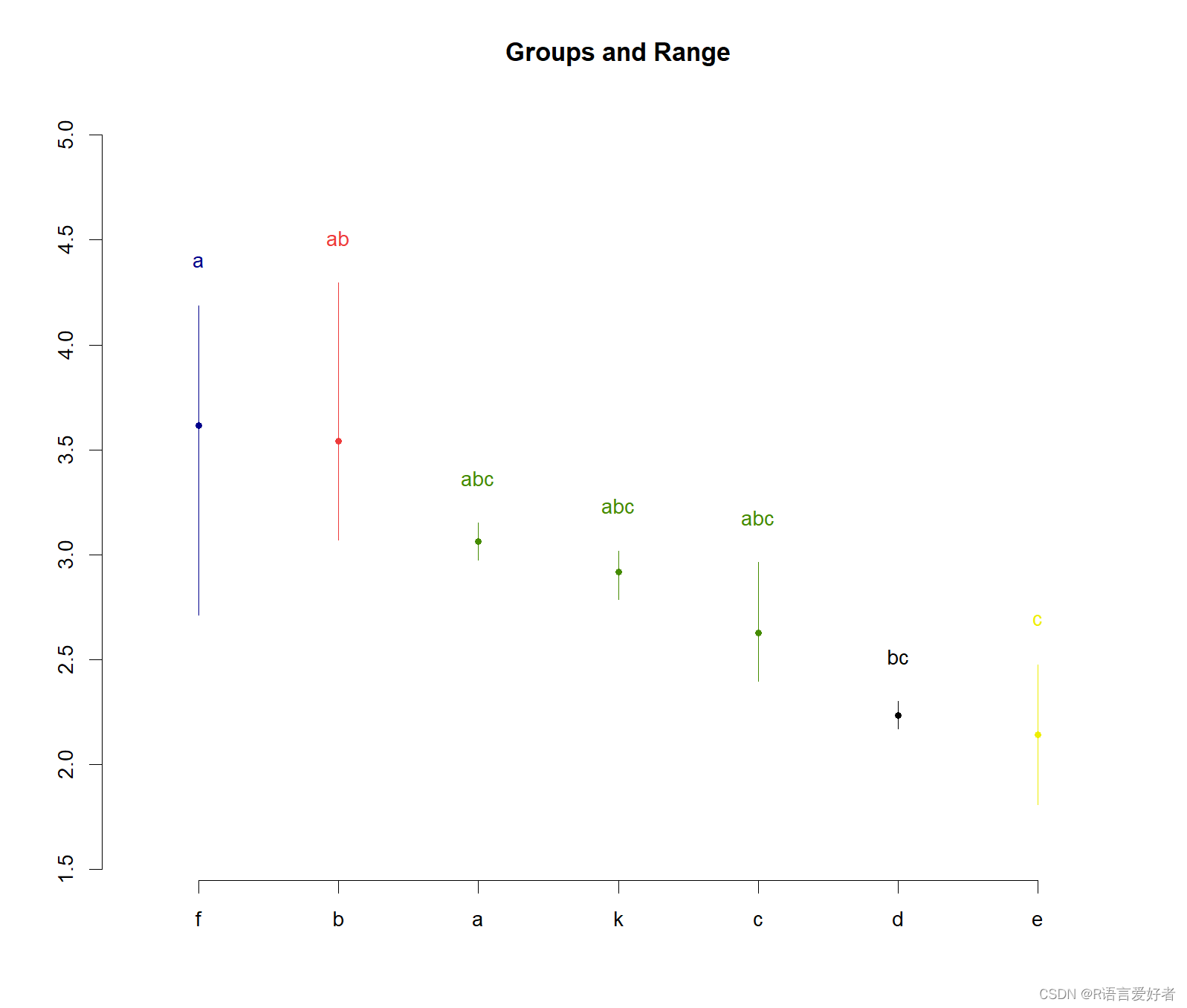
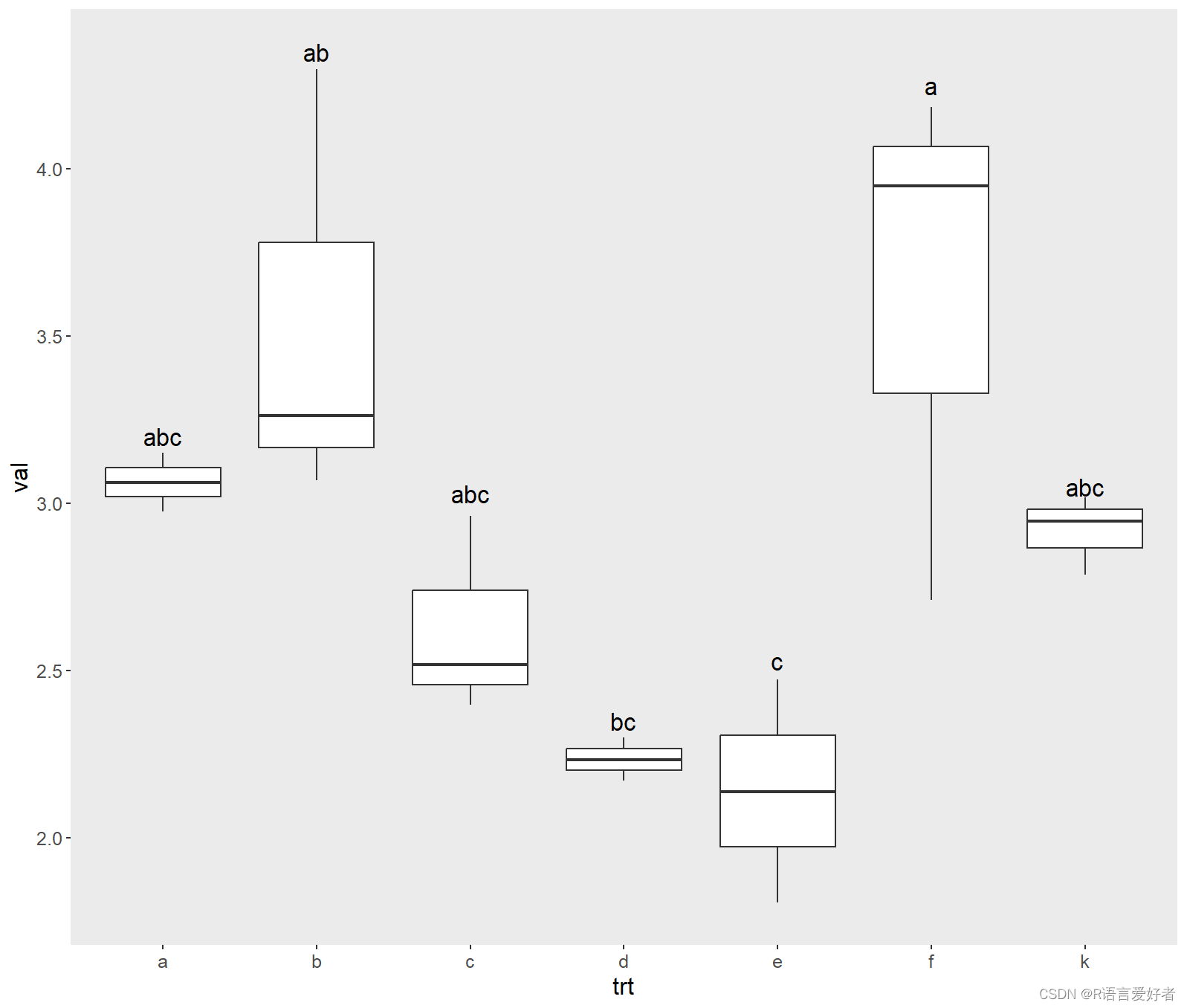
查看方差分析结果:
其中Pr(>F)=0.00661<0.05,说明组间存在差异显著
接下来对上述结果进行详细解释:
groups这一列的结果可以理解为找同类,其中val这列是按照均值从大到小排列,先把最大的标记为a,然后,找f的同类,凡是同类都标为a,直到找到第一个异类,然后标记为b,同时停止往下再找f的同类了,然后,开始找标记为b的同类,也就是d: 2.234612同类,先往上找同类,找到的都标为b,直到找完为止,然后再往下找同类,直到找到第一个异类,然后标记为c,然后重复这种工作。最后,这个同类就是两者间是不否存在差异显著性,异类就是存在差异显著性。
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。