初衷
gdb调试是每一个后端开发工程师所必备的技能,我们工作总是会用gdb协助我们去分析和调试问题。但是大部分同学的技能仅停留在最基础的查看问题。即gdb program –>r –> 问题复现 –> bt 查看源码中的哪一行出现了错误。再稍微熟练点的,可能就是p var查看一下变量的值,进一步协助排查。
我想说的是,这点能力是完全不够的,身边一些同事稍微遇到一点问题,就不知道如何进行调试了。比如:
- 问题不是必现,一直等待会耗费人力
一旦遇到这些问题,大部分肯定都会一脸懵逼,不知道该怎么办了。但是我认为:作为后端开发工程师,gdb 调试是必备技能,这个技能应该是一个能力集,不仅仅是会几个gdb 调试指令即可,而是在这个过程中,遇到任何问题,都应该能够独立分析解决。这也是我写本篇文章的初心。
目标平台没有gdb怎么办
嵌入式平台的资源有限,很多厂家并不会将gdb 等工具集成到设备中。这就导致很多新手同学,不知道该怎么办了。犹记得刚毕业,我天马行空的居然尝试将虚拟机中的gdb copy 到目标设备中,期待能够正常使用(现在想想,真心觉得傻得可爱。【申明一下哈,有可能会成功哦,前提是你的开发设备和目标设备都是相同的架构】)。
遇到这种情况,我们一般都需要重新编译gdb 工具。有兴趣的同学可以参考这篇文章,应该算是较为详细。工作中如何编译开源工具(gdb)_gdb编译_谢艺华的博客-CSDN博客。
coredump
我们在开发调试过程中,若一直使用gdb进行调试,这对于测试和开发而言会不太方便,影响效率。特别是在压力测试的场景中。如何解决这一难题呢?我们可以使用linux自带的coredump机制。
Coredump叫做核心转储,它是进程运行时在突然崩溃的那一刻的一个内存快照。操作系统在程序发生异常而异常在进程内部又没有被捕获的情况下,会把进程此刻内存、寄存器状态、运行堆栈等信息转储保存在一个文件里。
但是这个机制默认可能是没有开启的,因为一旦开启后,会对系统赞成较大的压力。开启方式有两种:
系统设置
执行ulimit –c查看coredump 是否开启,若结果为0,则认为没有启动coredump文件生成。需要进行打开。
1. 临时启用:ulimit –c 1024或ulimit –c unlimited。
前一种是限制core dump的文件大小不超过1024K,后一种是不限制core dump文件的大小。建议根据实际情况进行设置大小,因为coredump是将程序崩溃的那一刻的内存进行快照,因此越占用内存的进程,其生成的core文件,也就会越大。因此动辄几个G的core文件,也就不再稀奇。很有可能把磁盘占满了,导致程序异常。
2. 永久有效:打开/etc/profile文件, 增加如下以下并生使其生效:ulimit -S –c unlimited > /dev/null 2>&1。
设备里面可能同时运行多个应用,不同的应用可能都会发生crash,若core文件名不做特殊识别,可能无法在多个core文件中,找到我们需要的那一个。因此对core文件进行文件名设置,就显得很有必要。
echo ‘/corefiles/core-%e-%p-%t’ > /proc/sys/kernel/core_pattern,其中:
- core-%e-%p-%t是core 文件名,以core-开头。
- %g 所dump进程的实际组ID
- %t core dump的时间 (由1970年1月1日计起的秒数)
- %e 程序文件名
一般默认就设置为core-%e-%p-%t。
我们知道嵌入式平台的磁盘空间一般也是有限的,但是它会通过挂载不同的磁盘分区,实现扩容。比如:

如上图,我的环境中,默认core文件保存的路径是/usr/share/apport/apport/,若/usr所挂载的分区磁盘空间不足怎么办,那么此时就可以通过修改core文件保存路径实现。
同理,同样通过修改/proc/sys/kernel/core_pattern。
代码设置
有时候,我们也可以通过程序开启coredump,这样测试人员就不用在意系统环境的设置了。但是前提是程序必须以root权限运行。代码示例如下:
|
#include <stdio.h> #define CORE_FILE_SIZE 1024*1024*5 /** core文件大小,可根据实际情况设置*/ int32_t core_pattern_fd = open(KERNEL_PATTERN_FILE, O_RDWR|O_NDELAY|O_TRUNC, 0666); ret = write(core_pattern_fd, path, strlen(path)); int32_t main(int32_t argc, char* argv[]) |
调试
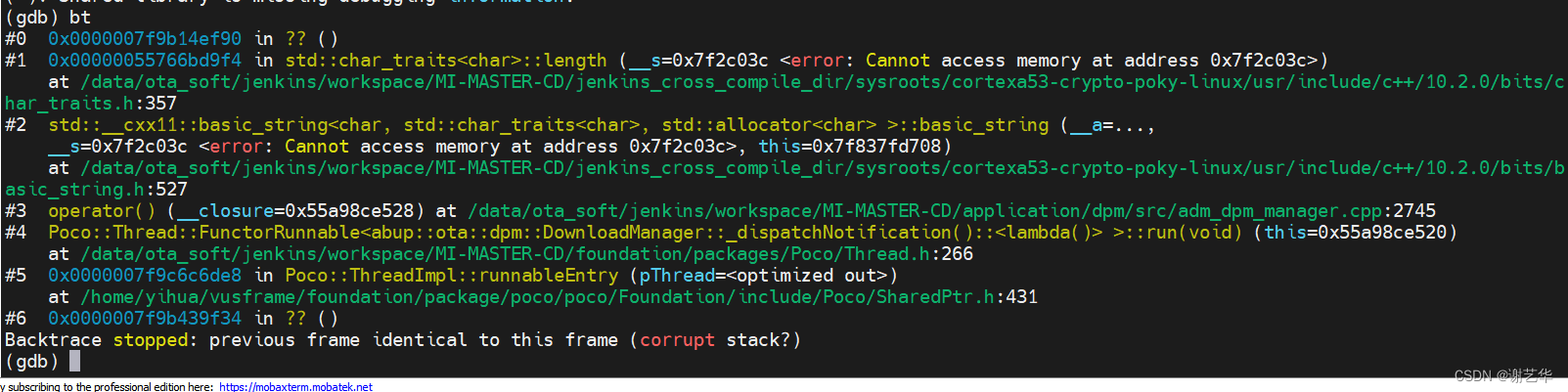
程序异常之后,我们就可以在设置的路径下生成对应的coredump文件,通过对应编译链中的gdb工具可分析coredump文件。为什么要用工具链中的gdb工具呢?这个可以思考一下,可以在评论区回答哦~~~。
调试程序步骤:
1. 启动gdb,进入core文件。命令格式:gdb [exec file] [core file]。如下:
|
yihua@ubuntu:~/coredump/core$ /opt/corbos–linux/2.30.0/sysroots/x86_64-pokysdk–linux/usr/bin/aarch64-poky-linux/aarch64-poky-linux-gdb otamaster otaMasterCore_1699106821.8 For help, type “help”. warning: Could not load shared library symbols for 43 libraries, e.g. /usr/library/libvdi_main.so. |
2. 设置库的加载路径。可执行程序运行时会加载很多动态库,core文件中的一些代码段很有可能就是在这些库中,若不加载这些依赖库,就无法观察相应的符号及堆栈信息。
3. 将设备中程序依赖的库拷贝出来。ldd或objdump –x programe | grep NEEDED查看依赖库。
4. 在GDB中设置动态库寻找路径。set solib-search–path。如:
|
(gdb) info sharedlibrary |
刚开始,exec file 依赖这些动态库,但是都没有加载到。执行set solib-search-path后。
|
(gdb) set solib-search-path . |
如上,设置动态库寻找路径后,就可以正常加载动态库了。
gdb 常用调试命令
通过上面流程,我们已经能够正式进入gdb调试阶段了。在这里我分享一下,我常用的一些命令。
backtrace 可简写成 bt,用于查看当前所在线程的调用堆栈。如果我们想切换到其他堆栈处,则可以使用frame命令。frame命令可被简写成f,f 堆栈编号。

x (hexadecimal)按十六进制格式显示变量。
d (signed decimal)按十进制格式显示变量。
u (unsigned decimal)按十进制格式显示无符号整型。
o (octal)按八进制格式显示变量。
t (binary)按二进制格式显示变量。
a (address)按十六进制格式显示地址,并显示距离前继符号的偏移量(offset)。常用于定位未知地址(变量)。
c (character)按字符格式显示变量。
f (floating)按浮点数格式显示变量。
- u 表示(the unit size)从当前地址往后请求的位宽大小。如果不指定的话,GDB默认是4个bytes。u参数可以用下面的字符来代替,b表示单字节,h表示双字节,w表示四字 节,g表示八字节。
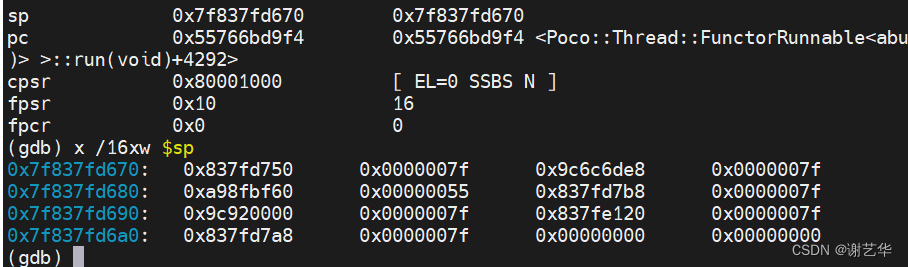
例如,打印当前栈顶地址开始,4字节为单位,以16进制输出,共输出16个。即输出栈顶64字节内容。
案例实践
关于gdb的实际案例分析,可参考我的gdb调试专栏。后续也会持续更新案例。
技巧
场景:有些情况下,我们需要查看一个程序的日志输出,但苦于这个程序并不是我们开发的。默认情况下,该程序的输出默认是到/dev/null中的。如何查看它的输出呢?
- 获取正在运行的进程pid。ps -ef | grep MCM_atcop_svr
- 运行gdb命令。gdb -p pid
- 通过close系统调用关闭标准输出(STDOUT)或者标准错音误(STDERR): call close(1)
- 通过create系统调用打开一个文件并将其文件描述符通过dup2系统调用复制给标准输出或者标准错误:call dup2(creat(“/tmp/log“,0600),1)
- 退出调试器:quit
总结
上述便是本文的分享,如果能给各位看客带来一点帮助,还请三连支持一下。您的支持就是我的动力。
原文地址:https://blog.csdn.net/xieyihua1994/article/details/134669921
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_15437.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!

![[职场] C++开发工程师的岗位职责 #学习方法#笔记](https://img-blog.csdnimg.cn/img_convert/dc32c7a3f3c1b6f79ad738d39712c70f.png)