说,当 TCP 收到重复报文的同时,还会发送确认报文。
4. 为了解决数据乱序问题, TCP 首部存在每个报文唯一的4字节序号。
而在这基本思想的发展上,tcp 出现了一系列的可靠传输协议,比如说:停止等待协议,连续 ARQ 协议。
连续 ARQ 采用的是滑动窗口的算法思想,达到累积确认的目的。
11. TCP 可靠传输的实现
数据报的唯一编号是基于操作系统的时钟生成的。
以字节为单位的滑动窗口 + 超时重传的时间选择 + 选择确认(SACK)(可选的,需要双方商定)。
12. 聊聊 tcp 的流量控制
流量控制,属于点对点问题,在 tcp 主要是利用滑动窗口的思想,双方就窗口的大小进行协商,避免数据包传输过快或过慢。
13. tcp 的拥塞控制的常用方法
首先,拥塞代表着对资源的总需求量大于可用资源,而且拥塞导致丢包引起的重传会加剧拥塞程度,拥塞控制的目的就是避免过多的数据包注入到网络中。而TCP中为了减少拥塞带来的损失,采用以下四种方法。
● 1. 慢开始
每个传输轮次,加倍
● 2. 拥塞避免
传输轮次+1
● 3. 快重传
发送方连续收到三个某个报文的确认,就认为该报文没有被接收方收到,立即进行重传。
● 4. 快恢复
缩小拥塞窗口门限后立即执行拥塞避免。
14. TCP 与 UDP 的分片发生在哪里
首先,提到分片,我们需要聊一聊 MTU,它是链路层中的网络对数据帧的一个限制,以以太网为例,MTU为1500个字节。一个IP数据报在以太网中传输,如果它的长度大于该MTU值,就要进行分片传输,使得每片数据报的长度小于MTU。分片传输的IP数据报不一定按序到达,但IP首部中的信息能让这些数据报片按序组装。IP数据报的分片与重组是在网络层进完成的。
UDP数据报,由于UDP数据报不会自己进行分片,当UDP数据长度超过了MTU时,会在网络层进行IP分片。
对于TCP来说,它是尽量避免分片的,为什么?因为如果在IP层进行分片了话,如果其中的某片的数据丢失了,对于保证可靠性的TCP协议来说,会增大重传数据包的机率,而且只能重传整个TCP分组。因此当TCP数据大于MTU时,会在传输层进行分段,然后再进入网络层。
TCP 报文里面有个长度可变的选项字段,其最初只有一个 MSS(Maxiumum Segment Size),是每个 TCP 报文段里的数据字段的最大长度。
原文地址:https://blog.csdn.net/qq_45704048/article/details/134627268
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_15071.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!