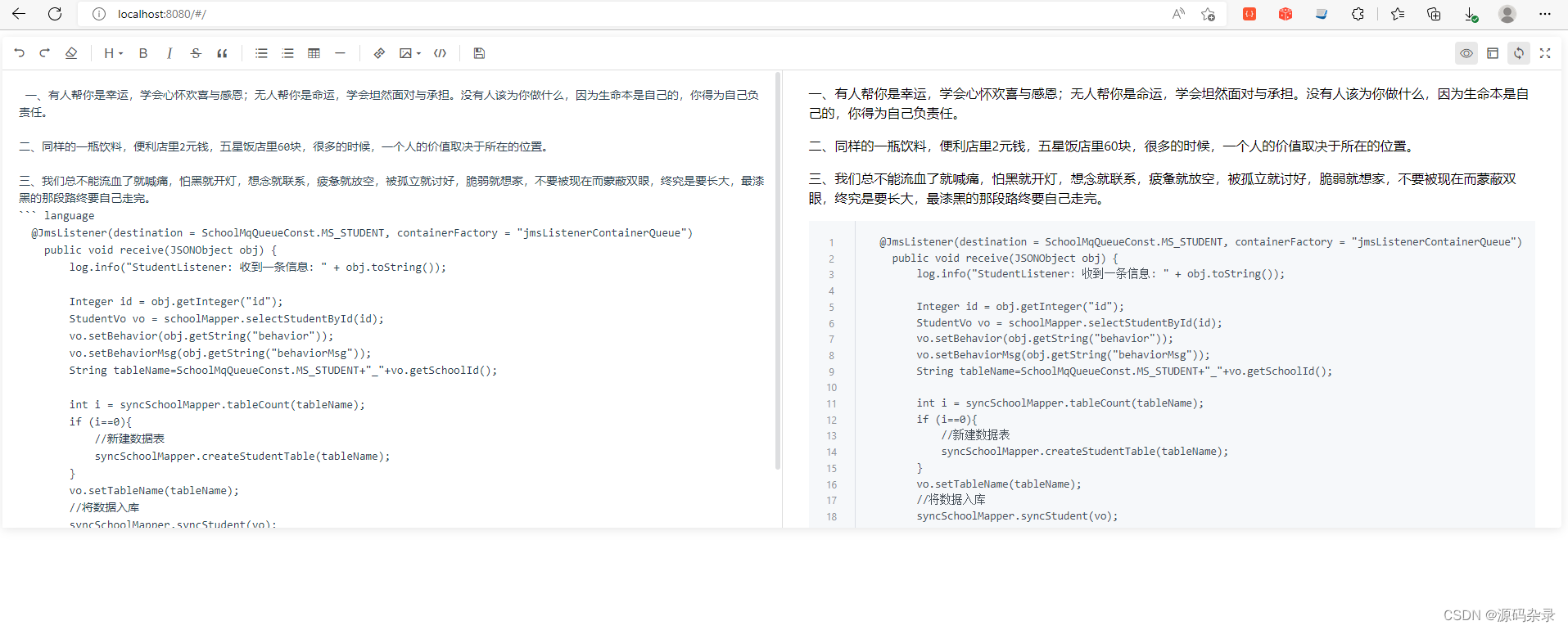
主要有以下几点:
1、解决富文本导入导出依赖兼容问题
2、处理富文本和非富文本内容
3、解决webp格式通过java下载不了问题,如果要用到富文本导出,将来势必是会碰到的bug,这里提前给提出来并解决,测试用例中有给图片测试。
4、在原有方法上优化,比如处理等比缩小图片、将图片本地路径,替换为minio或者base64格式
gitee测试用例:
链接: https://gitee.com/muyangrenOvo/word-import-export
注意:与文章代码有出入,但思路是一样的。只是获取文件的方式变了,一个是前端调用组件传的,一个是自己new file。
1)引入pom.xml依赖
<!--处理富文本导出导入word文档,勿修改依赖-->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>4.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml-schemas</artifactId>
<version>4.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>4.1.2</version>
</dependency>
<dependency>
<groupId>fr.opensagres.xdocreport</groupId>
<artifactId>xdocreport</artifactId>
<version>2.0.2</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-scratchpad</artifactId>
<version>4.1.2</version>
</dependency>
<dependency>
<groupId>io.github.draco1023</groupId>
<artifactId>poi-tl-ext</artifactId>
<version>0.4.2</version>
</dependency>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.3</version>
</dependency>
<!--解决ImageIO.read读取不了webp格式-->
<dependency>
<groupId>com.github.nintha</groupId>
<artifactId>webp-imageio-core</artifactId>
<version>0.1.0</version>
<!--第一次先取消下面两行注释,加载成功后,在恢复注释,并重新加载-->
<!--<scope>system</scope>-->
<!--<systemPath>${project.basedir}/libs/webp-imageio-core-0.1.0.jar</systemPath>-->
</dependency>
2) word文档导入带样式(含图片)
Controller层
@ApiLog("导入模板")
@PostMapping("/importTemplate")
@ApiOperation(value = "导入模板", notes = "传file")
public R<CaseInfoVO> importCase(@RequestParam MultipartFile file) {
return R.data(caseInfoService.importTemplate(file));
}
service层
import com.deepoove.poi.XWPFTemplate;
import com.deepoove.poi.config.Configure;
import com.deepoove.poi.config.ConfigureBuilder;
import fr.opensagres.poi.xwpf.converter.core.FileImageExtractor;
import fr.opensagres.poi.xwpf.converter.core.FileURIResolver;
import fr.opensagres.poi.xwpf.converter.core.XWPFConverterException;
import fr.opensagres.poi.xwpf.converter.xhtml.XHTMLConverter;
import fr.opensagres.poi.xwpf.converter.xhtml.XHTMLOptions;
import org.apache.poi.xwpf.usermodel.XWPFDocument;
import org.ddr.poi.html.HtmlRenderPolicy;
@Override
public CaseInfoVO importTemplate(MultipartFile file){
try {
caseInfoVO = new CaseInfoVO();
//1、处理非富文本内容基本信息(讲解的是富文本导入,所以该内容略过)
//List<Map<String, String>> mapList = WordUtil.readWord(file);
//assert mapList != null;
//dealWithCaseBasicInfo(caseInfoVO, mapList);
//2、下载文件到本地
File destFile = fileDownloadToLocalPath(file);
//3、处理案例富文本信息
dealWithCaseInfoRichText(caseInfoVO, destFile);
//4、替换案例富文本信息中的图片(如果有)路径并删除临时文件和临时图片
dealWithCaseInfoRichTextToPicture(caseInfoVO);
} catch (Exception e) {
e.printStackTrace();
}
return caseInfoVO;
}
private void dealWithCaseInfoRichText(CaseInfoVO caseInfoVO, File destFile) {
if (!destFile.exists()) {
throw new ServiceException("导入模板失败,请重新上传!");
} else {
//判断是否为docx文件
if (destFile.getName().endsWith(".docx") || destFile.getName().endsWith(".DOCX")) {
// 1)加载word文档生成XWPFDocument对象
try (FileInputStream in = new FileInputStream(destFile); XWPFDocument document = new XWPFDocument(in)) {
// 2)解析XHTML配置(这里设置IURIResolver来设置图片存放的目录)
File imageFolderFile = new File(String.valueOf(destFile.getParentFile()));
XHTMLOptions options = XHTMLOptions.create().URIResolver(new FileURIResolver(imageFolderFile));
options.setExtractor(new FileImageExtractor(imageFolderFile));
options.setIgnoreStylesIfUnused(false);
options.setFragment(true);
//使用字符数组流获取解析的内容
ByteArrayOutputStream baos = new ByteArrayOutputStream();
XHTMLConverter.getInstance().convert(document, baos, options);
//带样式的内容(富文本)
String conTent = baos.toString();
//通过波浪线分割,然后通过debug去看自己需要的内容的下标位置 然后获取即可(如果不懂,私信)
String[] tableSplit = conTent.split("~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~</span></p>");
int length = tableSplit.length;
//最好是判断下length预期长度,否则模板用于定位的波浪线给破坏了,拿的内容也就变了
caseInfoVO.setCriminalBaseInfoSituation(tableSplit[2]);
caseInfoVO.setCriminalEducationTransformPlan(tableSplit[4]);
caseInfoVO.setCriminalEducationTransformResult(tableSplit[6]);
}
} catch (IOException | XWPFConverterException e) {
e.printStackTrace();
} finally {
FileUtil.deleteQuietly(destFile);
}
}
}
}
private String dealWithCaseInfoRichTextToPictureChild(String content, OssBuilder ossBuilder,Set<File> files) {
List<String> imagesFiles = HtmlUtil.regexMatchPicture(content);
if (Func.isNotEmpty(imagesFiles)) {
for (String imagesFile : imagesFiles) {
File file = new File(imagesFile);
MultipartFile fileItem = createFileItem(file, file.getName());
boolean aBoolean = true;
//此处选择循环调用,避免minio上传失败返回空(主要看需求)。
while (Boolean.TRUE.equals(aBoolean)) {
BladeFile bladeFile = ossBuilder.template().putFile(fileItem);
if (Func.isNotEmpty(bladeFile)) {
String link = bladeFile.getLink();
content = content.replace(imagesFile, link);
//删除临时图片(统一删除 如上传同一张图片,第二次会找不到图片)
files.add(file);
aBoolean = false;
}
}
}
}
return content;
}
//最好是定义一个工具类,这里图看起来比较直观,就单独拿出来了
/**
* 下载到本地路径
* @param file
* @return
* @throws IOException
*/
public File fileDownloadToLocalPath(MultipartFile file) {
File destFile = null;
try {
String fileName = file.getOriginalFilename();
//获取文件后缀
String pref = fileName.lastIndexOf(".") != -1 ? fileName.substring(fileName.lastIndexOf(".") + 1) : null;
//临时文件
//临时文件名避免重复
String uuidFile = UUID.randomUUID().toString().replace("-", "") + "." + pref;
destFile = new File(FileChangeUtils.getProjectPath() + uuidFile);
if (!destFile.getParentFile().exists()) {
destFile.getParentFile().mkdirs();
}
file.transferTo(destFile);
} catch (IOException e) {
e.printStackTrace();
}
return destFile;
}
/**
* 创建FileItem
* @param file
* @param fieldName
* @return
*/
public MultipartFile createFileItem(File file, String fieldName) {
FileItemFactory factory = new DiskFileItemFactory(16, null);
FileItem item = factory.createItem(fieldName, ContentType.MULTIPART_FORM_DATA.toString(), true, file.getName());
int bytesRead = 0;
byte[] buffer = new byte[8192];
try {
FileInputStream fis = new FileInputStream(file);
OutputStream os = item.getOutputStream();
while ((bytesRead = fis.read(buffer, 0, 8192)) != -1) {
os.write(buffer, 0, bytesRead);
}
os.close();
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
return new CommonsMultipartFile(item);
}
HtmlUtil工具类
import java.math.BigDecimal;
import java.math.RoundingMode;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author: muyangren
* @Date: 2022/12/14
* @Description:
* @Version: 1.0
*/
public class HtmlUtil {
/**
* 通过正则表达式去获取html中的src
*
* @param content
* @return
*/
public static List<String> regexMatchPicture(String content) {
//用来存储获取到的图片地址
List<String> srcList = new ArrayList<>();
//匹配字符串中的img标签
Pattern p = Pattern.compile("<(img|IMG)(.*?)(>|></img>|/>)");
Matcher matcher = p.matcher(content);
boolean hasPic = matcher.find();
//判断是否含有图片
if (hasPic) {
//如果含有图片,那么持续进行查找,直到匹配不到
while (hasPic) {
//获取第二个分组的内容,也就是 (.*?)匹配到的
String group = matcher.group(2);
//匹配图片的地址
Pattern srcText = Pattern.compile("(src|SRC)=("|')(.*?)("|')");
Matcher matcher2 = srcText.matcher(group);
if (matcher2.find()) {
//把获取到的图片地址添加到列表中
srcList.add(matcher2.group(3));
}
//判断是否还有img标签
hasPic = matcher.find();
}
}
return srcList;
}
/**
* 通过正则表达式去获取html中的src中的宽高
*
* @param content
* @return
*/
public static List<HashMap<String, String>> regexMatchWidthAndHeight(String content) {
//用来存储获取到的图片地址
List<HashMap<String, String>> srcList = new ArrayList<>();
//匹配字符串中的img标签
Pattern p = Pattern.compile("<(img|IMG)(.*?)(>|></img>|/>)");
//匹配字符串中的style标签中的宽高
String regexWidth = "width:(?<width>\d+([.]\d+)?)(px|pt)";
String regexHeight = "height:(?<height>\d+([.]\d+)?)(px;|pt;)";
Matcher matcher = p.matcher(content);
boolean hasPic = matcher.find();
//判断是否含有图片
if (hasPic) {
//如果含有图片,那么持续进行查找,直到匹配不到
while (hasPic) {
HashMap<String, String> hashMap = new HashMap<>();
//获取第二个分组的内容,也就是 (.*?)匹配到的
String group = matcher.group(2);
hashMap.put("fileUrl", group);
//匹配图片的地址
Pattern srcText = Pattern.compile(regexWidth);
Matcher matcher2 = srcText.matcher(group);
String imgWidth = null;
String imgHeight = null;
if (matcher2.find()) {
imgWidth = matcher2.group("width");
}
srcText = Pattern.compile(regexHeight);
matcher2 = srcText.matcher(group);
if (matcher2.find()) {
imgHeight = matcher2.group("height");
}
hashMap.put("width", imgWidth);
hashMap.put("height", imgHeight);
srcList.add(hashMap);
//判断是否还有img标签
hasPic = matcher.find();
}
for (HashMap<String, String> imagesFile : srcList) {
String height = imagesFile.get("height");
String width = imagesFile.get("width");
String fileUrl = imagesFile.get("fileUrl");
//1厘米=25px(像素) 17厘米(650px) word最大宽值
if (Func.isNotEmpty(width)) {
BigDecimal widthDecimal = new BigDecimal(width);
BigDecimal maxWidthWord = new BigDecimal("650.0");
if (widthDecimal.compareTo(maxWidthWord) > 0) {
BigDecimal divide = widthDecimal.divide(maxWidthWord, 2, RoundingMode.HALF_UP);
fileUrl = fileUrl.replace("width:" + width, "width:" + maxWidthWord);
if (Func.isNotEmpty(height)) {
BigDecimal heightDecimal = new BigDecimal(height);
BigDecimal divide1 = heightDecimal.divide(divide, 1, RoundingMode.HALF_UP);
fileUrl = fileUrl.replace("height:" + height, "height:" + divide1);
} else {
fileUrl = fileUrl.replace("height:auto", "height:350px");
}
imagesFile.put("newFileUrl", fileUrl);
} else {
imagesFile.put("newFileUrl", "");
}
}
}
}
return srcList;
}
}
3) 富文本导出word文档(含图片)
参考文献
链接: https://github.com/draco1023/poi-tl-ext
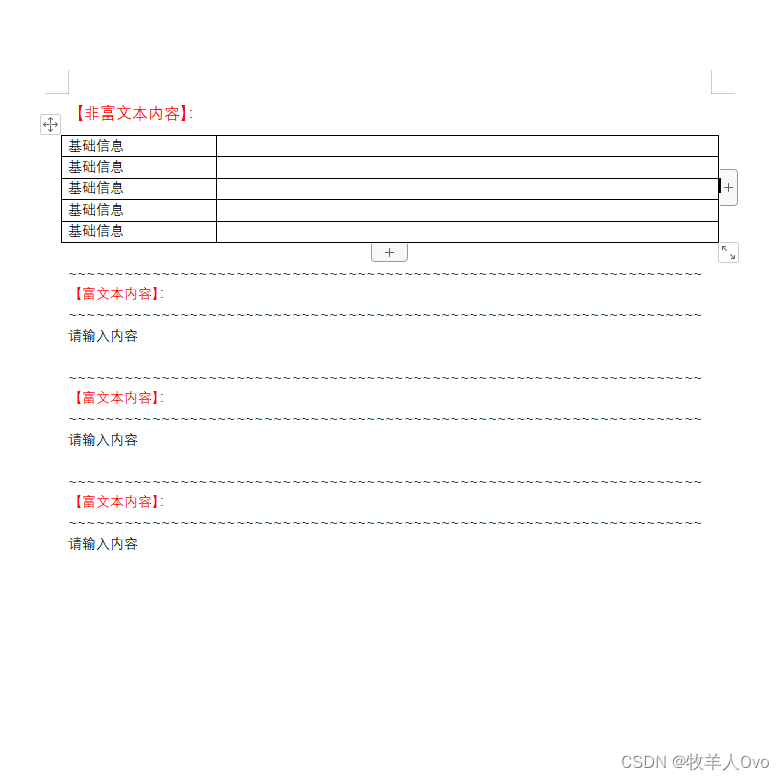
模板如图所示
Controller层
@ApiLog("模板-下载")
@GetMapping("/downloadTemplate")
@ApiOperation(value = "模板-下载")
public void downloadCaseInfo(HttpServletResponse response,CaseInfoDTO caseInfoDTO) {
caseInfoService.downloadTemplate(response,caseInfoDTO);
}
Service层
@Override
public void downloadTemplate(HttpServletResponse response, CaseInfoDTO caseInfoDTO) {
try {
//查询需要导入的数据
List<CaseInfoVO> caseInfoVOS = baseMapper.caseQueryPage(null, null, caseInfoDTO, AuthUtil.getUserId());
CaseInfoVO caseInfoVO = caseInfoVOS.get(0);
//处理作者名称
dealWithCaseAuthorName(caseInfoVOS);
Integer formatType = caseInfoVO.getFormatType();
org.springframework.core.io.Resource resource;
HtmlRenderPolicy htmlRenderPolicy = new HtmlRenderPolicy();
ConfigureBuilder builder = Configure.builder();
Configure config = builder.build();
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Map<String, Object> data = new HashMap(8);
data.put("caseTitle", caseInfoVO.getCaseTitle());
data.put("typeName", caseInfoVO.getTypeName());
resource = new ClassPathResource("document" + File.separator + "word" + File.separator + "导出模板.docx");
config.customPolicy("criminalBaseInfoSituation", htmlRenderPolicy);
data.put("criminalBaseInfoSituation", dealWithPictureWidthAndHeight(caseInfoVO.getCriminalBaseInfoSituation()));
//输出到浏览器|下载到本地路径
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append(caseInfoVO.getTenantName()).append("-").append(caseInfoVO.getTypeName()).append("-《").append(caseInfoVO.getCaseTitle()).append("》").append("案例");
response.setContentType("application/octet-stream");
response.setHeader("Content-disposition", "attachment;filename="" + new String(stringBuilder.toString().getBytes(StandardCharsets.UTF_8), StandardCharsets.ISO_8859_1) + ".docx" + """);
OutputStream out = response.getOutputStream();
XWPFTemplate.compile(resource.getInputStream(), config).render(data).writeAndClose(out);
out.flush();
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
//处理图片超过word宽度问题,等比缩小
private String dealWithPictureWidthAndHeight(String content) {
List<HashMap<String, String>> imagesFiles = HtmlUtil.regexMatchWidthAndHeight(content);
if (Func.isNotEmpty(imagesFiles)) {
for (HashMap<String, String> imagesFile : imagesFiles) {
String newFileUrl = imagesFile.get("newFileUrl");
String fileUrl = imagesFile.get("fileUrl");
if (Func.isNotEmpty(newFileUrl)){
content = content.replace(fileUrl, newFileUrl);
}
}
}
return content;
}
原文地址:https://blog.csdn.net/m0_51706962/article/details/128818754
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_16223.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。