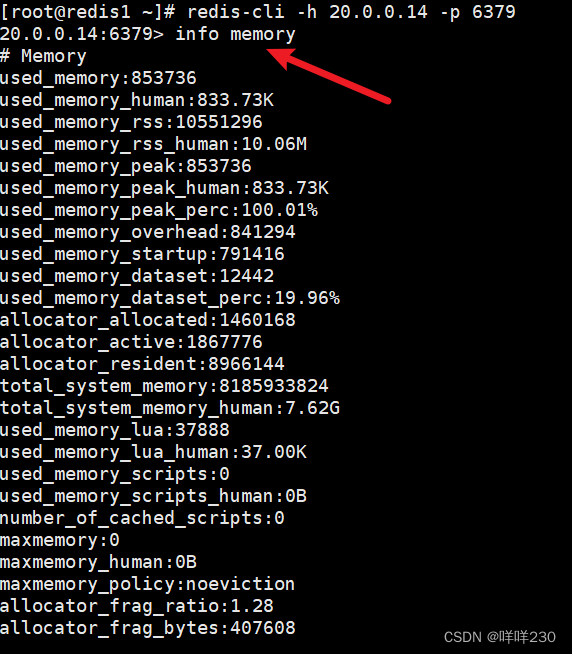
本文介绍: 分配器碎片的比例(越小越好,值越高,内存浪费越多)redis主进程调度时产生的内存分配器占用物理内存的比例主进程调度时占用的物理内存redis占用物理空间额外的开销比例(比例越低越好,redis实际占用的物理内存和向系统申请的内存越接近,额外的开销越低)RSS是redis向系统申请的内存空间内存碎片率(越低越好,内存使用率越高)
一、redis的性能管理
1、内存指标info memory
系统巡检:硬件巡检、数据库、中间件(nginx、redis)、docker、k8s
2、内存碎片率
(1)定义:系统已分配给redis,但reids未能有效利用的内存
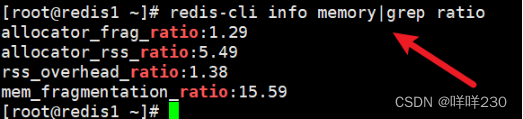
(2)计算格式:内存碎片率=used_memory_rss/used_memory
(3)监控指标redis–cli info memory|grep ratio(生产环境常用)
3、清理内存的两种方式
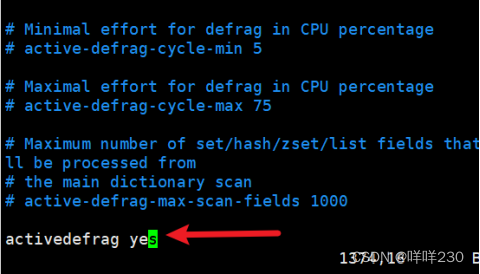
(1)自动清理碎片vim /etc/redis/6379.conf
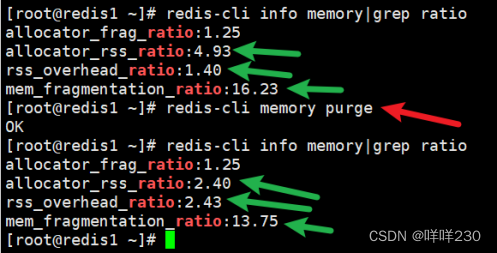
(2)手动清理碎片redis–cli memory purge
4、设置redis的最大内存阀值
(1)先设置最大内存阀值vim /etc/redis/6379.conf
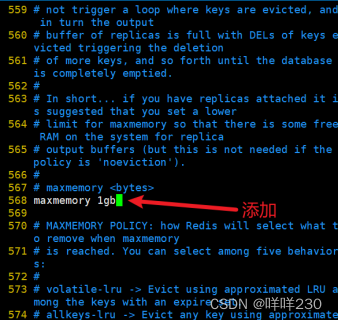
(2)再开启key的回收机制
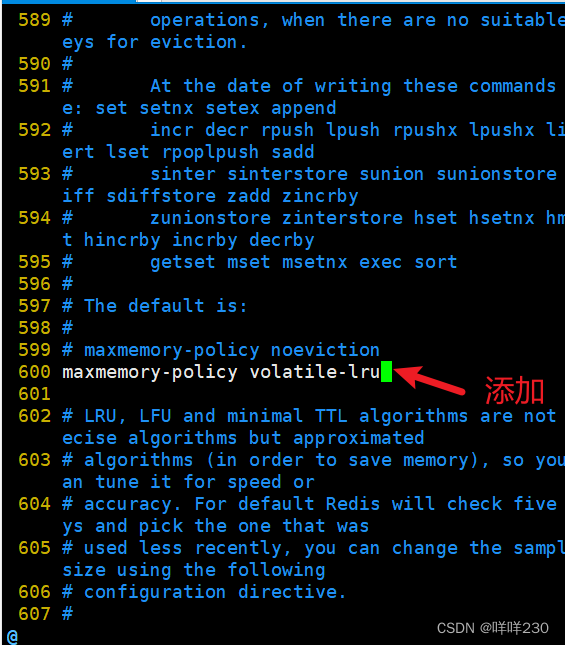
5、redis雪崩(缓存雪崩)(少见)
(1)定义
(2)产生雪崩的原因
(3)解决雪崩的方式
6、redis的缓存击穿(重点)
(1)产生原因
(2)解决方式
7、redis的缓存穿透(恶意攻击)(很少见)
二、redis的集群架构
1、高可用方案
(1)主从复制
(2)哨兵模式
(3)redis集群
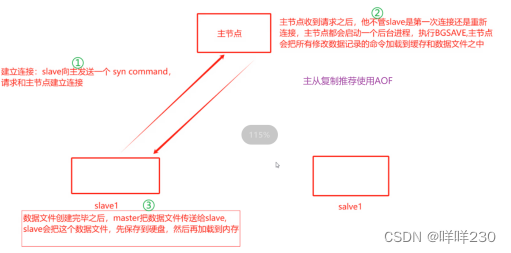
2、主从复制
3、主从复制的工作原理
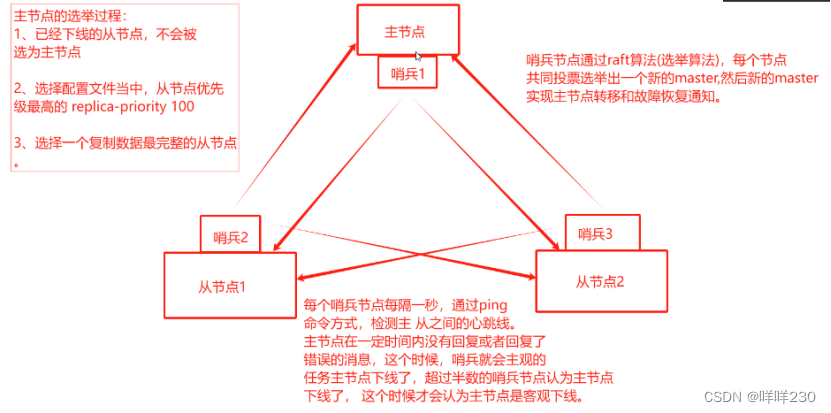
4、哨兵模式
(1)哨兵模式定义
(2)哨兵模式的结构
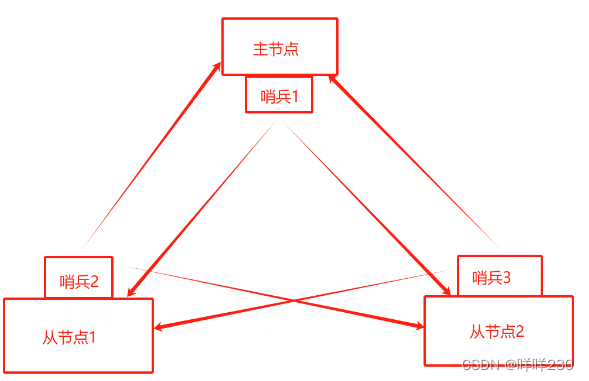
(2)哨兵模式工作原理
(4)如何选举新的主节点
(5)主节点的选举过程
 三、主从复制+哨兵模式实验
三、主从复制+哨兵模式实验
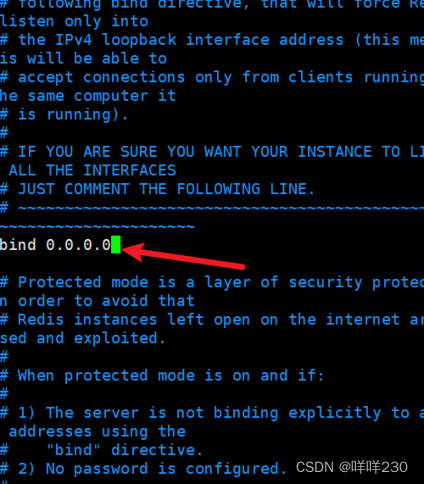
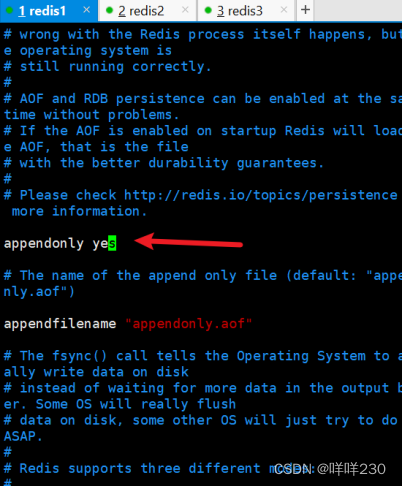
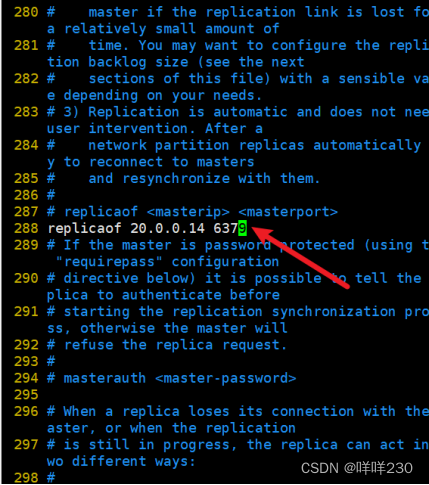
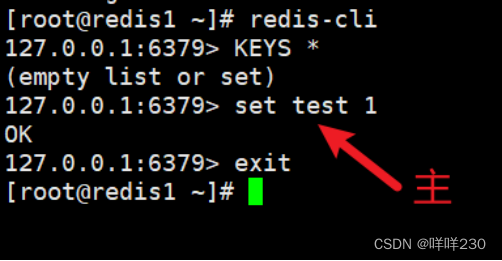
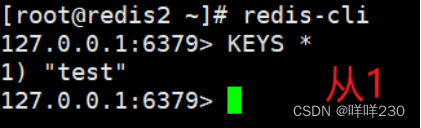
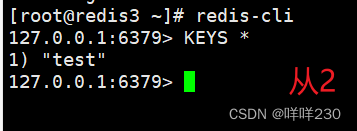
1、主从复制实验

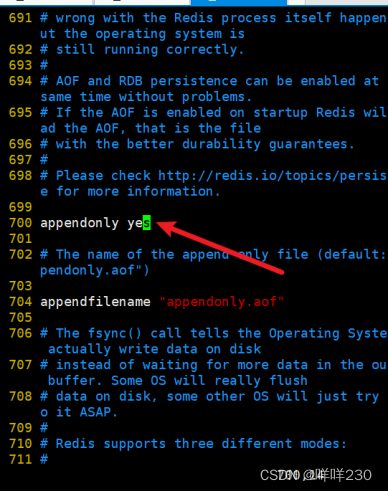
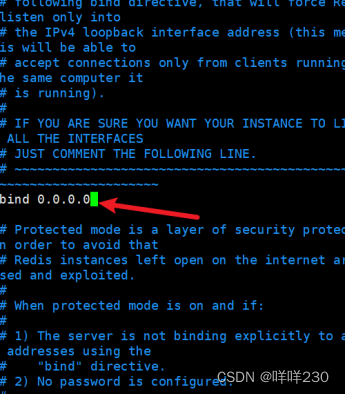
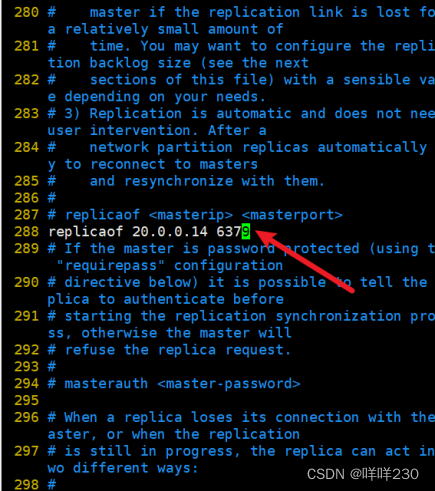
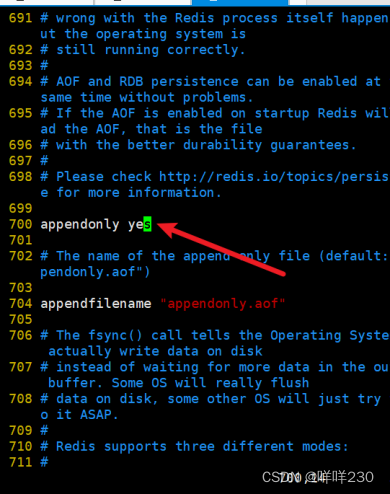
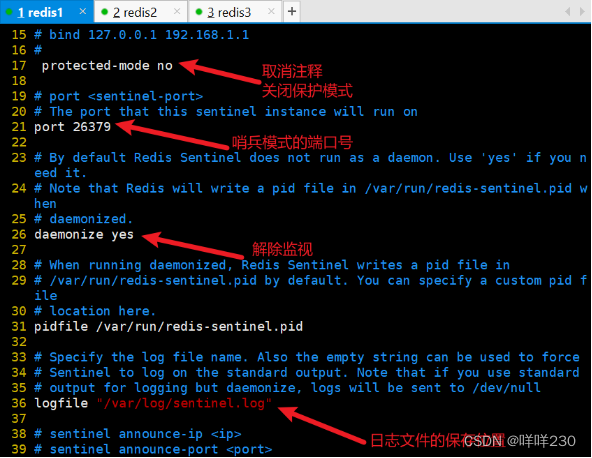
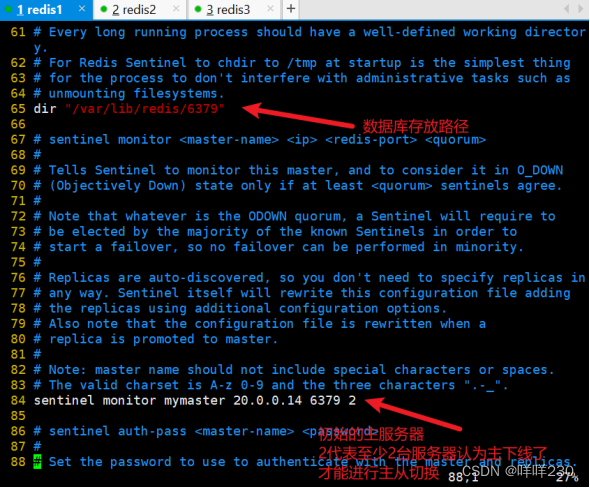
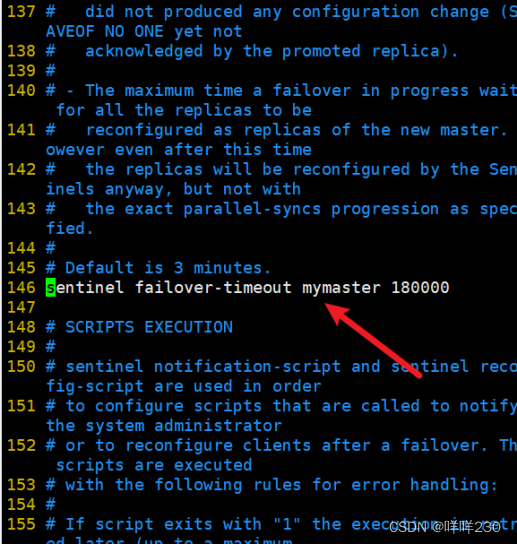
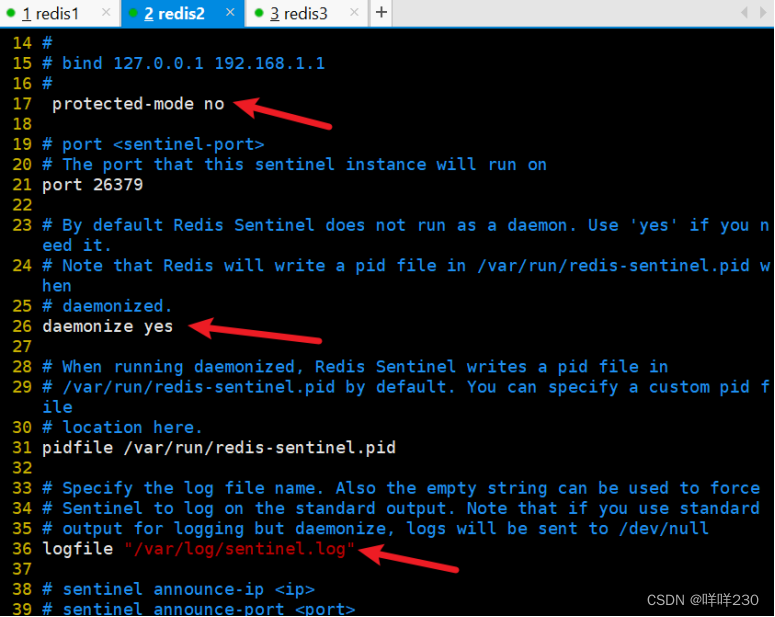
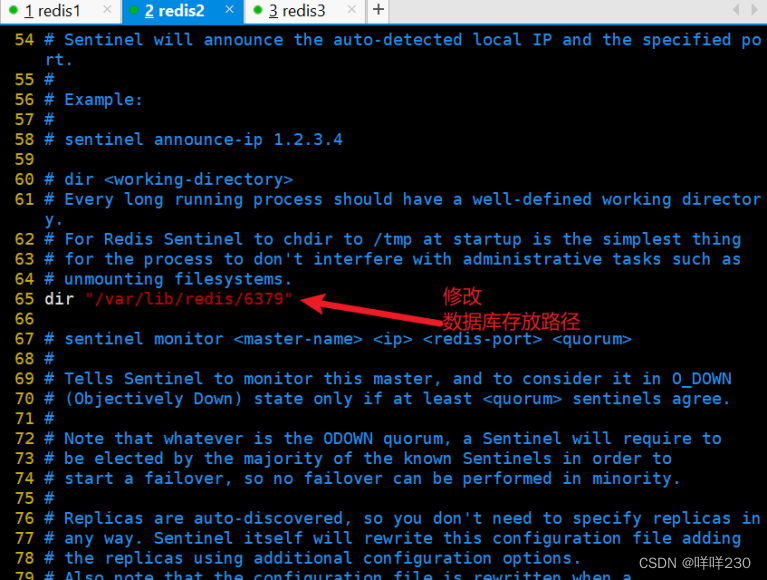
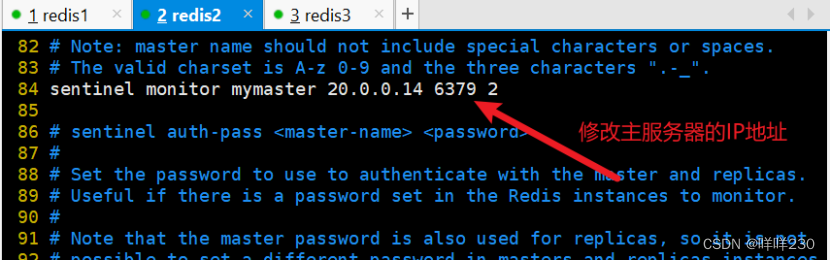
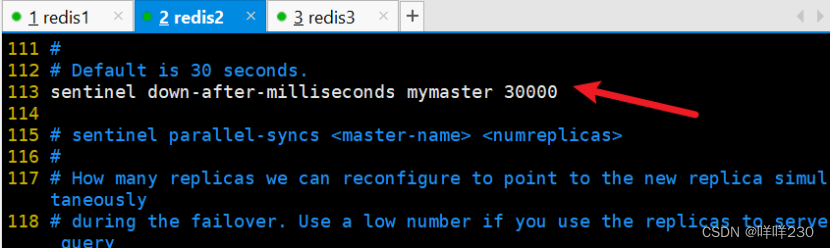
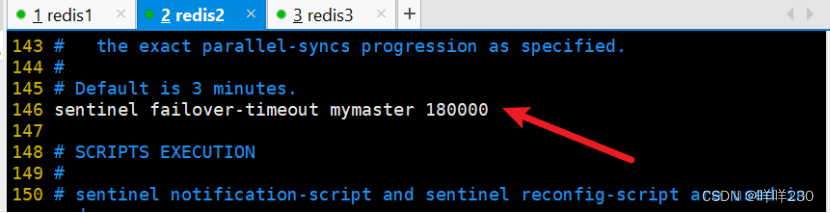
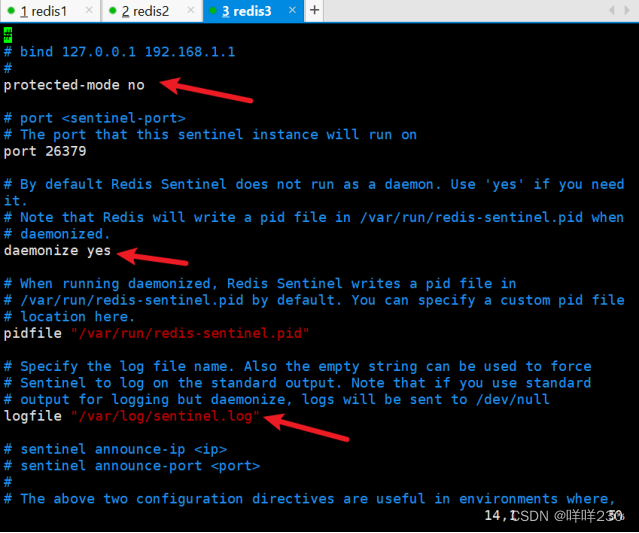
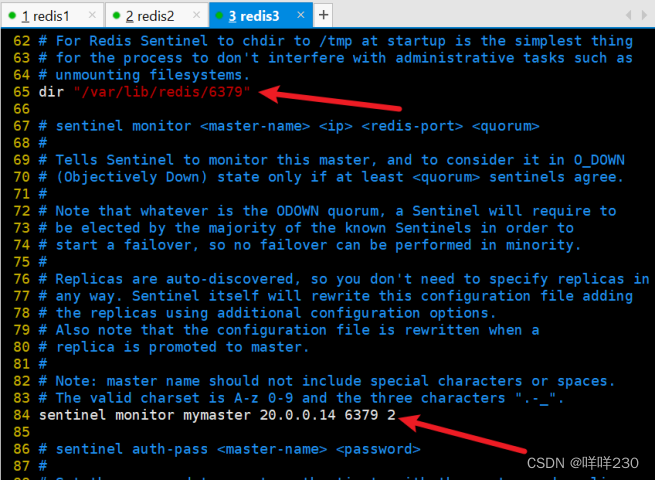
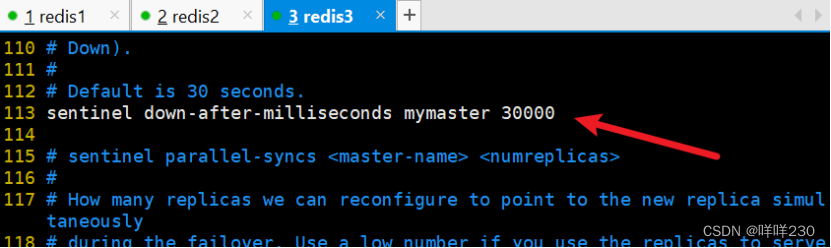
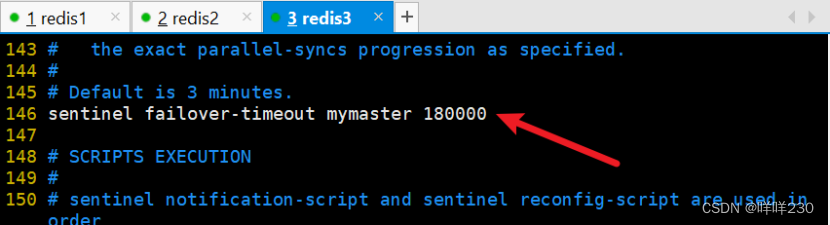
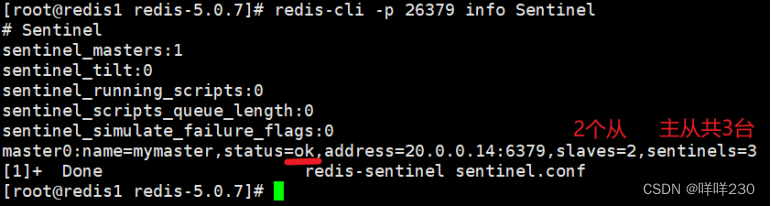
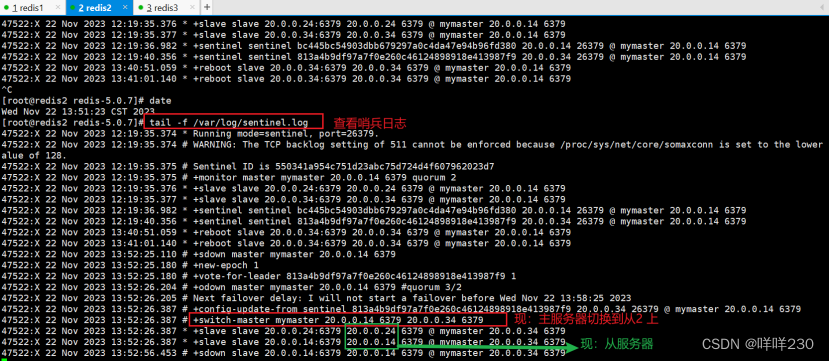
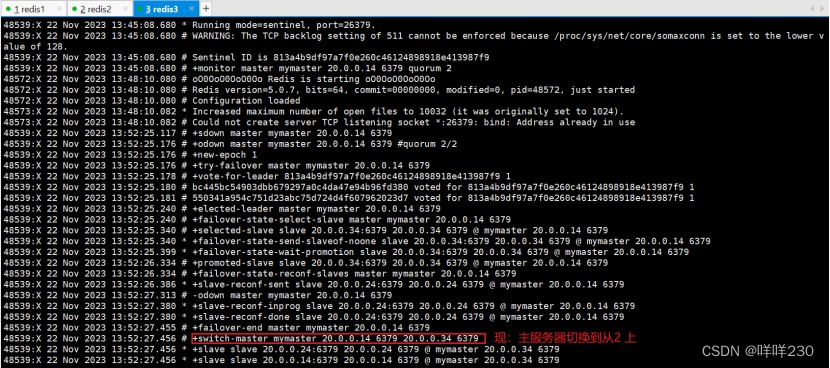
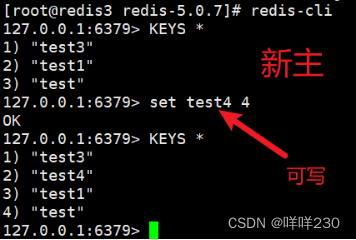
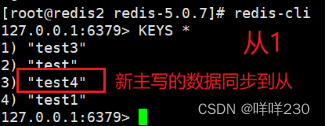
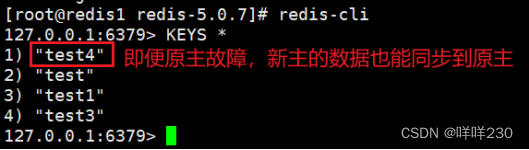
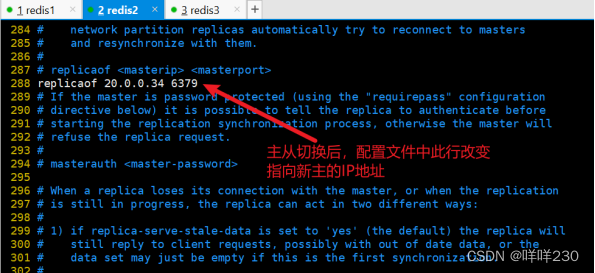
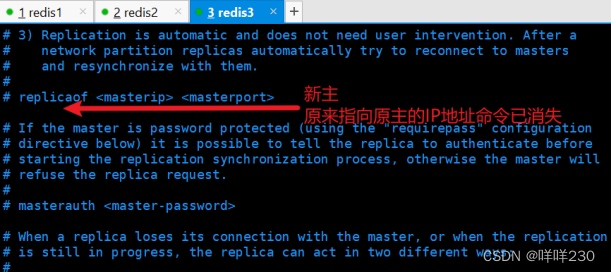
2、哨兵模式实验











声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






