1. Raft 初探
宏观角度说明raft在程序中的作用,和客户端的关系,以及多个副本之间的关系。
Raft会以库(Library)的形式存在于服务中。如果你有一个基于Raft的多副本服务,那么每个服务的副本将会由两部分组成:应用程序代码和Raft库,应用程序代码接收RPC或者其他客户端请求,不同节点的Raft库之间相互合作,来维护多副本之间的操作同步。从软件的角度来看一个Raft节点的上层,是应用程序代码。应用程序通常都有状态,Raft层会帮助应用程序将其状态拷贝到其他副本节点。例如:Key-Value数据库对应的状态就是Key-Value Table。应用程序往下,就是Raft层。Key-Value数据库需要对Raft层进行函数调用,来传递自己的状态和Raft反馈的信息。Raft本身也会保持状态,Raft的状态中,最重要的就是Raft会记录操作的日志。
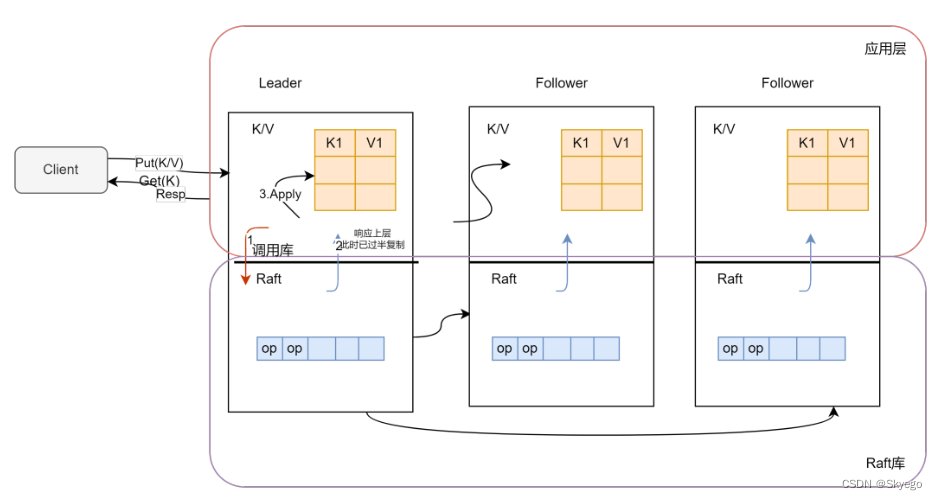
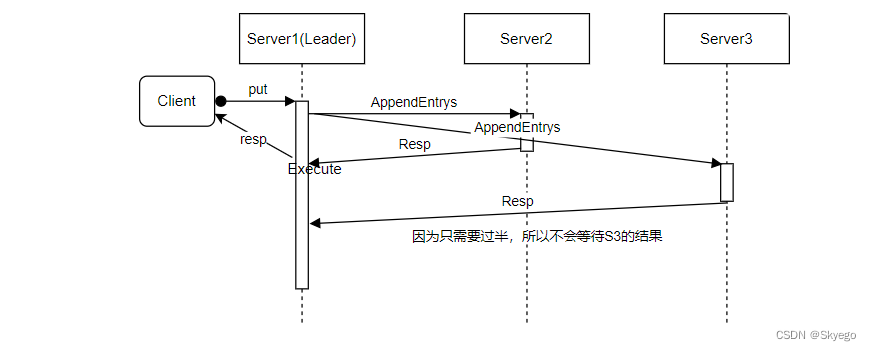
对于一个拥有三个副本的系统来说,很明显我们会有三个服务器,这三个服务器有完全一样的结构(上面是应用程序层,下面是Raft层)。理想情况下,也会有完全相同的数据分别存在于两层(应用程序层和Raft层)中。除此之外,还有一些客户端,假设我们有了客户端1(C1),客户端2(C2)等等。客户端就是一些外部程序代码,它们想要使用服务,同时它们不知道,也没有必要知道,它们正在与一个多副本服务交互。从客户端的角度来看,这个服务与一个单点服务没有区别。
客户端会将请求发送给当前Raft集群中的Leader节点对应的应用程序。这里的请求就是应用程序级别的请求,例如一个访问Key-Value数据库的请求。这些请求可能是Put也可能是Get。Put请求带了一个Key和一个Value,将会更新Key-Value数据库中,Key对应的Value;而Get向当前服务请求某个Key对应的Value。看起来似乎没有Raft什么事,就像是普通的客户端服务端交互。一旦一个Put请求从客户端发送到了服务端,对于一个单节点的服务来说,应用程序会直接执行这个请求,更新Key-Value表,之后返回对于这个Put请求的响应。但是对于一个基于Raft的多副本服务,就要复杂一些。