爬虫时遇到很多数据并不在访问网址的返回包里,而是随着用户下拉逐步加载的,也就是用到了Ajax,那么这时我们该如何爬取我们想要的数据呢?这里用爬取b站评论区相关数据为例,练习一下python爬虫异步爬取数据的相关流程,完整程序实例在最后面:
准备工作
用到的包:
爬虫相关主要还是requests包,练习用脚本本身也并不复杂。
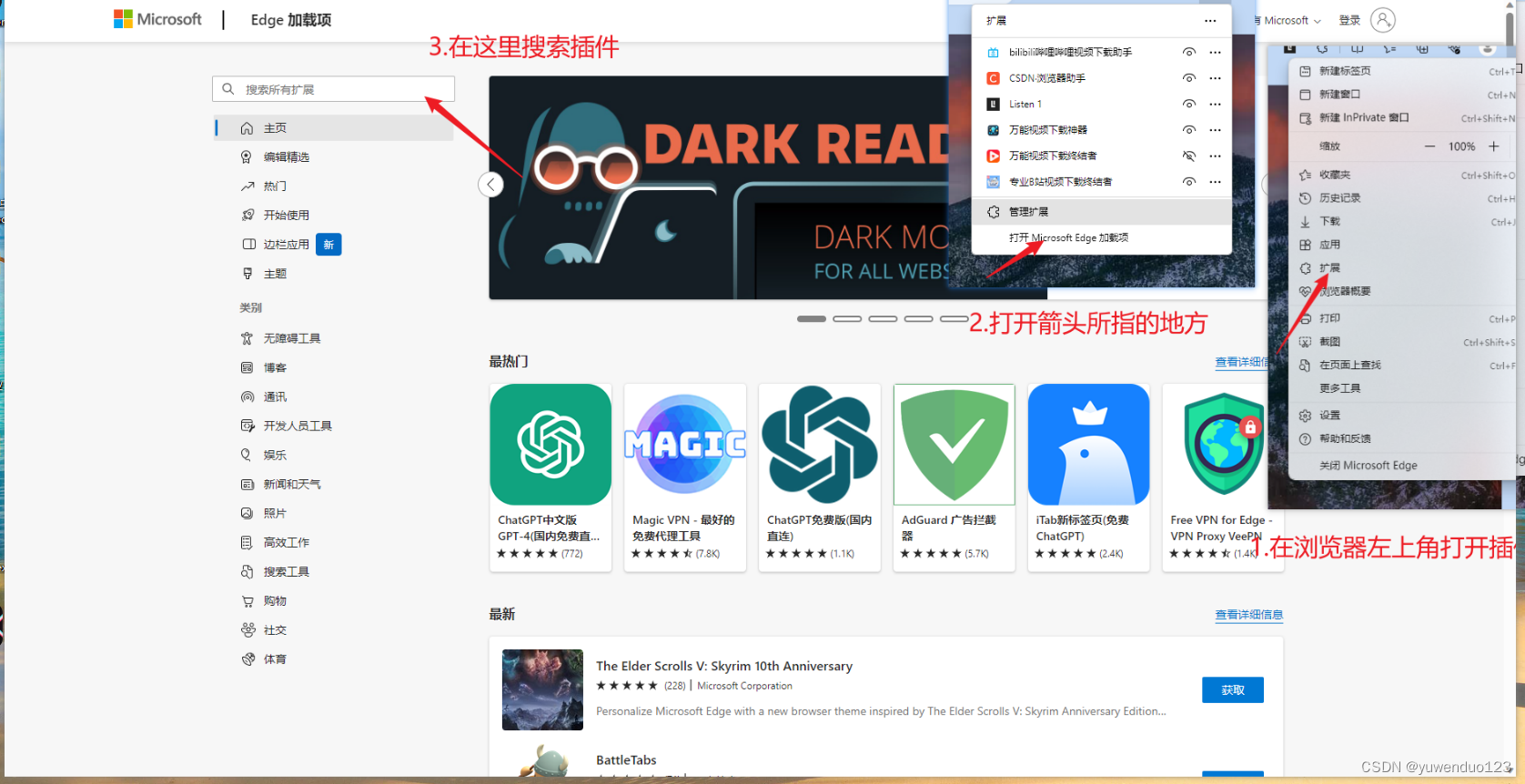
根据写一个爬虫脚本的一般流程,第一步显然是找到含有我们需要信息的相关网页链接,这里我们的目标是b站的评论区。随便点开一个视频。
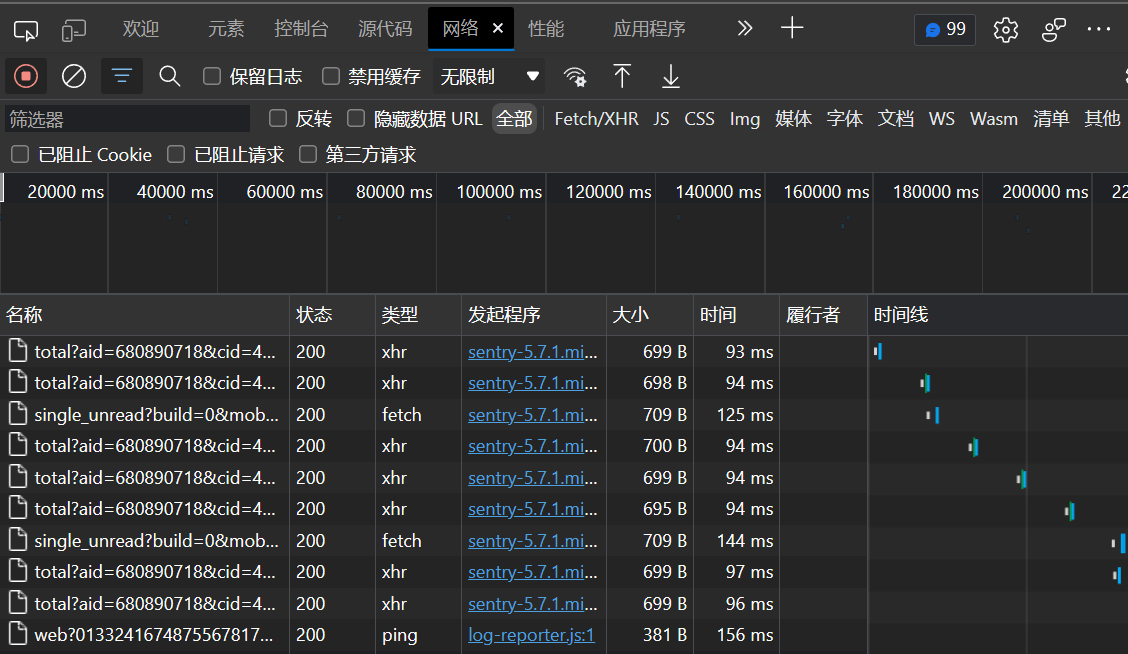
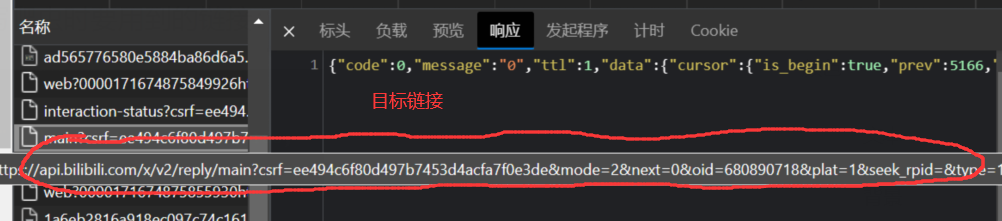


爬虫连接资源
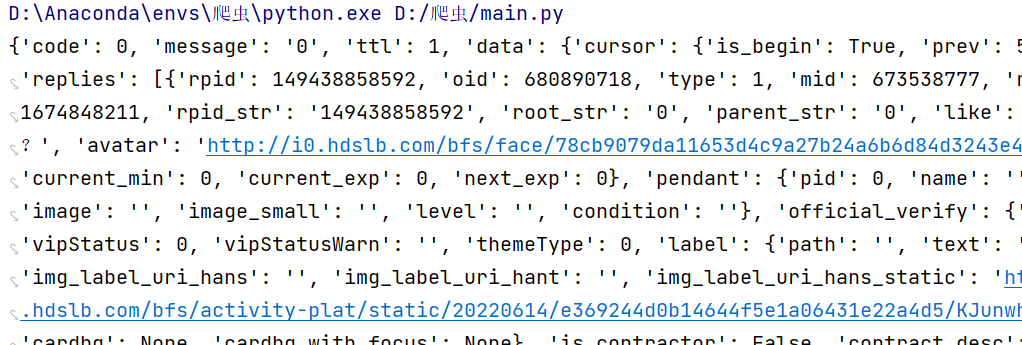
数据处理
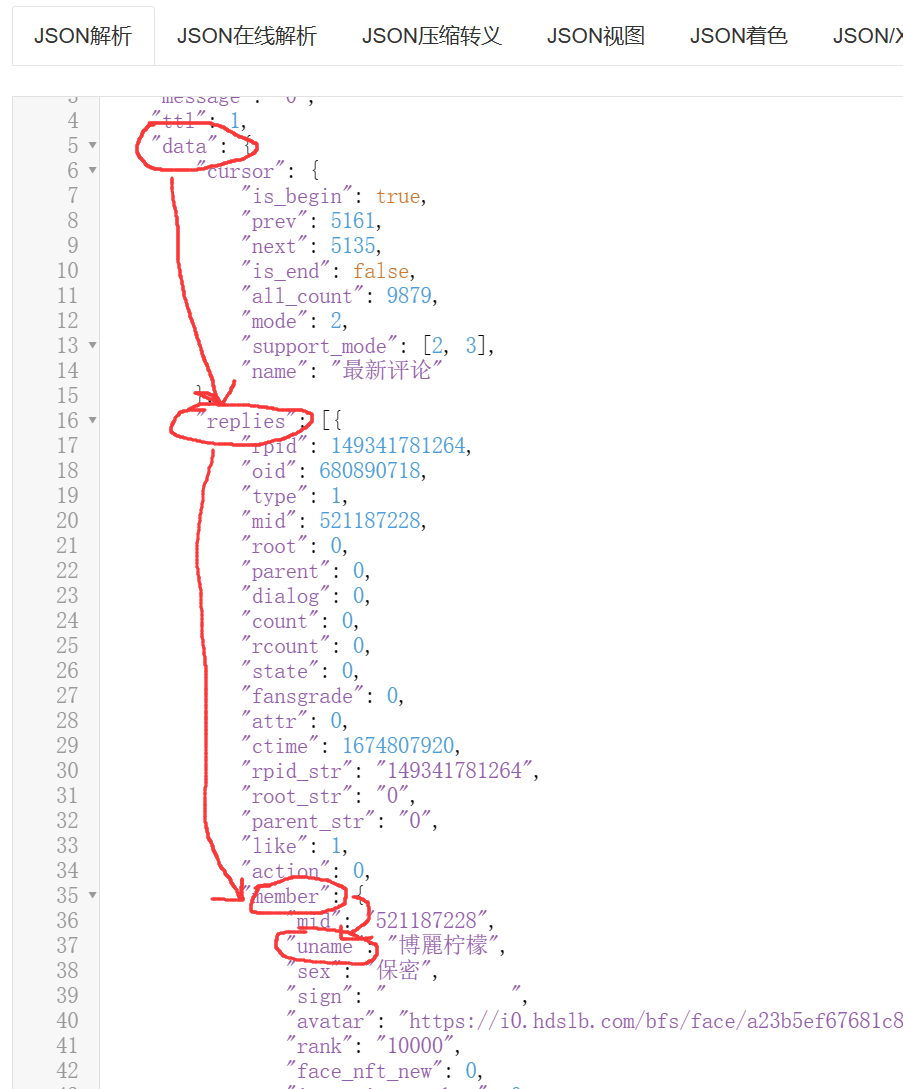


爬取异步数据
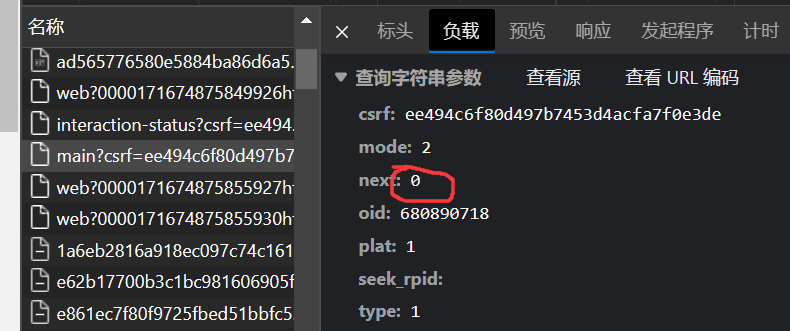
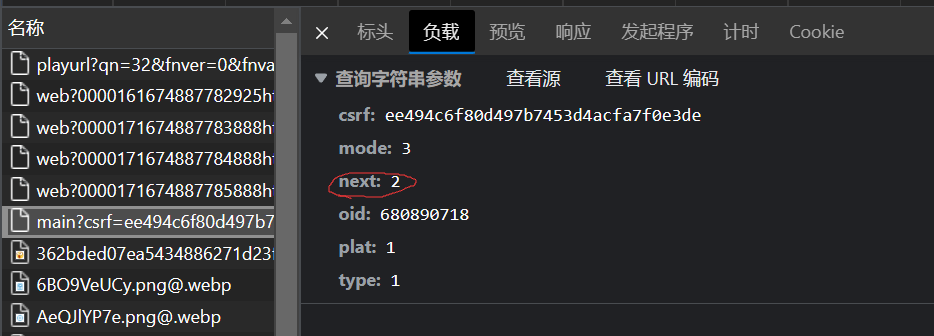
保存数据(.csv格式)
示例代码
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。