概览
简单来说,集成学习是一种分类器结合的方法(不是一种分类器)。
-
思路:每个学习器按照串行的方法生成。把几个基本学习器层层叠加,但是每一层的学习器的重要程度不同,越前面的学习的重要程度越高。它聚焦样本的权重。每一层在学习的时候,对前面几层分错的样本“特别关注”,建立了每个机器学习器之间的依赖关系,因此提升了整体模型的准确率。
boost家族还是非常有名的,在sklearn上已经集成了非常多的boost分类器,例子特别多。值得一提的是很多树类的boost还可以作为特征筛选器,有特征重要程度评分的功能。
-
跟楼上不一样,这个方法是并行的,每个学习器是独立的存在,所以在训练的时候也将训练集分成互相有交集(训练集庞大的时候也可以没交集)的几组分别给每个学习器学习。因此bagging方法是一个集体决策,这就导致了每个学习器的学习结果存在差异。对于相同部分,直接采取;对于不同部分,采用投票的方式做出集体决策。
-
这个思路跟上面两种方法又有所区别。之前的方法是对几个基本学习器的结果操作的,而Stacking是针对整个模型操作的,可以将多个已经存在的模型进行组合。跟上面两种方法不一样的是,Stacking强调模型融合,所以里面的模型不一样(异质),而上面两种方法中的模型基本类似(同质)。个人感觉关键点在于组合的模型的选择和组合策略的确定。
南京大学的周志华教授对集成学习有很深入的研究,其在09年发表的一篇概述性论文《Ensemble Learning》对这三种集成学习的框架的介绍非常详细。
模型的特点:
优点:
boosting
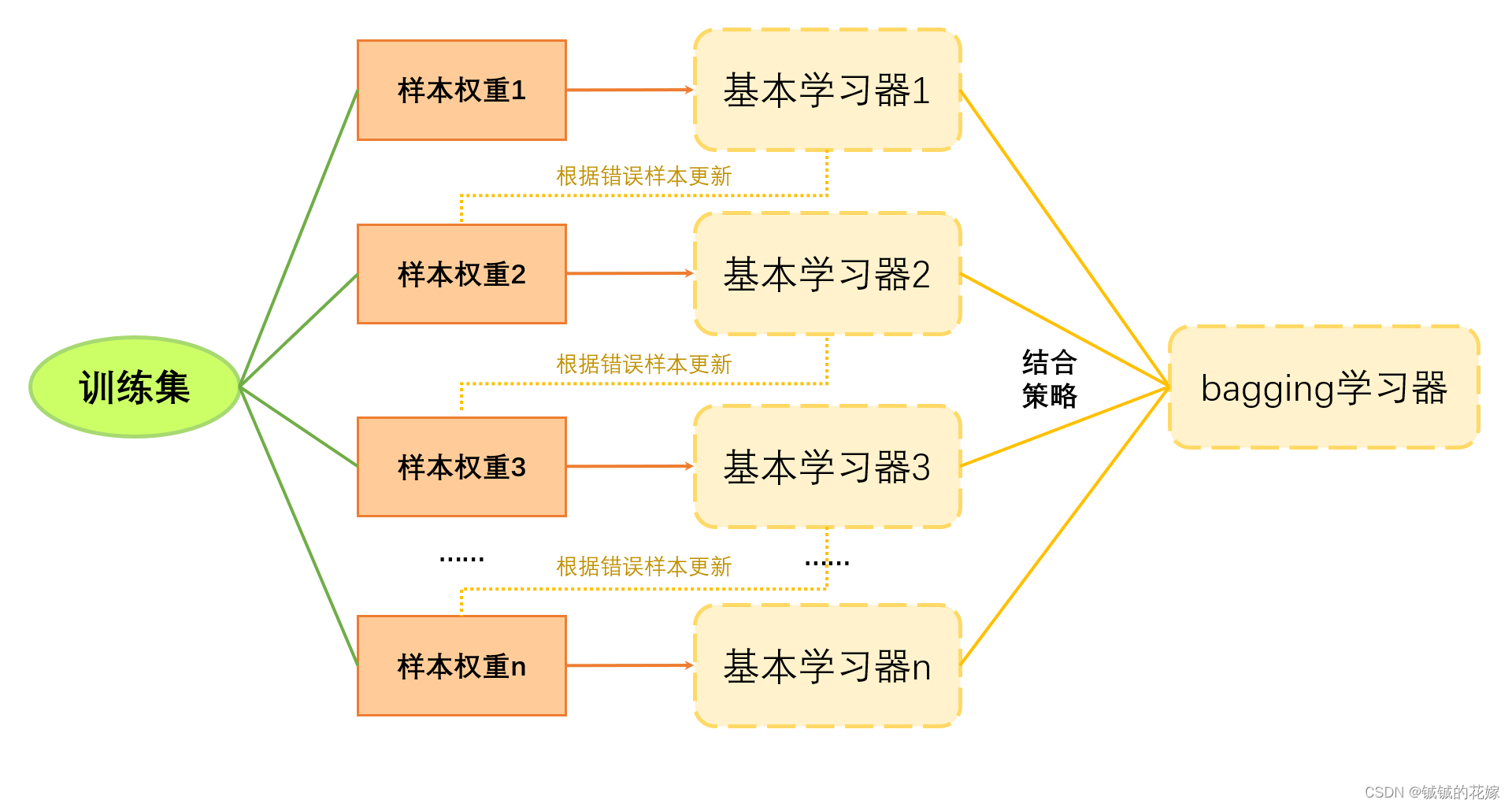
注意点:
- 权重初始化:样本权重1初始化的时候直接平分权重。如果有n个样本,那就直接每个样本
1
n
frac{1}{n}
n1的权重。
- 权重更新方法:不同的模型就不一样 AdaBoost 是对错误样本赋更大的权重;GBDT(Gradient Boost Decision Tree) 每一次的计算是为了减少上一次的残差,还有很多其他的模型用了不同的方法。
- 迭代:一直计算每个基本分类器的误差率,并更新,直至误差率达到规定范围。
- 相对来说,boosting模型更关注在上一轮的结果上进行调整,是个串行的策略。所以,作为一个序列化的方法,其基本学习器之间存在强依赖关系,基本学习器可以稍微简单一点(弱分类器)。
bagging
基本过程如下图所示,还是能看出跟 boosting 不一样的。
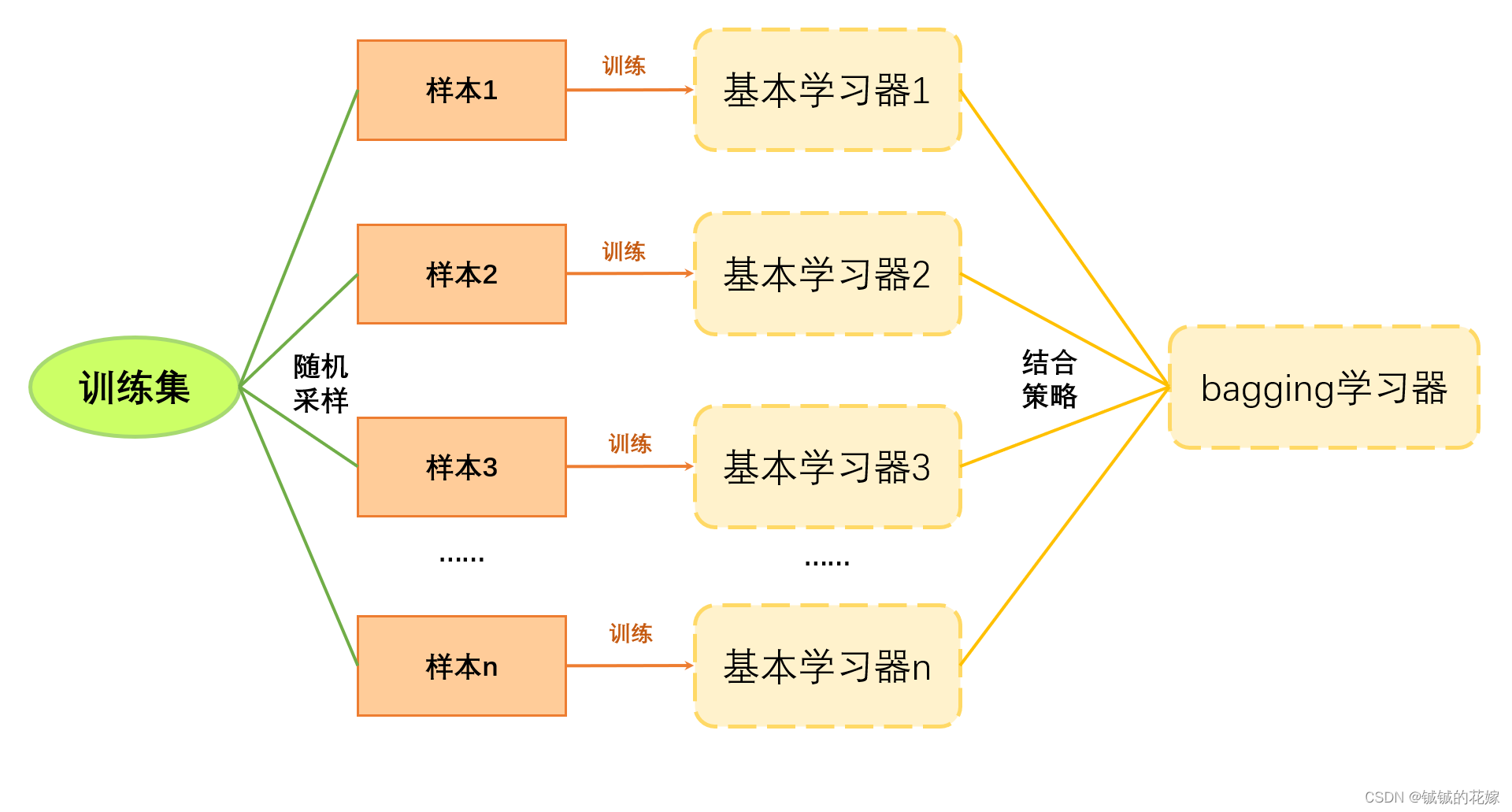
注意点:
- 随机采样:又放回地随机采样,所以有的样本被重复抽到有的不会被抽到。好处是能降低数据分布对学习器的影响。
- 结合策略:随机森林就是在样本随机采样时对决策树也随机采样。
- 迭代:一直训练基本学习器,直至基本学习器的数量达到规定数量。
- 相对来说,bagging模型更关注每个模型的表现,因为是个并行的策略,每个模型都很重要。所以,基本学习器可以稍微复杂一点(随机森林的决策树深度深一点)。
Stacking
这个其实跟楼上不太一样,这个不是一个集成学习模型,是一个结合策略。
- 投票法
- 平均法
- stack
投票
最简单的投票就是直接让基本学习器对某一个样本分类,每个分类器根据自己的结果对类别投票。对于最终的分类结果,我们取得票最多的选项,如果出现平票就随机选一个。
稍微有点想法的投票是绝对多数投票:有点像决策树的增益率选取,对于最终的分类结果,它不仅要满足取得票最多这一条件,还要满足被投票过半的条件。如果不满足,那就直接拒绝预测。
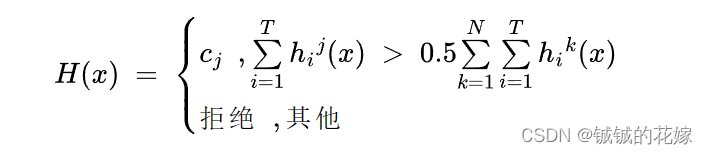
另一种投票方法是加权投票法:对于每个学习器赋予权重,再加权求和得到每个类别的票数,这里的权重制定方法就要看你自己了。
平均
很多时候,针对回归问题,投票显然不能解决问题。这个时候就需要平均。
普通的平均就是直接取多个学习器的预测结果直接取平均。
加权平均跟其他的也差不多,主要是怎么个赋权法。
Stack
从初始数据集中训练出初级学习器,然后“生成”一个新数据集用于训练次级学习器。在新数据集中,初级学习器的输出被当做样例输入特征,初始样本的标记仍被当做样例标记。
上面的两种学习器我们称为:
- 基学习器:即上述所说的一级学习器
- 元学习器:即上述所说的二级学习器。这里的”元“跟元学习、元宇宙等的”元“是一个意思,表示的是更高一层的抽象。元学习器即“学习器的学习器”,有点像基学习器的加权平均和打分器。
还有几个注意点:
-
强模型
一般来说跟bagging一样,第一层放的都是强模型,毕竟这几个模型是并行的,只有这几个强了最后的结果才会好,不然一堆垃圾放到一起再怎么组合都没用。
-
多样性
此外第一层的基学习器最好还得多样一点(结构),因为stacking希望从多个模型中学到不同的特点取其精华,不同的模型针对不同的分布效果也有好有坏。典型的错误就是第一层放好几个随机森林模型。
-
多基学习器
理由很简单,元学习器是学习基学习器的结果的,如果你基学习器太少就导致元学习器的输入特征过少,就导致元学习器不能很好地学习基学习器之间的关系,就导致元学习器效果下降。
-
这里的大数据不是指那种要用Hadoop的那种大数据,这里是指数据不能太少。毕竟要划分测试集训练集,还要交叉验证划分k折和验证集,要是数据太少确实没什么用。
-
简单元学习器
这个学习器不要太强,因为很强大的学习器在这种简单问题上往往会过拟合,毕竟第一层的基学习器已经很强了,元学习器只是为了学习基学习器的结果而已。
我的理解是这样的:
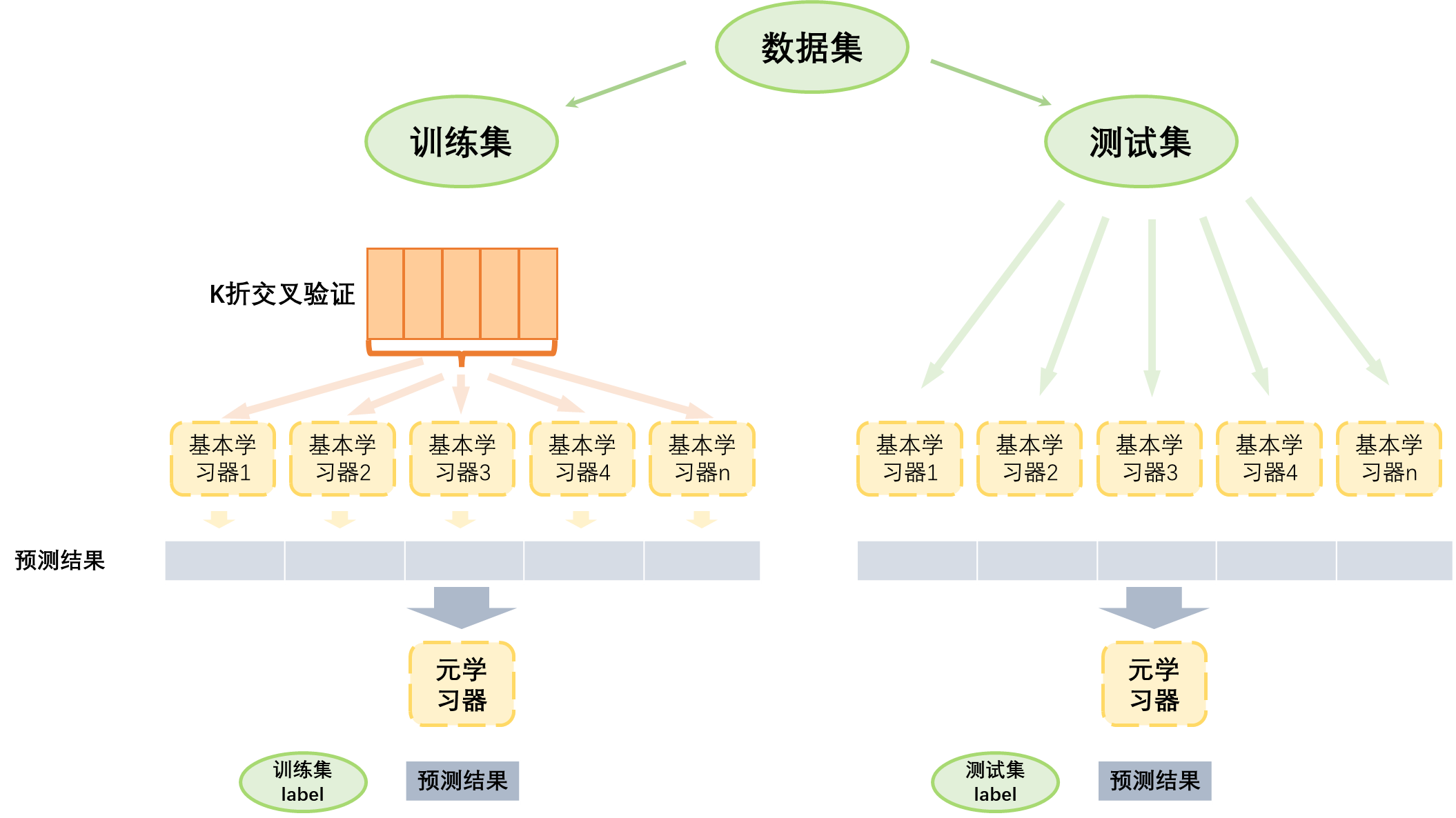
在训练的时候
在预测的时候
- 将测试样本呢输入至以训练好的基学习器中,得到每个基学习器的预测结果,并保存
- 将基学习器的预测结果拼接到一起(也有说法是去平均),输入至元学习器中。元学习器以拼接的结果为训练样本,测试集label为标记得出预测结果
- 对比元学习器的预测结果于基学习器的预测结果,测试stacking之后模型的表现是否优于单一模型的表现
对于stacking的架构,这篇写的也非常好:Stacking:集成学习策略图解_stacking策略_SaoYear的博客-CSDN博客
代码实现
1. 分类
1.0 数据集介绍
好像是好久好久好久之前的小说新闻分类任务了,直接拿特征工程归一化之后的结果来用,感觉大小对机器学习来说不大不小吧(可能还是有点偏小,但是太大了这么多模型跑的好慢……)
训练集(1421 x 43)
label(1421 x 1)分布为44.5%的1,55.5%的0。
1.1 boosting

关于boosting,查了一下sklearn里的模型,好像没有啥框架,都是人家实现好的东西,暂时就直接用吧。应该就 AdaBoost, GTBoost,HBGBoost 这三个。
再补几个比较有名的boost(xgboost:https://xgboost.apachecn.org;CatBoost:CatBoost – open-source gradient boosting library;LightGBM:Welcome to LightGBM’s documentation! — LightGBM 3.3.5.99 documentation),这里我只管实现哈,之后可能会出原理的博客,一键三连不迷路~~
(写的时候没注意 ModelResult 和 Result 用的不是很合理)
import pandas as pd
import numpy as np
np.set_printoptions(precision=3)
from datetime import time, timedelta
import time
from sklearn.model_selection import train_test_split, cross_val_predict, cross_val_score, KFold, RandomizedSearchCV
from sklearn.metrics import accuracy_score, f1_score
from sklearn.ensemble import GradientBoostingClassifier, AdaBoostClassifier, HistGradientBoostingClassifier
from xgboost.sklearn import XGBClassifier
from catboost import CatBoostClassifier
from lightgbm import LGBMClassifier
import warnings
warnings.filterwarnings("ignore")
class ModelResult:
def __init__(self, model_name, train_time, train_acc, train_score, train_F1, test_time, test_acc, test_score,
test_F1):
self.model_name = model_name
self.train_time = train_time
self.train_acc = train_acc
self.train_score = train_score
self.train_F1 = train_F1
self.test_time = test_time
self.test_acc = test_acc
self.test_score = test_score
self.test_F1 = test_F1
self.columns = ["model_name", "train_time", "train_acc", "train_score", "train_F1", "test_time", "test_acc",
"test_score", "test_F1"]
def to_list(self):
return [self.model_name, self.train_time, self.train_acc, self.train_score, self.train_F1, self.test_time,
self.test_acc, self.test_score, self.test_F1]
class Result:
def __init__(self):
self.model_list = []
def save(self, file_name):
model_list = [line.to_list() for line in self.model_list]
output = pd.DataFrame(model_list, columns=self.model_list[0].columns)
output.to_csv(file_name, encoding="utf-8-sig", index=0)
class BoostMethod:
def __init__(self, datapath, labelpath, k=5, cv=4, search=False):
"""
:param datapath: 数据路径
:param labelpath: 标签路径
:param k: k折训练
:param cv: 交叉验证次数
:param search: 是否需要网格调参
"""
self.data_path = datapath
self.labelpath = labelpath
self.dataset = self.loading_data() # [train_x, test_x, train_y, test_y]
self.cv = cv
self.k = k
self.search = search
self.model = {
"AdaBoost": AdaBoostClassifier(n_estimators=100),
"GTBoost": GradientBoostingClassifier(n_estimators=100, learning_rate=1.0, max_depth=1, random_state=0),
"HBGBoost": HistGradientBoostingClassifier(max_iter=100),
"xgboost": XGBClassifier(eval_metric=['logloss', 'auc', 'error']),
"CatBoost": CatBoostClassifier(learning_rate=0.1, depth=6, iterations=100, verbose=False),
"LightGBM": LGBMClassifier(learning_rate=0.1, max_depth=3, num_leaves=16),
}
def loading_data(self):
data = pd.read_csv(self.data_path, encoding="utf-8-sig", header=0)
label = pd.read_csv(self.labelpath, encoding="utf-8-sig", header=0)
train_x, test_x, train_y, test_y = train_test_split(data, label, test_size=0.3, random_state=1129)
return {"train_x": train_x, "test_x": test_x, "train_y": train_y, "test_y": test_y}
def fitting(self):
result = Result()
for item in self.model.items():
model_name = item[0]
model = item[1]
print(model_name)
model, train_time, (train_acc, train_score, train_F1) = self.train(model, self.dataset["train_x"],
self.dataset["train_y"])
(test_time, test_acc, test_score, test_F1) = self.test(model, self.dataset["test_x"],
self.dataset["test_y"])
model_result = ModelResult(model_name, train_time, train_acc, train_score, train_F1, test_time, test_acc,
test_score, test_F1)
result.model_list.append(model_result)
return result
def evaluate(self, model, data, label, test=False):
start_time = time.time()
predict = cross_val_predict(model, data, label, cv=self.cv)
time_ret = self.get_time_dif(start_time)
acc = accuracy_score(predict, label)
score = cross_val_score(model, data, label, cv=self.cv).mean()
F1 = f1_score(label, predict)
if test:
return str(time_ret), acc, score, F1
else:
return acc, score, F1
def train(self, model, data, label):
start_time = time.time()
kf = KFold(n_splits=self.k, random_state=1129, shuffle=True)
for train, evaluate in kf.split(data):
model.fit(data.iloc[train], label.iloc[train])
time_ret = self.get_time_dif(start_time)
return model, str(time_ret), self.evaluate(model, data, label)
def test(self, model, data, label):
return self.evaluate(model, data, label, test=True)
def get_time_dif(self, start_time):
end_time = time.time()
time_dif = end_time - start_time
# print("Time usage:", timedelta(seconds=int(round(time_dif))))
return timedelta(seconds=int(round(time_dif)))
if __name__ == '__main__':
method = BoostMethod("dataset.csv", "label.csv")
result = method.fitting()
result.save("boosting{}.csv".format(time.strftime('_%Y%m%d_%H%M', time.localtime())))
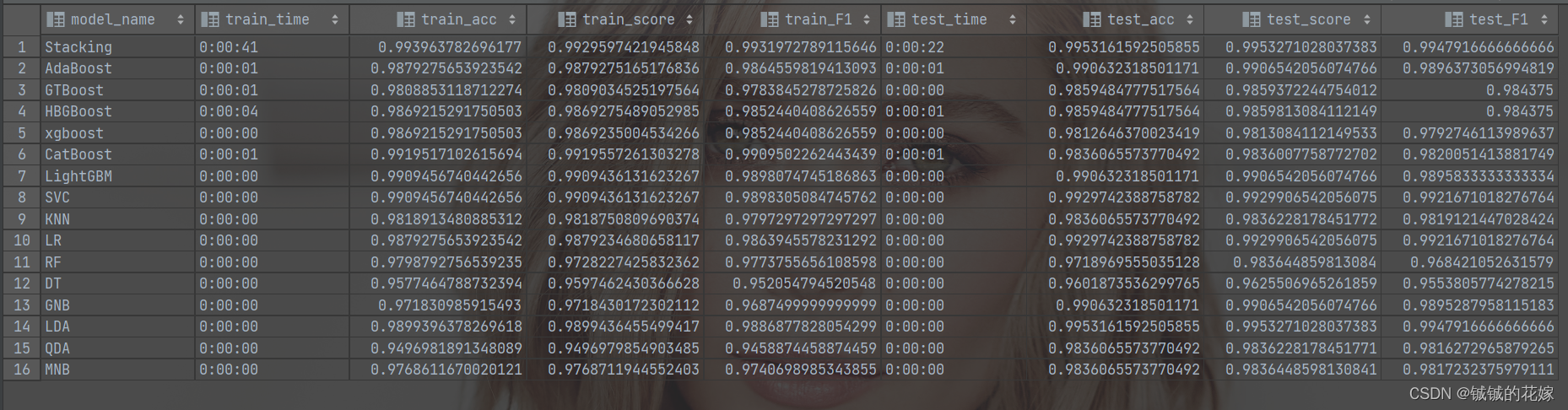
几个模型结果如下

1.2 bagging
直接用sklearn试一下:
import pandas as pd
import numpy as np
from sklearn.ensemble import BaggingClassifier
from sklearn.svm import SVC
np.set_printoptions(precision=3)
from datetime import time, timedelta
import time
from sklearn.model_selection import train_test_split, cross_val_predict, cross_val_score, KFold, RandomizedSearchCV,
GridSearchCV
from sklearn.metrics import accuracy_score, f1_score
import warnings
warnings.filterwarnings("ignore")
class ModelResult:
def __init__(self, model_name, train_time, train_acc, train_score, train_F1, test_time, test_acc, test_score,
test_F1):
self.model_name = model_name
self.train_time = train_time
self.train_acc = train_acc
self.train_score = train_score
self.train_F1 = train_F1
self.test_time = test_time
self.test_acc = test_acc
self.test_score = test_score
self.test_F1 = test_F1
self.columns = ["model_name", "train_time", "train_acc", "train_score", "train_F1", "test_time", "test_acc",
"test_score", "test_F1"]
def to_list(self):
return [self.model_name, self.train_time, self.train_acc, self.train_score, self.train_F1, self.test_time,
self.test_acc, self.test_score, self.test_F1]
class Result:
def __init__(self):
self.model_list = []
def save(self, file_name):
model_list = [line.to_list() for line in self.model_list]
output = pd.DataFrame(model_list, columns=self.model_list[0].columns)
output.to_csv(file_name, encoding="utf-8-sig", index=0)
class BaggingMethod:
def __init__(self, datapath, labelpath, k=5, cv=4, search=False):
"""
:param datapath: 数据路径
:param labelpath: 标签路径
:param k: k折训练
:param cv: 交叉验证次数
:param search: 是否需要网格调参
"""
self.data_path = datapath
self.labelpath = labelpath
self.dataset = self.loading_data() # [train_x, test_x, train_y, test_y]
self.cv = cv
self.k = k
self.search = search
self.model = {
"SVM": SVC(kernel='rbf', class_weight='balanced')
}
def loading_data(self):
data = pd.read_csv(self.data_path, encoding="utf-8-sig", header=0)
label = pd.read_csv(self.labelpath, encoding="utf-8-sig", header=0)
train_x, test_x, train_y, test_y = train_test_split(data, label, test_size=0.3, random_state=1129)
return {"train_x": train_x, "test_x": test_x, "train_y": train_y, "test_y": test_y}
def fitting(self):
result = Result()
for item in self.model.items():
model_name = item[0]
model = item[1]
print(model_name)
model, train_time, (train_acc, train_score, train_F1) = self.train(model, self.dataset["train_x"],
self.dataset["train_y"])
(test_time, test_acc, test_score, test_F1) = self.test(model, self.dataset["test_x"],
self.dataset["test_y"])
model_result = ModelResult(model_name, train_time, train_acc, train_score, train_F1, test_time, test_acc,
test_score, test_F1)
result.model_list.append(model_result)
return result
def evaluate(self, model, data, label, test=False):
start_time = time.time()
predict = cross_val_predict(model, data, label, cv=self.cv)
time_ret = self.get_time_dif(start_time)
acc = accuracy_score(predict, label)
score = cross_val_score(model, data, label, cv=self.cv).mean()
F1 = f1_score(label, predict)
if test:
return str(time_ret), acc, score, F1
else:
return acc, score, F1
def train(self, model, data, label):
start_time = time.time()
clf = BaggingClassifier(estimator=model, n_estimators=20, max_samples=1.0, max_features=1.0,
bootstrap=True, bootstrap_features=False, n_jobs=1, random_state=1)
param_grid = [{'estimator': [SVC(kernel='rbf', class_weight='balanced', C=4.5)],
'n_estimators': [20], 'max_samples': [0.95],
'max_features': [0.8]}]
grid = GridSearchCV(clf, param_grid, cv=6, n_jobs=-1)
grid.fit(data, label.values.ravel())
best_estimator = grid.best_estimator_
time_ret = self.get_time_dif(start_time)
return best_estimator, str(time_ret), self.evaluate(best_estimator, data, label)
def test(self, model, data, label):
return self.evaluate(model, data, label, test=True)
def get_time_dif(self, start_time):
end_time = time.time()
time_dif = end_time - start_time
# print("Time usage:", timedelta(seconds=int(round(time_dif))))
return timedelta(seconds=int(round(time_dif)))
if __name__ == '__main__':
method = BaggingMethod("dataset.csv", "label.csv")
result = method.fitting()
result.save("bagging{}.csv".format(time.strftime('_%Y%m%d_%H%M', time.localtime())))
结果长这样

1.3 stacking
stacking 如果手写实现,那还是有难度的。幸运的是 sklearn给我们提供了相关的函数,所以秒出。
还是要说明下,stacking 的元学习器真的不建议放太好的。也尝试过随机森林等等,效果真没有线性的逻辑回归好。就是说强学习器模型可能会造成过拟合,反而降低了我们这块的准确率。
import pandas as pd
import numpy as np
np.set_printoptions(precision=3)
from datetime import time, timedelta
import time
from sklearn.model_selection import train_test_split, cross_val_predict, cross_val_score, KFold, RandomizedSearchCV
from sklearn.metrics import accuracy_score, f1_score
from sklearn.ensemble import GradientBoostingClassifier, AdaBoostClassifier, HistGradientBoostingClassifier, RandomForestClassifier, StackingClassifier
from xgboost.sklearn import XGBClassifier
from catboost import CatBoostClassifier
from lightgbm import LGBMClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn import tree
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis
from sklearn.svm import SVC
from sklearn.naive_bayes import MultinomialNB
import warnings
warnings.filterwarnings("ignore")
class ModelResult:
def __init__(self, model_name, train_time, train_acc, train_score, train_F1, test_time, test_acc, test_score,
test_F1):
self.model_name = model_name
self.train_time = train_time
self.train_acc = train_acc
self.train_score = train_score
self.train_F1 = train_F1
self.test_time = test_time
self.test_acc = test_acc
self.test_score = test_score
self.test_F1 = test_F1
self.columns = ["model_name", "train_time", "train_acc", "train_score", "train_F1", "test_time", "test_acc",
"test_score", "test_F1"]
def to_list(self):
return [self.model_name, self.train_time, self.train_acc, self.train_score, self.train_F1, self.test_time,
self.test_acc, self.test_score, self.test_F1]
class Result:
def __init__(self):
self.model_list = []
def save(self, file_name):
model_list = [line.to_list() for line in self.model_list]
output = pd.DataFrame(model_list, columns=self.model_list[0].columns)
output.to_csv(file_name, encoding="utf-8-sig", index=0)
class StackMethod:
def __init__(self, datapath, labelpath, k=5, cv=4, search=False):
"""
:param datapath: 数据路径
:param labelpath: 标签路径
:param k: k折训练
:param cv: 交叉验证次数
:param search: 是否需要网格调参
"""
self.data_path = datapath
self.labelpath = labelpath
self.dataset = self.loading_data() # [train_x, test_x, train_y, test_y]
self.cv = cv
self.k = k
self.search = search
self.model = {
"AdaBoost": AdaBoostClassifier(n_estimators=100),
"GTBoost": GradientBoostingClassifier(n_estimators=100, learning_rate=1.0, max_depth=1, random_state=0),
"HBGBoost": HistGradientBoostingClassifier(max_iter=100),
"xgboost": XGBClassifier(eval_metric=['logloss', 'auc', 'error']),
"CatBoost": CatBoostClassifier(learning_rate=0.1, depth=6, iterations=100, verbose=False),
"LightGBM": LGBMClassifier(learning_rate=0.1, max_depth=3, num_leaves=16),
"SVC": SVC(kernel='rbf', class_weight='balanced'),
"KNN": KNeighborsClassifier(),
"LR": LogisticRegression(penalty='l2'),
"RF": RandomForestClassifier(n_estimators=8),
"DT": tree.DecisionTreeClassifier(),
"GNB": GaussianNB(),
"LDA": LinearDiscriminantAnalysis(),
"QDA": QuadraticDiscriminantAnalysis(),
"MNB": MultinomialNB(alpha=0.01),
}
def loading_data(self):
data = pd.read_csv(self.data_path, encoding="utf-8-sig", header=0)
label = pd.read_csv(self.labelpath, encoding="utf-8-sig", header=0)
train_x, test_x, train_y, test_y = train_test_split(data, label, test_size=0.3, random_state=1129)
return {"train_x": train_x, "test_x": test_x, "train_y": train_y, "test_y": test_y}
def fitting(self):
result = Result()
estimators = [(item[0], item[1]) for item in self.model.items()]
clf = StackingClassifier(estimators=estimators, final_estimator=LogisticRegression())
clf, train_time, (train_acc, train_score, train_F1) = self.train(clf, self.dataset["train_x"], self.dataset["train_y"])
(test_time, test_acc, test_score, test_F1) = self.test(clf, self.dataset["test_x"], self.dataset["test_y"])
model_result = ModelResult("Stacking", train_time, train_acc, train_score, train_F1, test_time, test_acc, test_score, test_F1)
result.model_list.append(model_result)
for item in self.model.items():
model_name = item[0]
model = item[1]
print(model_name)
model, train_time, (train_acc, train_score, train_F1) = self.train(model, self.dataset["train_x"], self.dataset["train_y"])
(test_time, test_acc, test_score, test_F1) = self.test(model, self.dataset["test_x"], self.dataset["test_y"])
model_result = ModelResult(model_name, train_time, train_acc, train_score, train_F1, test_time, test_acc, test_score, test_F1)
result.model_list.append(model_result)
return result
def evaluate(self, model, data, label, test=False):
start_time = time.time()
predict = cross_val_predict(model, data, label, cv=self.cv)
time_ret = self.get_time_dif(start_time)
acc = accuracy_score(predict, label)
score = cross_val_score(model, data, label, cv=self.cv).mean()
F1 = f1_score(label, predict)
if test:
return str(time_ret), acc, score, F1
else:
return acc, score, F1
def train(self, model, data, label):
start_time = time.time()
kf = KFold(n_splits=self.k, random_state=1129, shuffle=True)
for train, evaluate in kf.split(data):
model.fit(data.iloc[train], label.iloc[train])
time_ret = self.get_time_dif(start_time)
print("Time Usage:{}".format(time_ret))
return model, str(time_ret), self.evaluate(model, data, label)
def test(self, model, data, label):
return self.evaluate(model, data, label, test=True)
def get_time_dif(self, start_time):
end_time = time.time()
time_dif = end_time - start_time
# print("Time usage:", timedelta(seconds=int(round(time_dif))))
return timedelta(seconds=int(round(time_dif)))
if __name__ == '__main__':
method = StackMethod("dataset.csv", "label.csv")
result = method.fitting()
result.save("stacking{}.csv".format(time.strftime('_%Y%m%d_%H%M', time.localtime())))
看结果,stacking 还是很强的,可能是任务太简单了(有的人考100分是因为满分只有100分)。
2. 回归
2.0 数据集介绍
拿2023年美赛春季赛Y题的数据做一下哈~~
一共16个特征,1898条数据,任务是预测帆船的价格,给的是制造商、船型、船长、地区、国家、年份的数据,我自己又找了引擎马力、吃水量、装油量、设计师、最大价格、平均价格、最小价格、LWL、梁长、航范围、定价法的数据,有些数据是特征工程的结果。
去重啊填空啊归一化啊异常值处理啊之类的咱就不提,直接上手模型就完事了。
label 长这样(标准化了)
stacking
把sklearn上的回归模型往上面乱扔。
顺便利用这几个boost算法评估一下特征的重要性。
import pandas as pd
import numpy as np
from catboost import CatBoostRegressor
from datetime import time, timedelta
import time
from sklearn.linear_model import LinearRegression, Ridge, Lasso
from sklearn.model_selection import train_test_split, cross_val_predict, cross_val_score, KFold, RandomizedSearchCV
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
from sklearn.ensemble import AdaBoostRegressor, StackingRegressor, RandomForestRegressor, GradientBoostingRegressor
import lightgbm as lgb
import warnings
from sklearn.neighbors import KNeighborsRegressor
from sklearn.neural_network import MLPRegressor
from sklearn.svm import SVR
from sklearn.tree import DecisionTreeRegressor, ExtraTreeRegressor
from xgboost import XGBRegressor
warnings.filterwarnings("ignore")
np.set_printoptions(precision=3)
class ModelResult:
def __init__(self, model_name, train_time, train_MSE, train_score, train_MAE, train_R2, test_time, test_MSE, test_score, test_MAE,
test_R2):
self.model_name = model_name
self.train_time = train_time
self.train_MSE = train_MSE
self.train_score = train_score
self.train_MAE = train_MAE
self.train_R2 = train_R2
self.test_time = test_time
self.test_MSE = test_MSE
self.test_score = test_score
self.test_MAE = test_MAE
self.test_R2 = test_R2
self.columns = ["model_name", "train_time", "train_MSE", "train_score", "train_MAE", "train_R2", "test_time",
"test_MSE", "test_score", "test_MAE", "test_R2"]
def to_list(self):
return [
self.model_name,
self.train_time,
self.train_MSE,
self.train_score,
self.train_MAE,
self.train_R2,
self.test_time,
self.test_MSE,
self.test_score,
self.test_MAE,
self.test_R2
]
class Result:
def __init__(self):
self.model_list = []
def save(self, file_name):
model_list = [line.to_list() for line in self.model_list]
output = pd.DataFrame(model_list, columns=self.model_list[0].columns)
output.to_csv(file_name, encoding="utf-8-sig", index=0)
class StackMethod:
def __init__(self, datapath, labelpath, predpath, k=5, cv=4, search=False):
"""
:param datapath: 数据路径
:param labelpath: 标签路径
:param k: k折训练
:param cv: 交叉验证次数
:param search: 是否需要网格调参
"""
self.data_path = datapath
self.labelpath = labelpath
self.predpath = predpath
self.dataset = self.loading_data() # [train_x, test_x, train_y, test_y]
self.cv = cv
self.k = k
self.search = search
self.importance = []
self.model = {
"LinearRegression": LinearRegression(),
"SVR": SVR(),
"KNN": KNeighborsRegressor(),
"Ridge": Ridge(random_state=1129,),
"Lasso": Lasso(random_state=1129,),
"DecisionTree": DecisionTreeRegressor(random_state=1129,),
"ExtraTree": ExtraTreeRegressor(random_state=1129,),
"RandomForest": RandomForestRegressor(random_state=1129,),
"MLP": MLPRegressor(random_state=1129),
"GBoost": GradientBoostingRegressor(random_state=1129,),
"AdaBoost": AdaBoostRegressor(random_state=1129, n_estimators=100), # GA search
"LightGBM": lgb.LGBMRegressor(random_state=1129), # 可以优化
"Catboost": CatBoostRegressor(random_state=1129),
"XGBboost": XGBRegressor(random_state=1129),
}
def loading_data(self):
data = pd.read_csv(self.data_path, encoding="utf-8-sig", header=0)
label = pd.read_csv(self.labelpath, encoding="utf-8-sig", header=0)
train_x, test_x, train_y, test_y = train_test_split(data, label, test_size=0.3, random_state=1129)
return {"train_x": train_x, "test_x": test_x, "train_y": train_y, "test_y": test_y}
def fitting(self):
result = Result()
estimators = [(item[0], item[1]) for item in self.model.items()]
clf = StackingRegressor(estimators=estimators, final_estimator=LinearRegression())
clf, train_time, (train_mse, train_score, train_mae, train_r2) = self.train(clf, self.dataset["train_x"], self.dataset["train_y"])
(test_time, test_mse, test_score, test_mae, test_r2) = self.test(clf, self.dataset["test_x"], self.dataset["test_y"])
self.pred_ret(clf, self.dataset["test_x"], self.dataset["test_y"])
model_result = ModelResult("Stacking", train_time, train_mse, train_score, train_mae, train_r2, test_time, test_mse, test_score, test_mae, test_r2)
result.model_list.append(model_result)
for item in self.model.items():
model_name = item[0]
model = item[1]
print(model_name)
model, train_time, (train_mse, train_score, train_mae, train_r2) = self.train(model, self.dataset["train_x"], self.dataset["train_y"])
(test_time, test_mse, test_score, test_mae, test_r2) = self.test(model, self.dataset["test_x"], self.dataset["test_y"])
model_result = ModelResult(model_name, train_time, train_mse, train_score, train_mae, train_r2, test_time, test_mse, test_score, test_mae, test_r2)
result.model_list.append(model_result)
return result
def evaluate(self, model, data, label, test=False):
start_time = time.time()
predict = cross_val_predict(model, data, label, cv=self.cv)
time_ret = self.get_time_dif(start_time)
MSE = mean_squared_error(label, predict)
score = cross_val_score(model, data, label, cv=self.cv).mean()
MAE = mean_absolute_error(label, predict)
R2 = r2_score(label, predict)
if test:
return str(time_ret), MSE, score, MAE, R2
else:
return MSE, score, MAE, R2
def train(self, model, data, label):
start_time = time.time()
kf = KFold(n_splits=self.k, random_state=1129, shuffle=True)
for train, evaluate in kf.split(data):
model.fit(data.iloc[train], label.iloc[train])
time_ret = self.get_time_dif(start_time)
try:
n = model.feature_importances_
self.importance.append(n)
except:
1
print("Time Usage:{}".format(time_ret))
return model, str(time_ret), self.evaluate(model, data, label)
def test(self, model, data, label):
return self.evaluate(model, data, label, test=True)
def get_time_dif(self, start_time):
end_time = time.time()
time_dif = end_time - start_time
# print("Time usage:", timedelta(seconds=int(round(time_dif))))
return timedelta(seconds=int(round(time_dif)))
def save_importance(self, file_path):
file = pd.DataFrame(self.importance)
file.columns = self.dataset["train_x"].columns
file = file.div(file.sum(axis=1), axis='rows')
file = file.T
file["sum"] = file.sum(axis=1)
file.sort_values(by=file.columns[-1], inplace=True, ascending=True)
file.to_csv(file_path)
def pred_ret(self, model, data, label):
predict = model.predict(data)
result = pd.DataFrame([label[label.columns[-1]].values.tolist(), predict]).T
result.columns = ["label", "predict"]
result.to_csv(self.predpath, index=None)
if __name__ == '__main__':
method = StackMethod("dataset_M.csv", "label_M.csv", "ret_M.csv")
result = method.fitting()
method.save_importance("importance/M.csv")
result.save("CSDN_stacking_M{}.csv".format(time.strftime('_%Y%m%d_%H%M', time.localtime())))
结果如下:
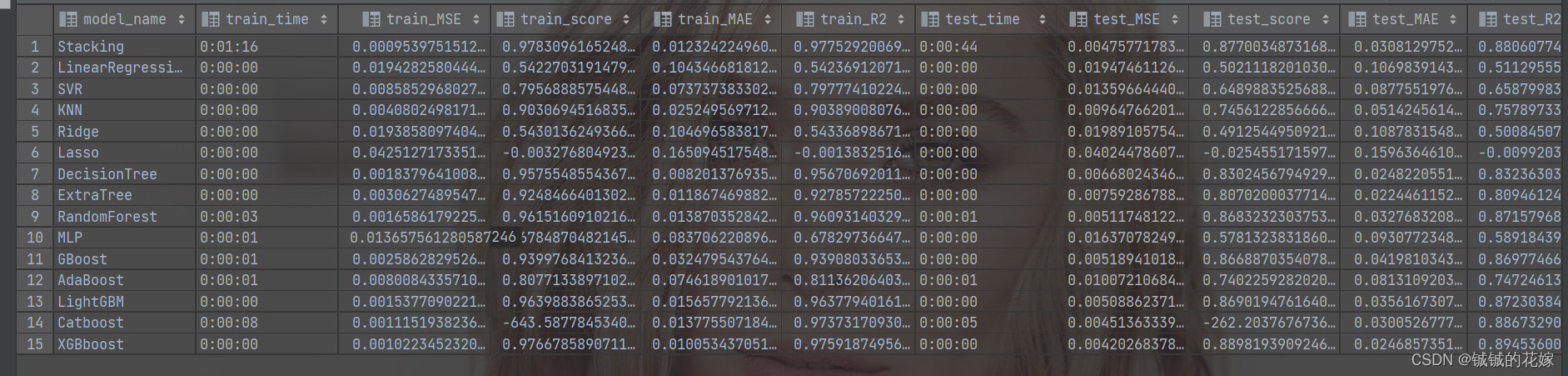
在这个任务上,Stacking倒也没有达到乱杀的程度,有的时候效果还不如单一的集成模型,个人认为是因为中间混入了很多像线性回归啊、岭回归啊、Lasso回归啊、MLP啊之类的弱学习器或者是在该任务上表现不出众的学习器,这些学习器对最后的结果有比较强的干扰作用。改善有3种方案:
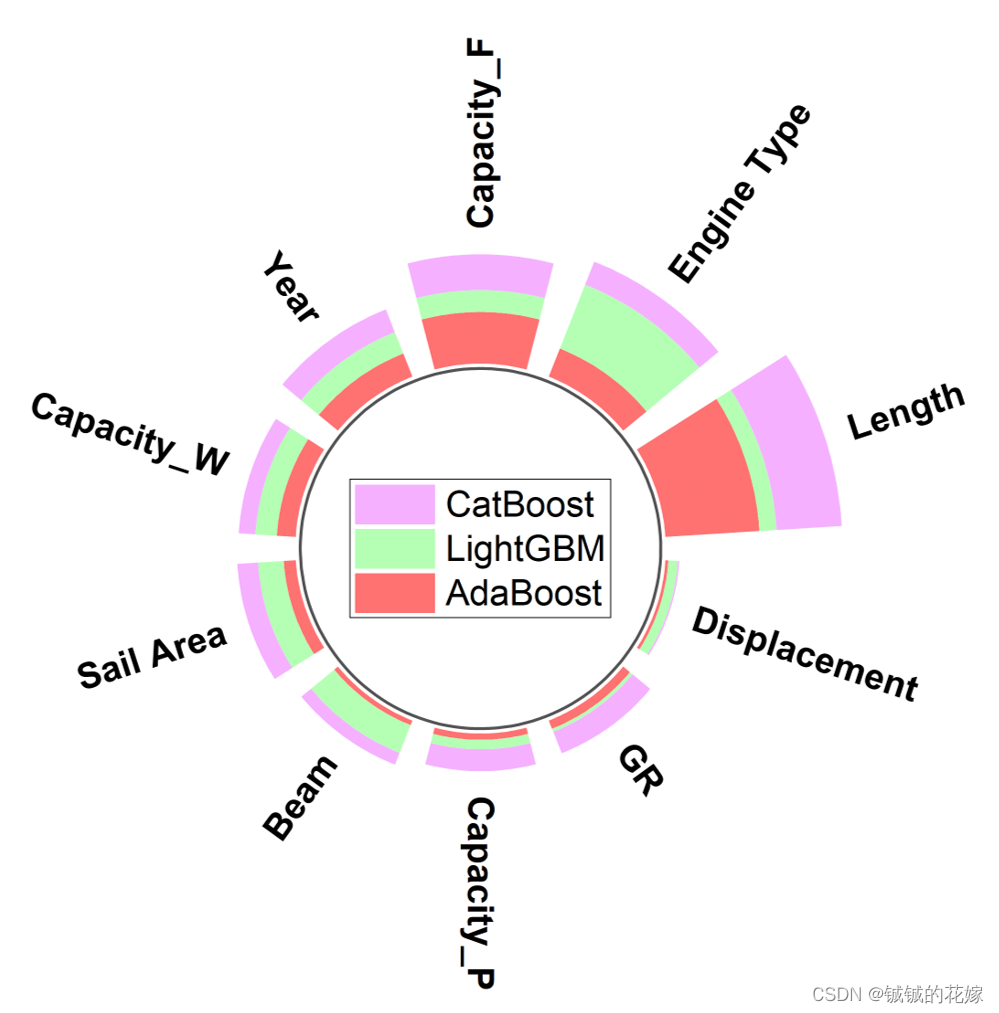
去除掉了几个不相关特征之后,特征重要性在这里:
原文地址:https://blog.csdn.net/Hjh1906008151/article/details/130074958
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_15569.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!






