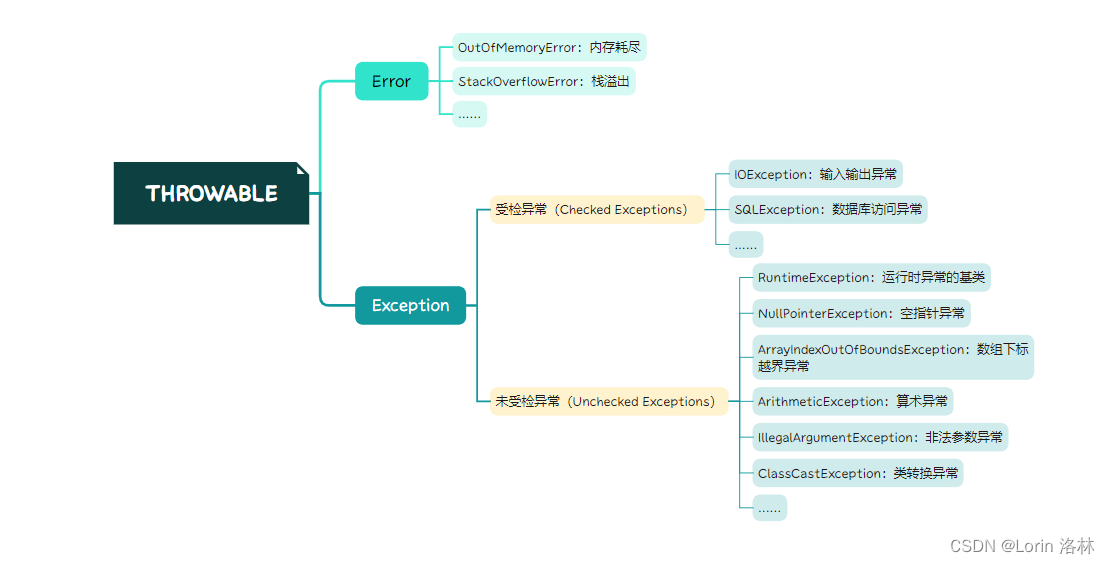
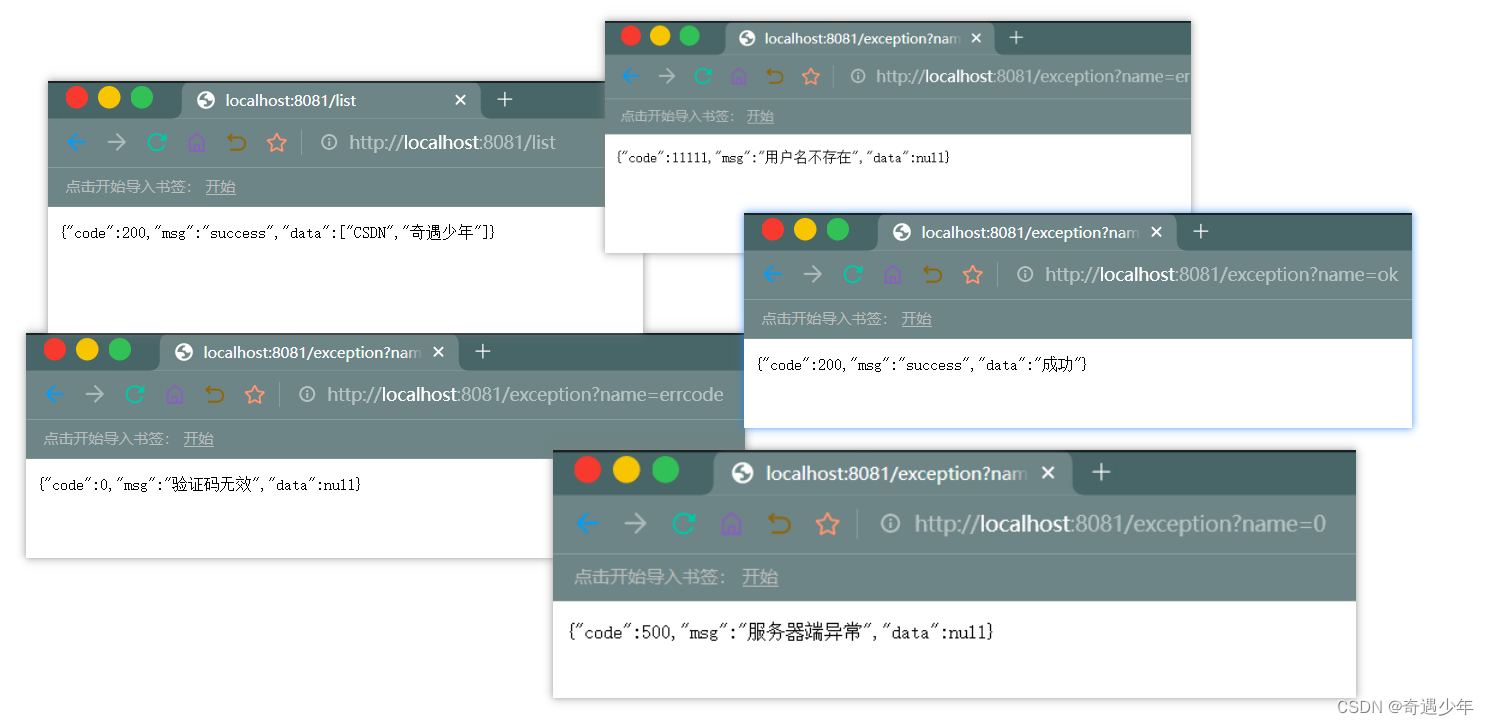
本文介绍: 【强制】捕获异常是为了处理它,不要捕获了却什么都不处理而抛弃之,如果不想处理它,请。随意复制和粘贴代码,必然会导致代码的重复,在以后需要修改时,需要修改所有的副。【强制】业务上具有唯一特性的字段,即使是多个字段的组合,也必须建成唯一索引。另外,即使在应用层做了非常完善的校验控制,只要没有唯一索引,根据墨菲定律,必。【强制】异常不要用来做流程控制,条件控制,因为异常的处理效率比条件分支低。【强制】捕获异常与抛异常,必须是完全匹配,或者捕获异常是抛异常的父类。必要时抽取共性方法,或者抽象公共类,甚至是组件化。
内容。
滚事务。
(二)MYSQL
原文地址:https://blog.csdn.net/hongyucai/article/details/134628280
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_15105.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。