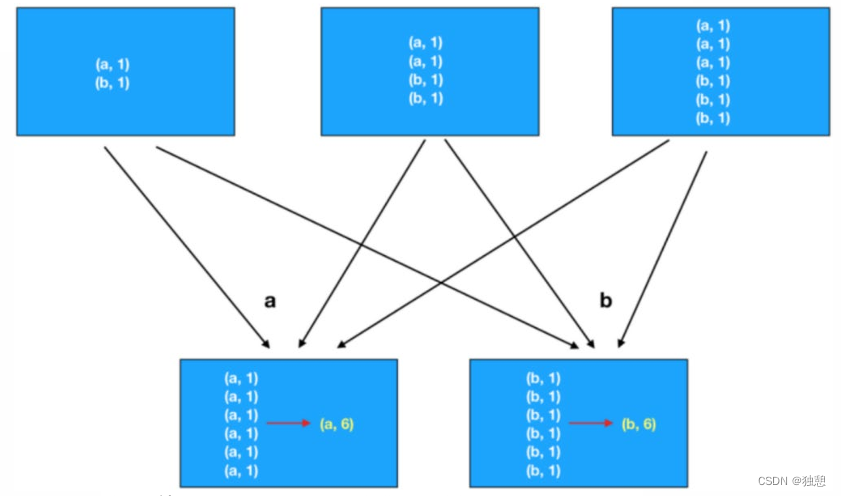
本文介绍: 在上述实验中,我们设置全局env的并行度为2,尝试执行2次job,发现2次执行的结果不一致,因为shuffle的完全随机性,将输入流分配到不同的分区中,且每次分配可能不一样。这种做法非常极端,通过调用.global()方法,会将所有的输入流数据都发送到下游算子的第一个并行子任务中去。通过调用 DataStream 的.shuffle()方法,将数据随机地分配到下游算子的并行任务中去。这种方式其实不应该叫做“重分区”,因为经过广播之后,数据会在不同的分区都保留一份,可能进行重复处理。
Flink 物理分区算子(Physical Partitioning)
在Flink中,常见的物理分区策略有:随机分配(Random)、轮询分配(Round-Robin)、重缩放(Rescale)和广播(Broadcast)。
接下来,我们通过源码和Demo分别了解每种物理分区算子的作用和区别。
(1) 随机分区(shuffle)
最简单的重分区方式就是直接“洗牌”。通过调用 DataStream 的.shuffle()方法,将数据随机地分配到下游算子的并行任务中去。
随机分区服从均匀分布(uniform distribution),所以可以把流中的数据随机打乱,均匀地传递到下游任务分区。因为是完全随机的,所以对于同样的输入数据, 每次执行得到的结果也不会相同。
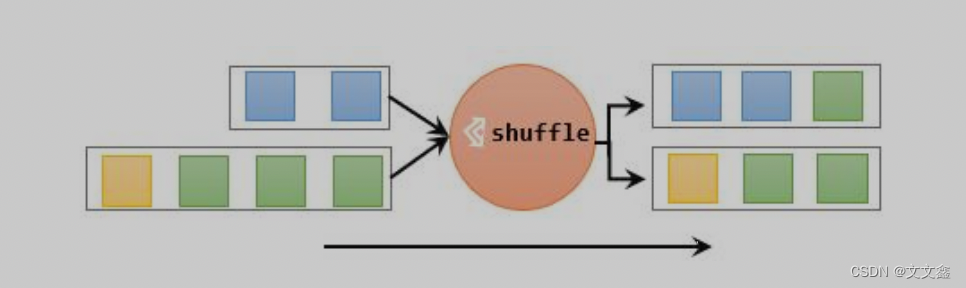

经过随机分区之后,得到的依然是一个 DataStream。
我们可以做个简单测试:将数据读入之后直接打印到控制台,将输出的并行度设置为 2,
中间经历一次 shuffle。执行多次,观察结果是否相同。
在上述实验中,我们设置全局env的并行度为2,尝试执行2次job,发现2次执行的结果不一致,因为shuffle的完全随机性,将输入流分配到不同的分区中,且每次分配可能不一样。
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。