1 Cache的与存储地址的映射
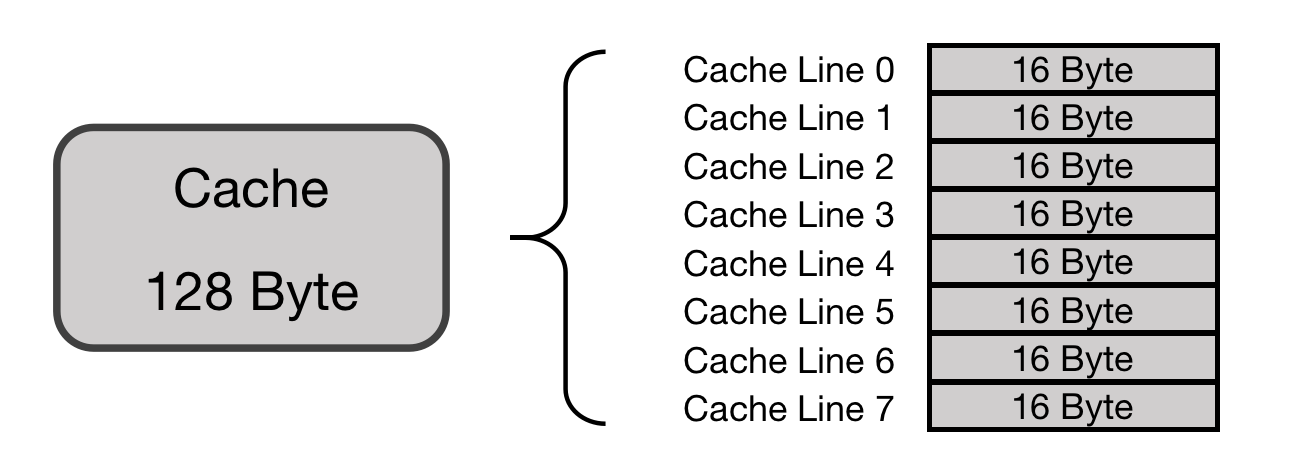
以一个Cache Size 为 128 Bytes 并且Cache Line是 16 Bytes的Cache为例。首先把这个Cache想象成一个数组,数组总共8个元素,每个元素大小是 16 Bytes,如下图:
现在考虑一个问题,CPU从0x0654地址读取一个字节,由于Cache大小相对于主存来说,是非常小的。所以Cache只能缓存主存中极小一部分数据。如何根据地址在有限大小的Cache中查找数据呢?现在硬件采取的做法是对地址进行散列(可以理解成地址取模操作)。分为如下多种映射方式,他们各有优劣,同时也有着继承与发展的关系
1.1 直接映射缓存(Direct Mapped Cache)
1.1.1 地址映射方式
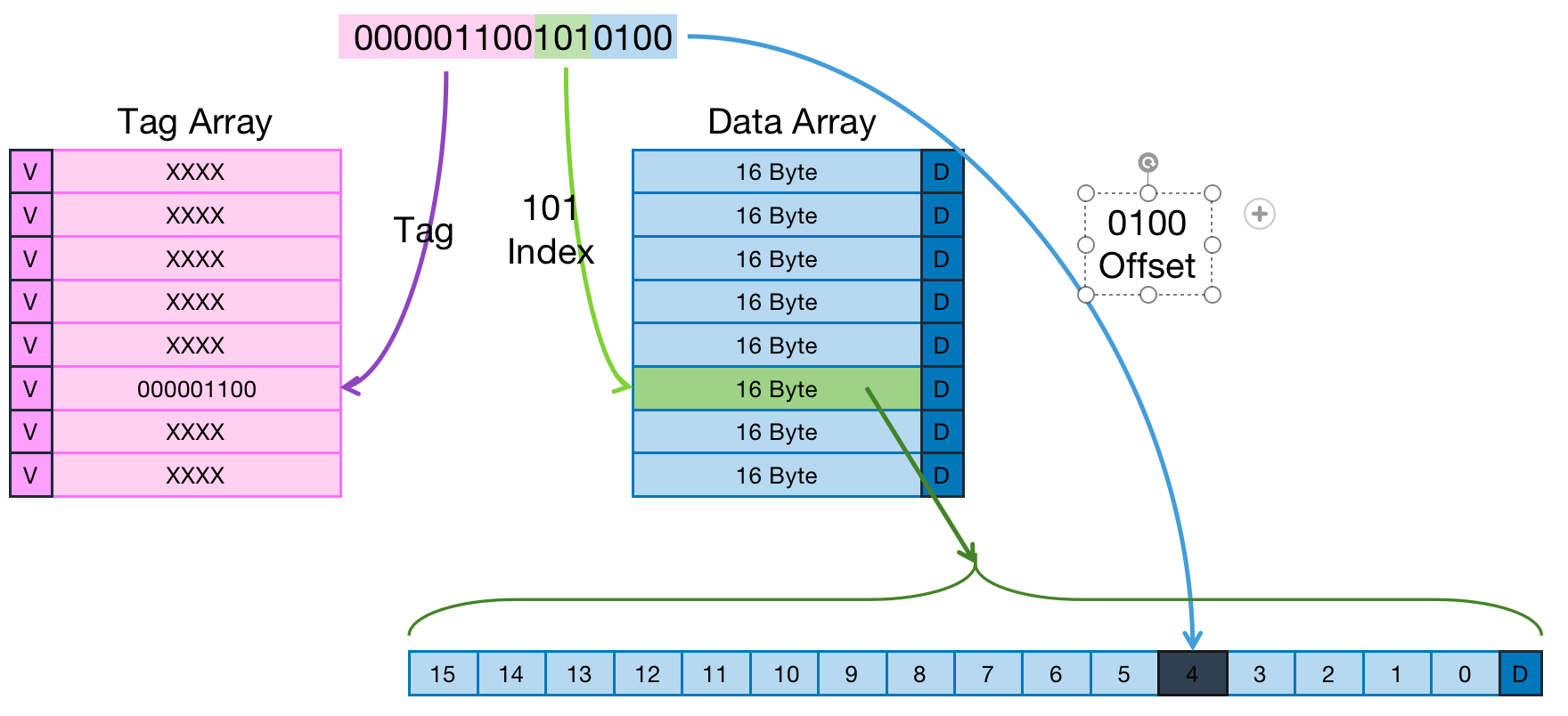
- Cache Size是128 Byte
- Cache Line size是16 Byte—–offset:4bit
- 共计8个Cache Line————-index:3bit
- 假设地址宽度是16 bit———–tag:9bits
根据直接映射缓存的工作方式,可以计算出不同主存地址段和对应的Cache
| 地址段 | Cahce Line Index |
|---|---|
| 0x0000-0x000F,0x0080-0x008F,… | 0 |
| 0x0010-0x001F,0x0090-0x009F,… | 1 |
| 0x0020-0x002F,0x00A0-0x00AF,… | 2 |
| 0x0030-0x003F,0x00B0-0x00BF,… | 3 |
| 0x0040-0x004F,0x00C0-0x00CF,… | 4 |
| 0x0050-0x005F,0x00D0-0x00DF,… | 5 |
| 0x0060-0x006F,0x00E0-0x00EF,… | 6 |
| 0x0070-0x007F,0x00F0-0x00FF,… | 7 |
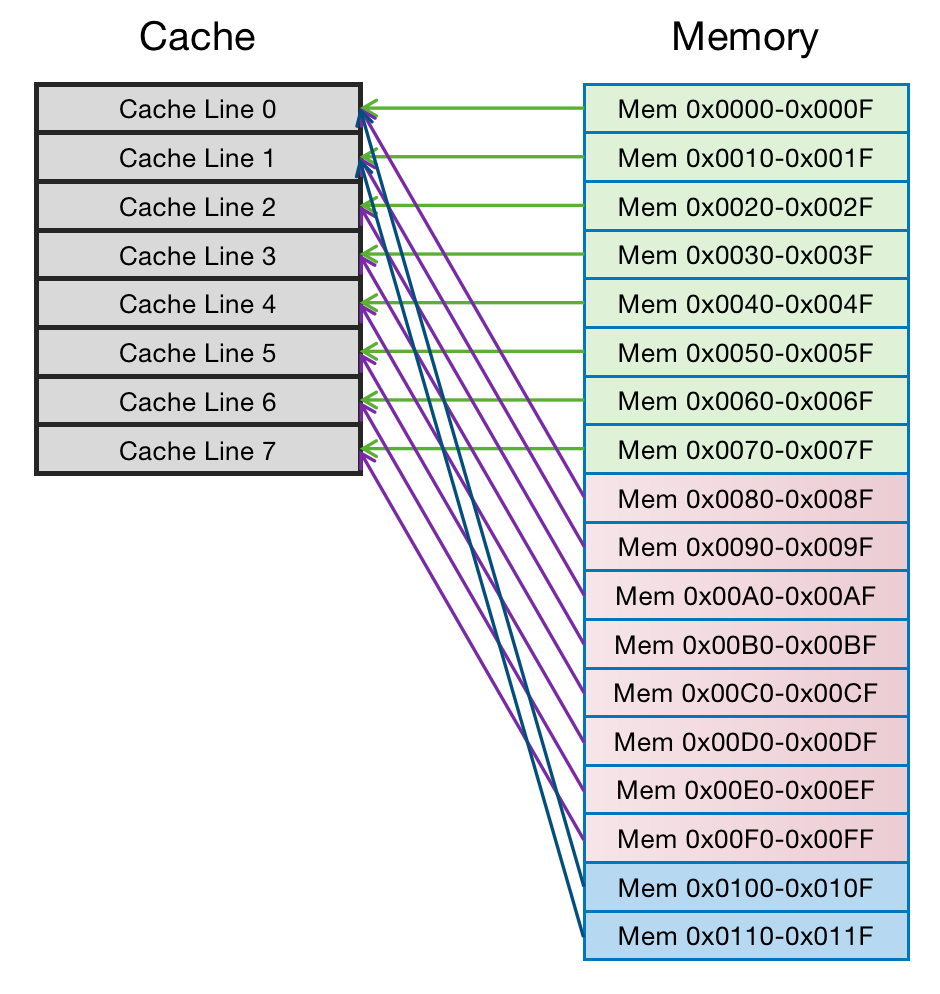
可以看到,地址0x0000-0x007F地址(0x0000-0x000F~0x0070-0x007F)处对应的数据可以覆盖整个Cache。0x0080-0x00FF地址的数据也同样是覆盖整个Cache。
1.1.2 直接映射缓存的优缺点
优点:
缺点:
针对这个问题,在后面的文章中引入多路组相连缓存优化规避这一问题。(首先介绍学习两路组相连缓存)
1.2 两路组相连缓存(Two-way Set Associative Cache)
1.2.1 地址映射方式
依然使用本章的例子(Cache Size 128 Bytes ,Cache Line 16 Byte),引入新的概念路(Way),将Cache平均分成多份,每一份就是一路。因此,两路组相连缓存就是将Cache平均分成2份,每份64 Bytes。将所有索引一样的Cache Line组合在一起称之为组(下图中用绿色的框表示)。所以当Way=2时候,Set=4(Set*Way = Cache Line Count)。如下图所示。
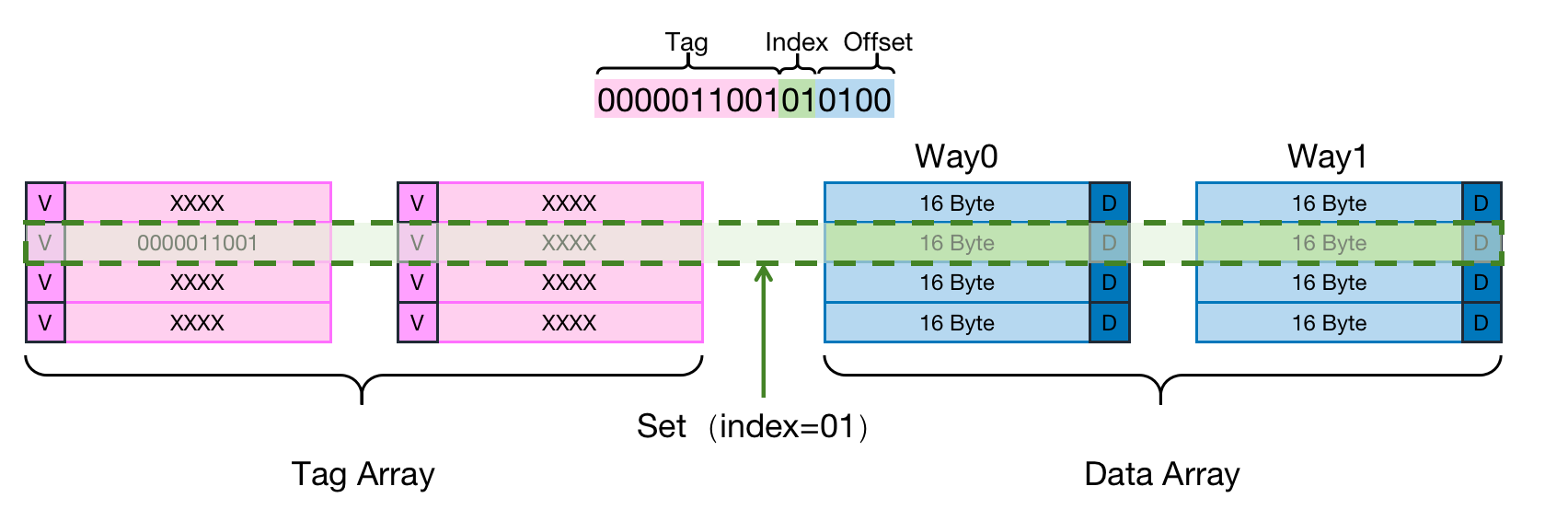
- Cache Size是128 Byte
- Cache Line size是16 Byte—–Offset:4bit(与直接映射缓存相同,因为Cache Line Size 没有变)
- 共计4个Set———————-Index:2bit(因为被平均分成了2 Way,每一个Set有2个Cache Line,共计4个Set,只需要2bit即可完成索引)
- 假设地址宽度是16 bit———–Tag:10bits(索引处少了一位,所以tag处需要多1 bit)
依然假设从地址0x0654地址读取一个字节数据。在上述例子中,会有如下操作:
- 根据Index=01找到第2行Cache Line,第2行对应2个Cache Line,分别对应Way 0和Way 1。因此Index也可以称作Set Index(组索引)。
- 将Set Index=01的组内的所有Cache Line对应的tag取出来和地址中的tag部分对比,如果其中一个相等就意味着命中。
因此,两路组相连缓存较直接映射缓存最大的差异就是:
1.2.2 两路组相连缓存的优缺点
**缺点:**硬件成本相对于直接映射缓存更高:因为其每次比较tag的时候,开销更大。根据Set Index索引到对应组之后,由于组内有两个Cache Line,所以也会对应的有两个Tag。
**优点:**有助于降低Cache颠簸可能性。
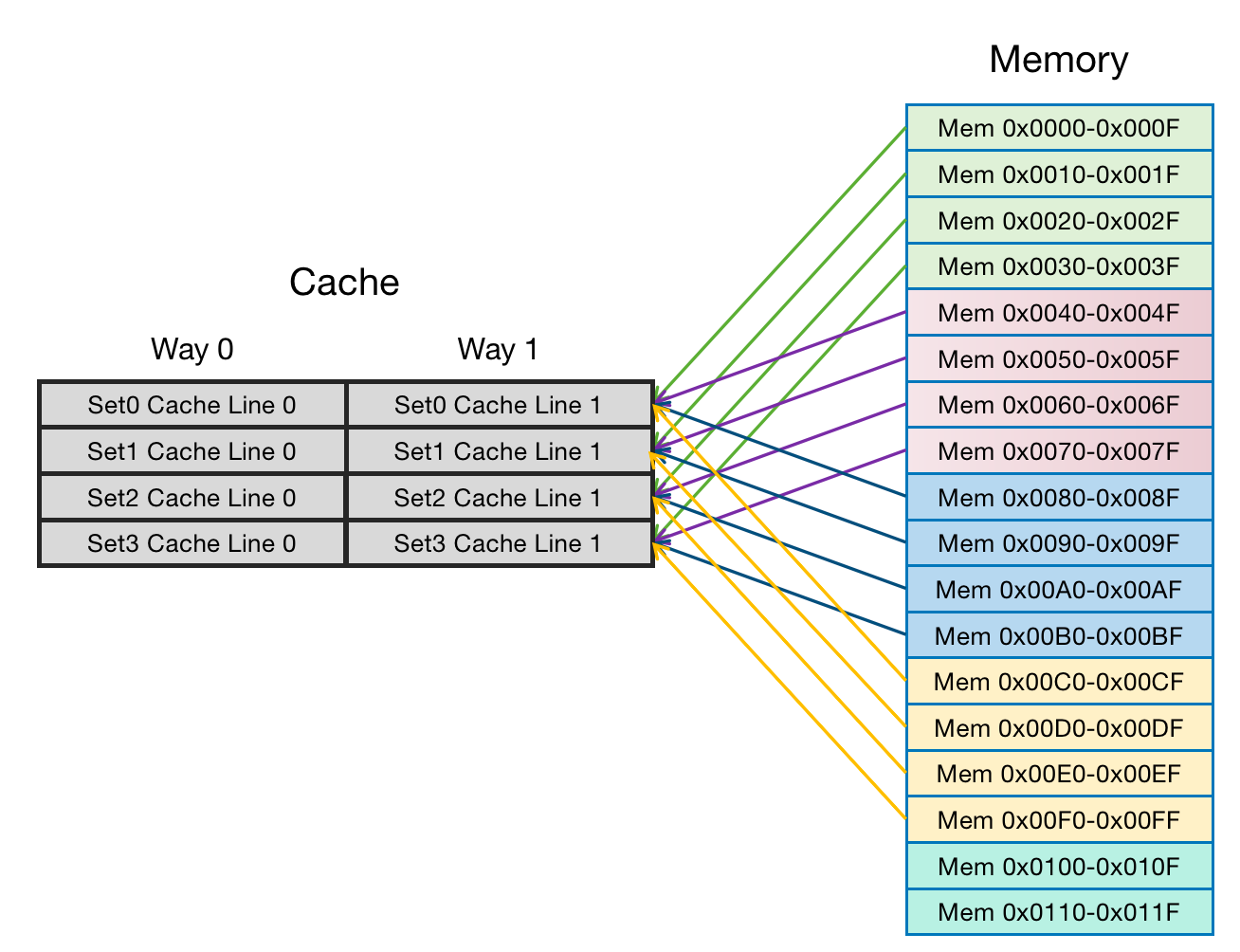
根据两路组相连缓存的工作方式,可以画出主存地址0x0000-0x00FF地址对应的Cache分布图。同时在问题“程序试图依次访问地址0x0000、0x0080、0x0100”中比较两者Cache性能。
-
直接映射缓存:0x0000、0x0080、0x0100地址中index部分是一样的。因此,这3个地址对应的Cache Line是同一个。当分别访问三个地址的时候都会发生Cache缺失,然后数据会发生替换从主存中加载数据。出现Cache颠簸(Cache thrashing)。
-
两路组相连缓存:0x0000、0x0080、0x0100地址中index部分也是一样的。因此,这3个地址会对应到相同的组,但是由于有两个Way,在第一个数据0x0000加载进来的情况下放置在Way 0,再访问第二个数据0x0080,也不会替换,仅是将他放在Way1 中。避免了Cache颠簸。
因此,当Cache size一定的情况下,组相连缓存对性能的提升最差情况下也和直接映射缓存一样,在大部分情况下组相连缓存效果比直接映射缓存好。同时,其降低了Cache颠簸的频率。从某种程度上来说,直接映射缓存是组相连缓存的一种特殊情况,每个组只有一个Cache Line而已。因此,直接映射缓存也可以称作单路组相连缓存。
1.3 全相连缓存(Full associative Cache)
1.3.1 地址映射方式
组相连的另一个极端情况,将Way的数量扩大至最大,这就是全向相连缓存,即为所有的Cache Line都在一个组内。这种缓存就是全相连缓存。
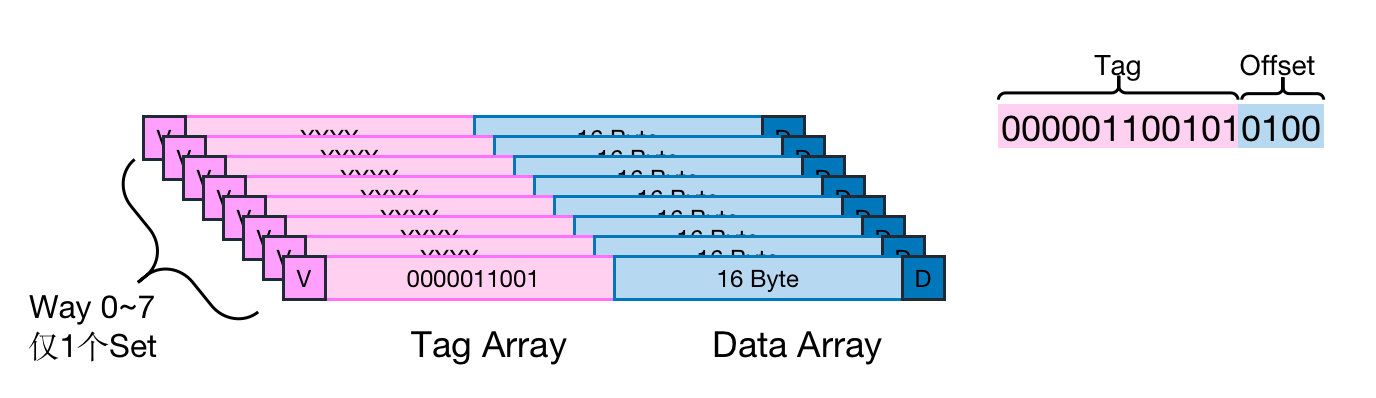
- Cache Size是128 Byte
- Cache Line size是16 Byte—–Offset:4bit(与直接映射缓存相同,因为Cache Line Size 没有变)
- 仅有1个Set———————-Index:0bit(因为被平均分成了8 Way,每一个Set有8个Cache Line,所有的Cache Line都在1个Set内,因此地址中不需要set index部分。因为,只有一个组让你选择,不需要设置索引即可完成定位。)
- 假设地址宽度是16 bit———–Tag:12bits(索引处少了3位,所以tag处需要多3 bit)
1.3.2 全相连缓存优缺点
缺点:
需要根据地址中的tag部分和唯一组内的所有的Cache Line对应的tag进行比较(硬件上可能并行比较也可能串行比较)。哪个tag比较相等,就意味着命中某个Cache Line。因此,在全相连缓存中,任意地址的数据可以缓存在任意的Cache Line中。但是硬件成本上也是更高。
优点:
原文地址:https://blog.csdn.net/qq_41554005/article/details/134626286
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_15735.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!