本文介绍: 我这里是为了防止sink的文件过于零碎, 但因为使用的memory channel, 缓存时间过长容易丢数据。默认启动时-Xmx20m, 过于小了, 加大堆内存可以直接放开。下载JindoSDK(连接OSS依赖), 下载地址。2. 进阶配置, 根据自己情况按需配置。3. Flume JVM参数。修改Hadoop配置,
安装环境
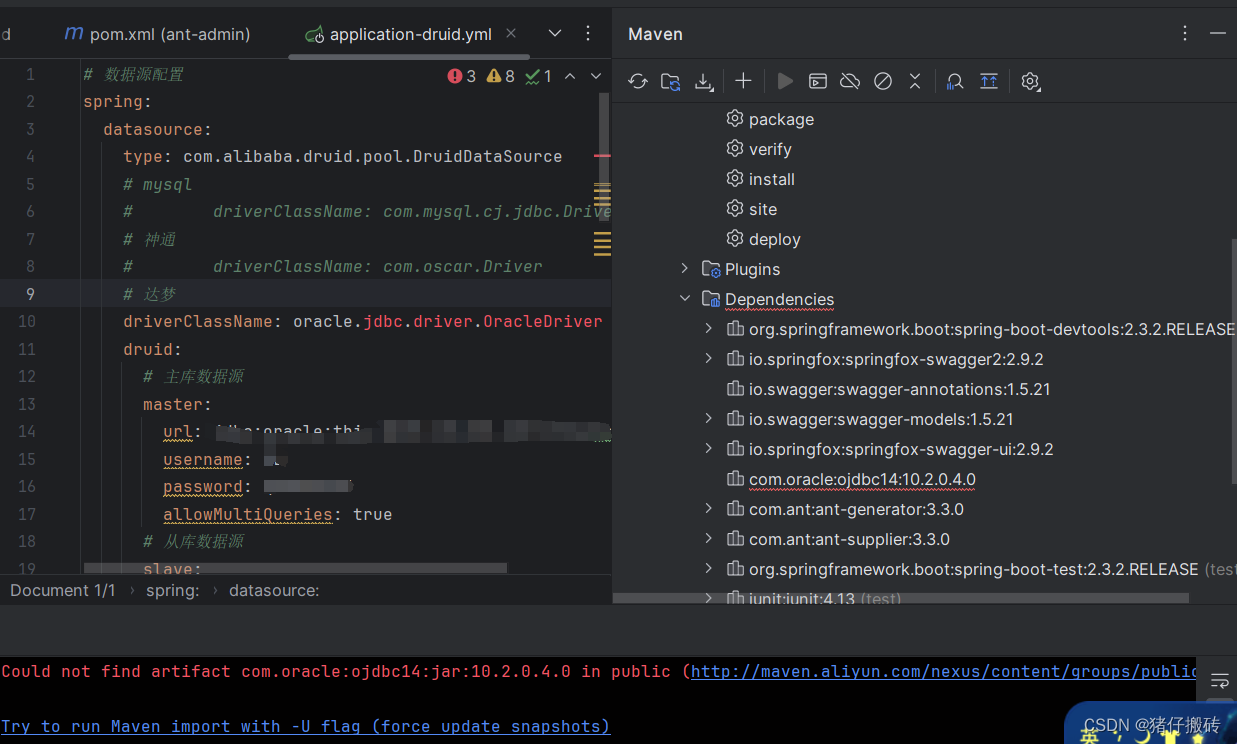
配置Hadoop
下载JindoSDK(连接OSS依赖), 下载地址Github
解压后配置环境变量
配置Flume
此部分全文最关键, 请仔细看
可参考使用Flume同步EMR Kafka集群的数据至OSS-HDFS服务
2. 进阶配置, 根据自己情况按需配置
我这里是为了防止sink的文件过于零碎, 但因为使用的memory channel, 缓存时间过长容易丢数据
3. Flume JVM参数
默认启动时-Xmx20m, 过于小了, 加大堆内存可以直接放开flume-env.sh内JAVA_OPTS的注释
XX启动!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
![[技术杂谈]如何下载vscode历史版本](https://img-blog.csdnimg.cn/direct/18e927e78e82496e80649940eb70a716.png)