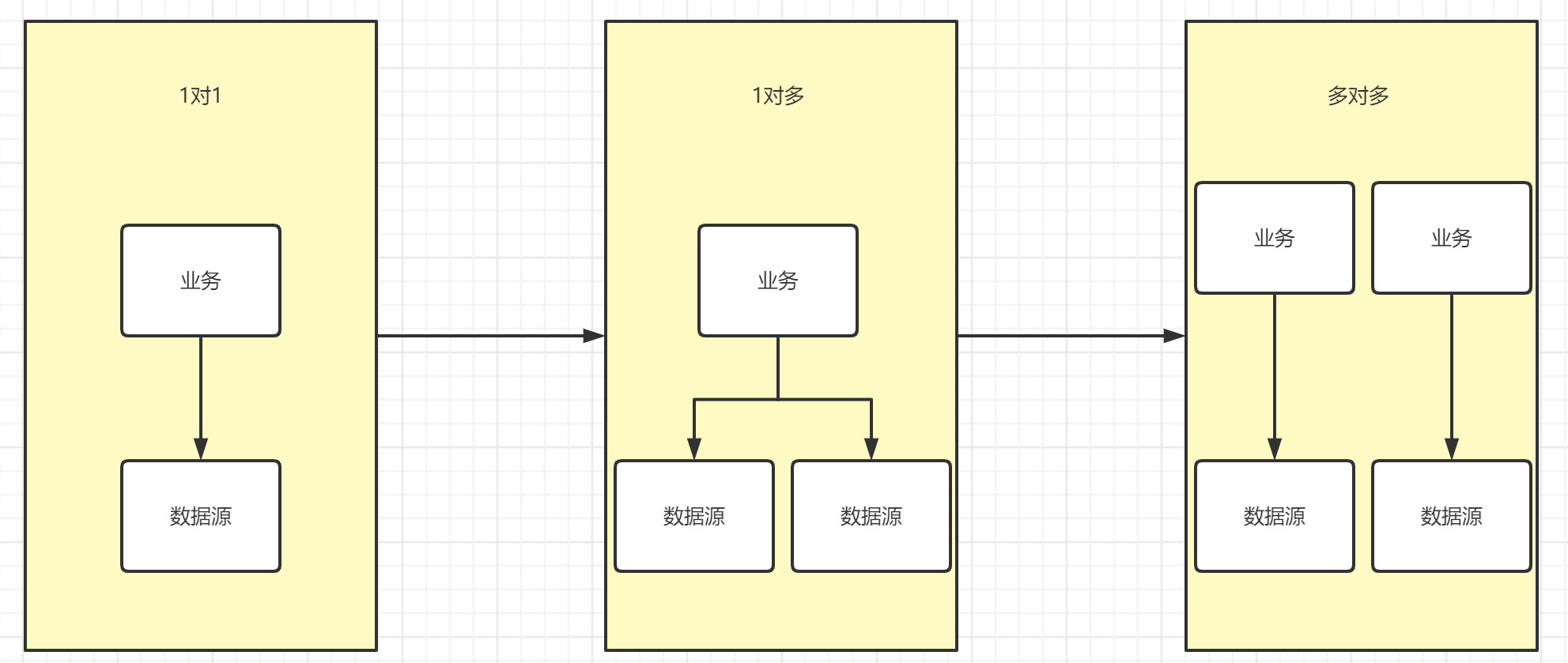
最近回顾了微软的Cosmos DB的提供一致性级别,重新整理下一致性模型的相关内容。
0. Cosmos DB
Cosmos DB(Azure Cosmos DB)是由微软推出的一个支持多模型、多 API 的全球分布式数据库服务。它旨在提供高度可扩展性、低延迟、强一致性和全球分布的能力,以满足各种应用程序的要求。关键特性如下:
一、一致性模型
在之前的一篇文章:浅谈CAP+ACID+BASE理论 介绍了在为什么会有CAP理论( PACELC theorem),其中C就是本身所述的一致性模型。
理想情况下,真正的一致性模型只有一种,即强一致性(或者说严格一致性,或者说满足linearizability )。
二、Cosmos DB-一致性模型
Cosmos DB特点在于:目前市场上大多数商业可用的分布式NoSQL数据库仅提供强一致性和最终一致性。Azure Cosmos DB却提供了五个明确定义的一致性级别,从最强到最弱分别是:
Cosmos DB提供更为精准的一致性模型选择,客户可以基于业务自身需求以及真实场景,选择合适的一致性模型,从而在读写耗时、吞吐、性能、一致性等多个角度获取权衡。
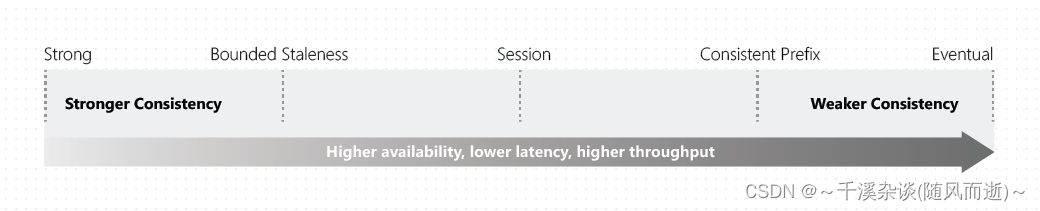
2.1 Strong
2.2 Bounded staleness consistency
2.3 Session consistency
Read-Your-Writes (RYW)
Write-Follows-Reads (WFR)
工作流程
2.4 Consistent prefix consistency
2.5 Eventual consistency
三、Cosmos DB 一致性模型总结
3.1 latency-延迟保
3.2 throughput-吞吐
3.3 data durability- 数据持久性
四、小结
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。