为什么尝试使用Tencent Cloud VectorDB替换Milvus向量库?
亮点:Tencent Cloud VectorDB支持Embedding,免去自己搭建模型的负担(搭建一个生产环境的模型实在耗费精力和体力)。
腾讯云向量数据库是什么?
腾讯云向量数据库是一款全托管的自研企业级分布式数据库服务,专用于存储、检索、分析多维向量数据。该数据库支持多种索引类型和相似度计算方法,单索引支持10亿级向量规模,可支持百万级 QPS 及毫秒级查询延迟。腾讯云向量数据库不仅能为大模型提供外部知识库,提高大模型回答的准确性,还可广泛应用于推荐系统、NLP 服务、计算机视觉、智能客服等 AI 领域。
Milvus是什么?
Milvus是在2019年创建的,其唯一目标是存储、索引和管理由深度神经网络和其他机器学习(ML)模型生成的大规模嵌入向量。作为一个专门设计用于处理输入向量查询的数据库,它能够处理万亿级别的向量索引。与现有的关系型数据库主要处理遵循预定义模式的结构化数据不同,Milvus从底层设计用于处理从非结构化数据转换而来的嵌入向量。
项目展示
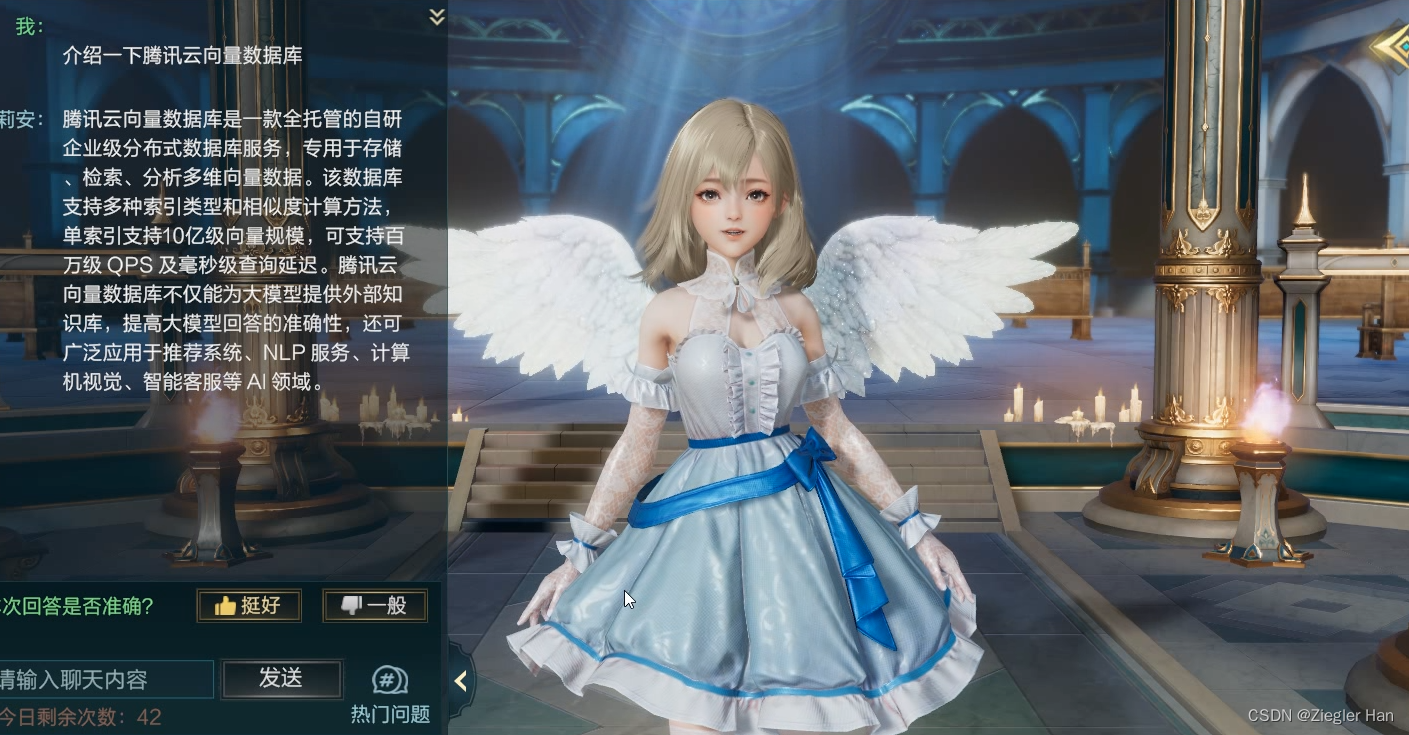
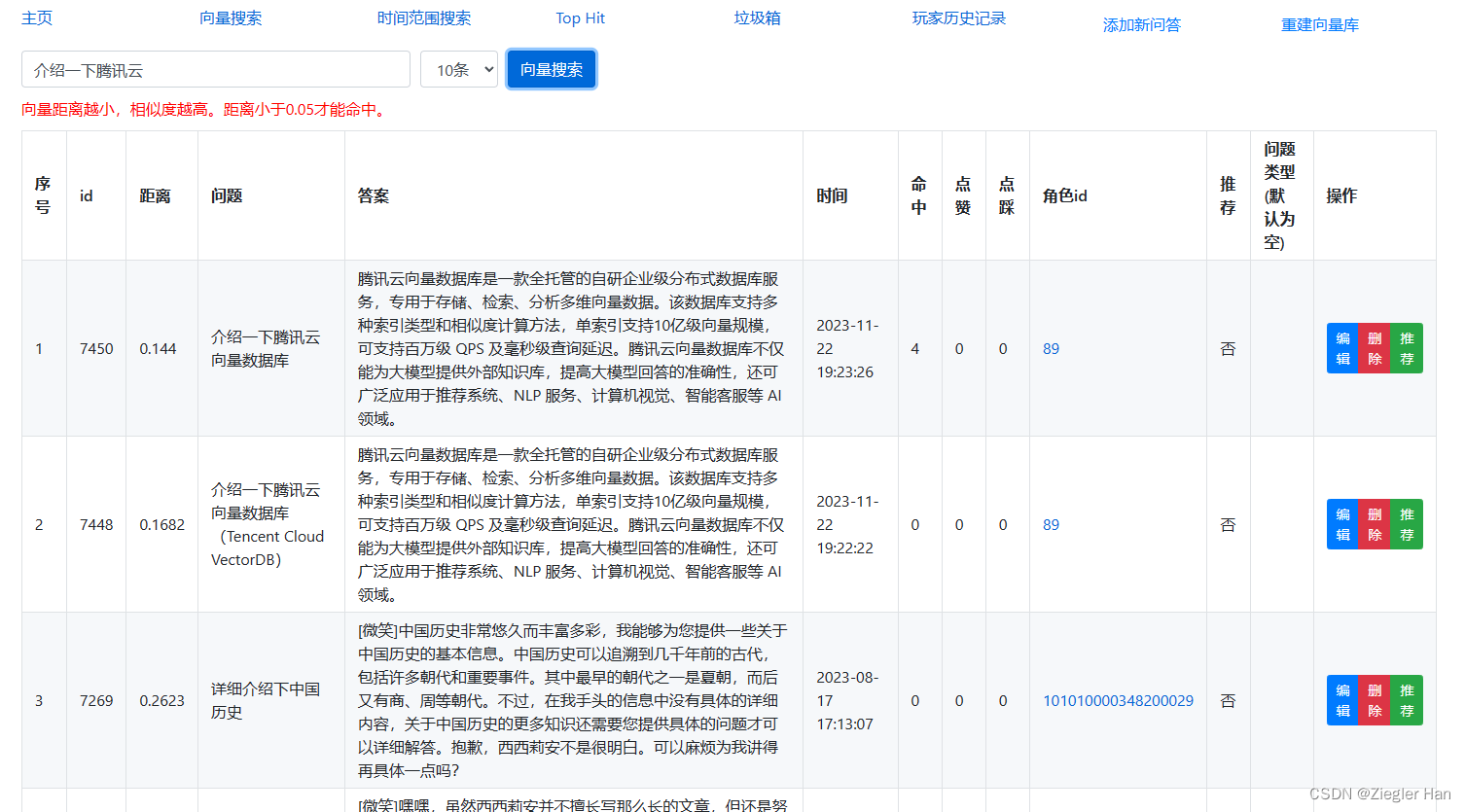
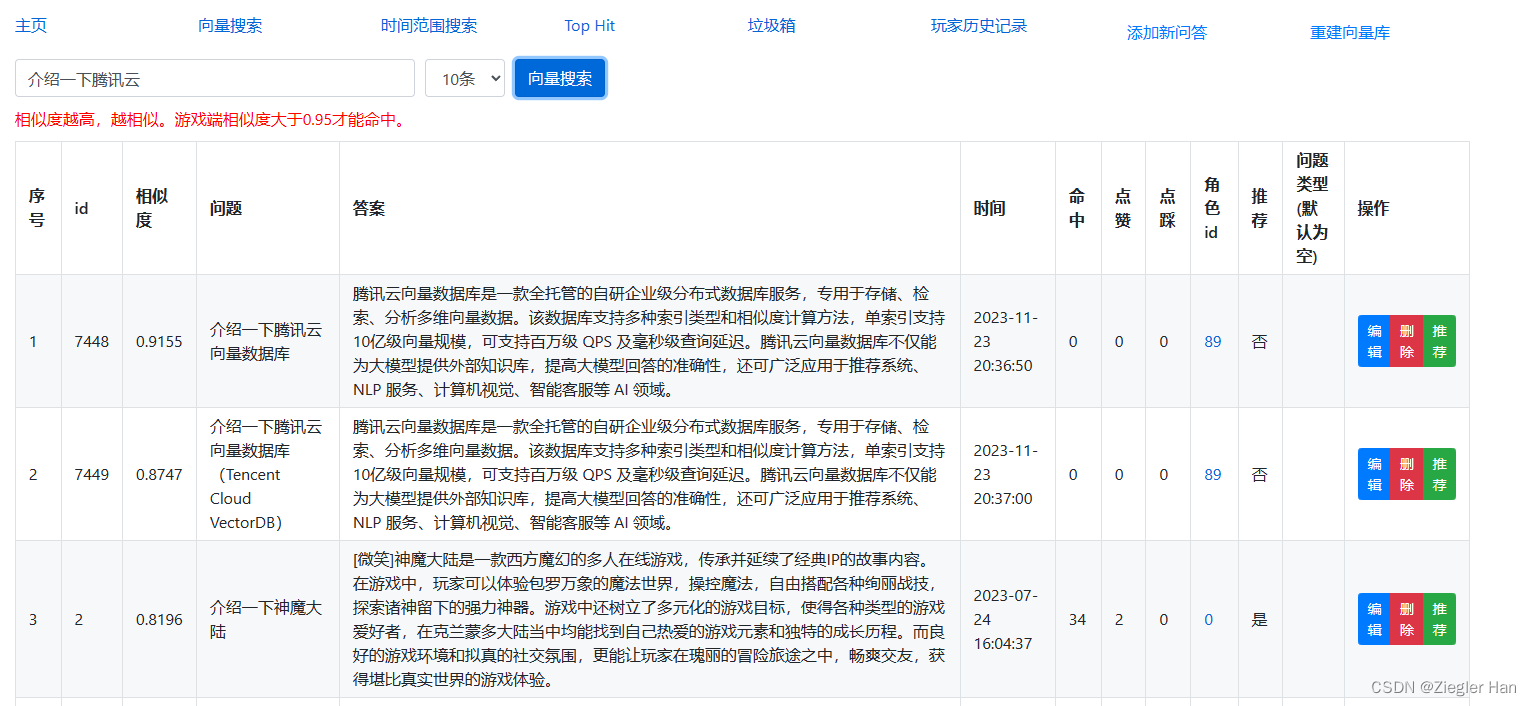
项目介绍游戏内部接入ChatGPT的智能NPC,可以与她进行语音交流。可以回答与游戏相关的问题(这个专业问题是为了编写这个文章,专门添加到问答缓存库中的,游戏内会拒绝回答此类问题)。为了加快ChatGPT的回复速度和降低ChatGPT的费用,增加问答缓存机制。这里运用向量数据库的相似文本相似度高的特性,通过向量搜索,匹配相似度大于一定值,例如:0.95。搜索到相似问题,直接返回答案,不在进行ChatGPT访问。
其次,存在缓存,针对相似问题,还可以给予特定回复答案。例如上面示例,当提问“介绍一下腾讯向量数据库”,直接回复“腾讯云向量数据库是一款全托管的自研企业级分布式数据库服务,专用于存储、检索、分析多维向量数据。该数据库支持多种索引类型和相似度计算方法,单索引支持10亿级向量规模,可支持百万级 QPS 及毫秒级查询延迟。腾讯云向量数据库不仅能为大模型提供外部知识库,提高大模型回答的准确性,还可广泛应用于推荐系统、NLP 服务、计算机视觉、智能客服等 AI 领域。”
为什么使用向量数据库?
重点:速度
向量相似度匹配是很长的数组,例如:bge-large-zh模型文本转向量,生成的是768维的float数组。拿问题文本转换为的768维向量与缓存的所有问题的向量进行相似性计算,然后获取最相似的几条数据,这个运算量非常大,速度非常慢。
测试代码:
与300个768维向量进行相似比对,获取最相似的一条数据,耗时几秒钟。按照这个速度,如果与几千上万条数据进行这么计算,简直无法忍受。
这时就必须使用向量数据库了,向量数据库可以支持毫秒级检索上百万行数据。本人曾使用Milvus数据库,分别插入1000行数数据和插入10万行数据,然后进行搜索对比,都在几十毫秒返回结果,数据量的增多,对检索速度几乎没有任何影响。