XPath定义
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。它最初是用来搜寻 XML 文档的,现在它同样适用于 HTML 文档的搜索
XPath 概览
XPath 的选择功能十分强大,它提供了非常简洁明了的路径选择表达式 。 另外,它还提供了超过100 个内建函数,用于字符串、数值、时间的匹配以及节点、序列的处理等 。 几乎所有我们想要定位的节点,都可以用 XPath 来选择 。
安装lxml
pip install lxml
初步使用
读取本地html文件
etree模块会自动修正HTML文件中缺失的内容
from lxml import etree
# 读取html文档,字符串
fp = open("index.html",'r',encoding='utf-8')
html = fp.read()
# 实例化XPath解析对象,可以将字符串转换成Element对象
tree = etree.HTML(html)
print(tree)
from lxml import etree
import requests
html = requests.get(url="https://www.baidu.com")
tree = etree.HTML(html.text)
print(tree)
xpath 常用表达式
xpath的使用其实就是根据表达式找出文档中所有符合条件的内容
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从当前节点选取直接子节点 |
| // | 从当前节点选取子孙节点 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
| * | 通配符,选择所有元素节点与元素名 |
| [@attrib] | 选取具有给定属性的所有元素 |
| [@attrib=‘value’] | 选取给定属性具有给定值的所有元素 |
| [tag] | 选取所有具有指定元素的直接子节点 |
| [tag=‘text’] | 选取所有具有指定元素并且文本内容是text节点 |
获取所有节点
fp = open("index.html",'r',encoding='utf-8')
html = fp.read()
tree = etree.HTML(html)
result = tree.xpath("//*") # 获取所有节点
print(result)

获取子孙节点中的div节点
# 获取当前节点下的所有div的子孙节点
result = tree.xpath("//div")
输出:

获取子节点
现在要获取<html>下的head节点以及head节点里面的title节点
result = tree.xpath("/html/head") # 获取head节点
print(result)
result = tree.xpath("/html/head/title") # 获取title节点
print(result)
输出:
解释:这里我们采用的是 /来进行获取的,每次获取一级,依次获取到目标元素
获取父亲节点
通过 / 、//可以获取子节点或者子孙节点,现在我学习如何通过子节点找父节点
result = tree.xpath("//li/..")
print(result)
result = tree.xpath("//li/../..")
print(result)
输出:

通过输出我们可以看到li的父节点是ul, ul的父节点是div
解释:
先通过 //li找到li节点在通过 .. 找到父节点
属性匹配
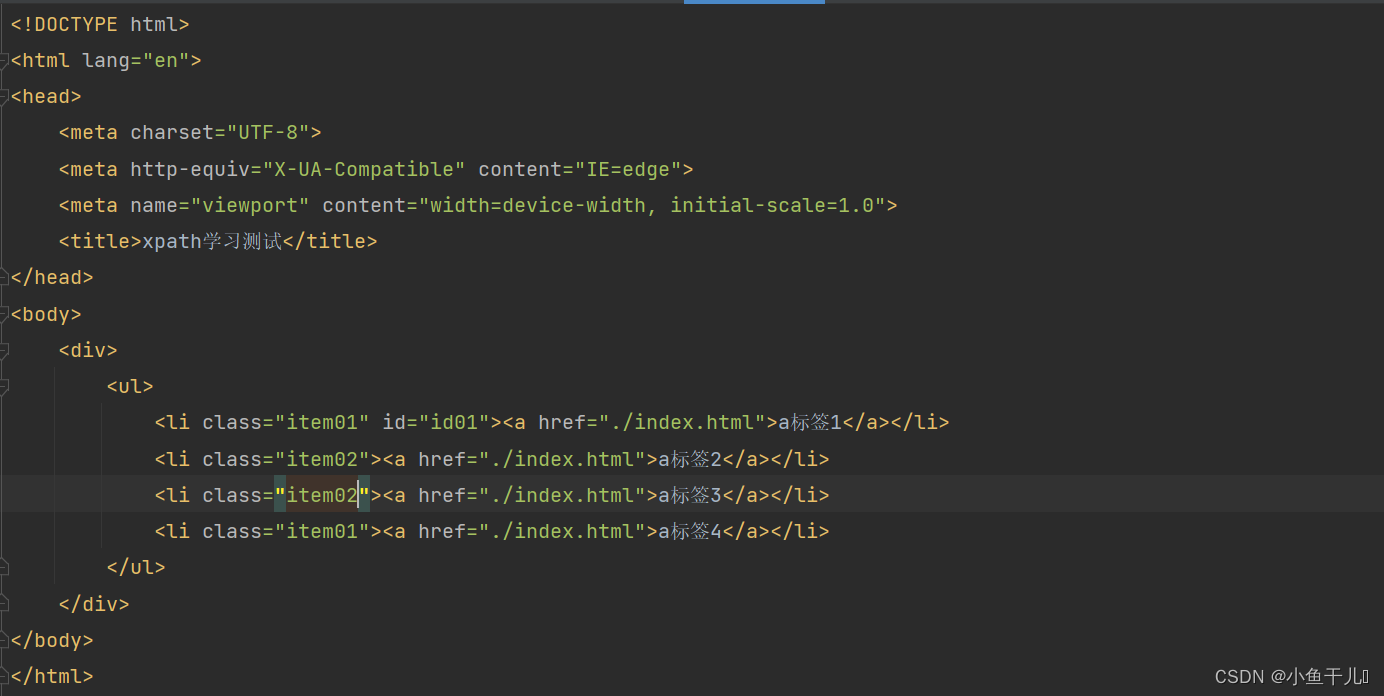
result = tree.xpath('/html/body/div/ul/li[@class="item01"]')
print(result)
输出:

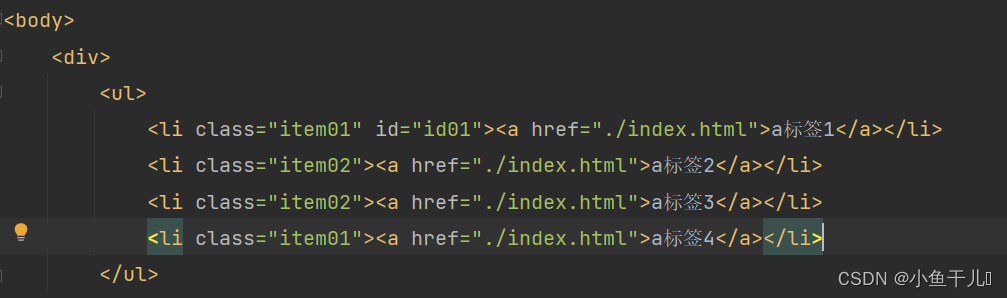
选择属性中有id的
result = tree.xpath('/html/body/div/ul/li[@id]')
print(result)
输出:

解释:
通过@ 我们可以根据属性寻找节点,可以指定属性值,也可以直接根据属性进行查询
获取文本
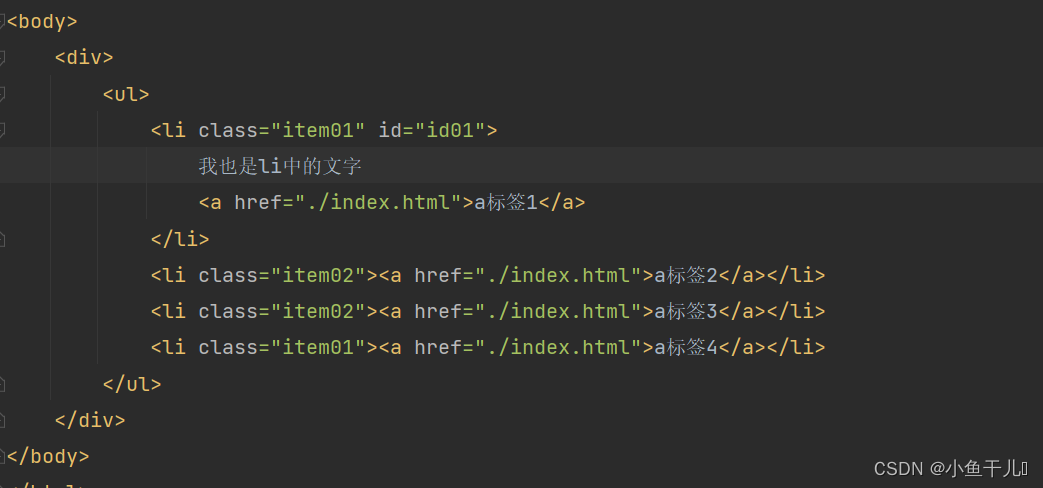
获取li中的文字
# 直接获取li标签下面所有子孙元素的文字
result = tree.xpath('/html/body/div/ul/li//text()')
print(result)
# 通过寻找子元素的方式,一级一级的找到文字
result2 = tree.xpath('/html/body/div/ul/li/a/text()')
print(result2)
输出:

通过输出的内容分析我们能够看出,直接通过li//text()获取到文本内容会比li/a/text()获取的多,因为li//text()或获取li中所有的文字包括换行,而li/a/text()只会找出a标签下所有的文字
获取属性
有时候我们在进行数据解析的时候会需要一些属性值,例如我们在写爬虫项目的时候我们往往需要url链接
result = tree.xpath('/html/body/div/ul/li[@id="id01"]/a/@href')
print(result)
输出

解释:
属性值的获取也是通过@ 来进行实现的,@href:获取href的属性值
属性多值匹配
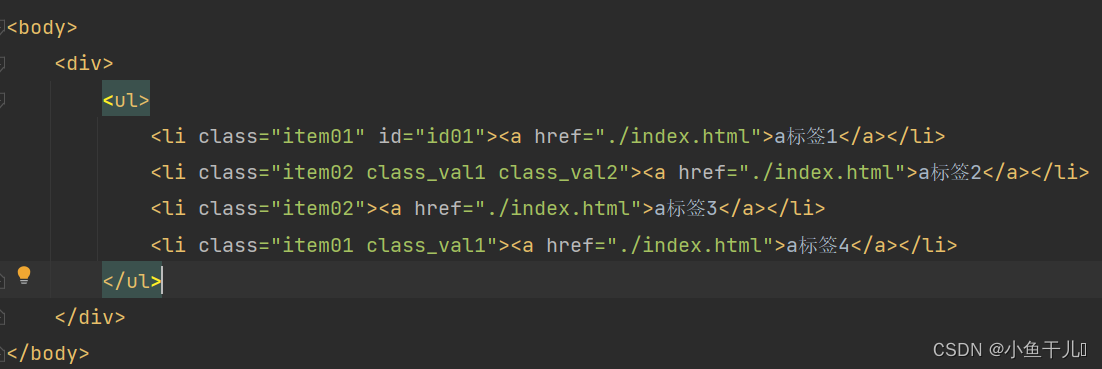
在实际的项目中会出现一个属性值有多个值的情况出现,例如class在实际项目中会有多个值的情况出现
# 这种方式是错误的,并不会找出对应的class中含有class_val1的节点
tree.xpath('/html/body/div/ul/li[@class="class_val1"]')
# 正确的做法 使用contains()函数
# 获取class中含有class_val1的节点
result = tree.xpath('/html/body/div/ul/li[contains(@class,"class_val1")]')
print(result)
输出:

解释:
contains()函数 获取指定属性中包含某一属性值的节点
使用方式contains(@属性,"属性值")
多属性匹配
找出li中 class中含有item01且id=id01 中a标签中的文本
result = tree.xpath('/html/body/div/ul/li[contains(@class,"item01") and @id="id01"]/a/text()')
print(result)

拓展类似的操作符还有
| 运算符 | 描述 | 实例 | 返回值 |
|---|---|---|---|
| or | 或 | age=10 or age=20 | 如果age等于10或者等于20则返回true反正返回false |
| and | 与 | age>19 and age<21 | 如果age等于20则返回true,否则返回false |
| mod | 取余 | 5 mod 2 1 | |
| | | 取两个节点的集合 | //book | //cd | 返回所有拥有book和cd元素的节点集合 |
| + | 加 | 5+4 | 9 |
| – | 减 | 5-4 | 1 |
| * | 乘 | 5*4 | 20 |
| div | 除法 | 6 div 3 | 2 |
| = | 等于 | age=10 | true |
| != | 不等于 | age!=10 | true |
| < | 小于 | age<10 | true |
| <= | 小于或等于 | age<=10 | true |
| > | 大于 | age>10 | true |
| >= | 大于或等于 | age>=10 | true |
按序选择
在有些时候我们在选择的时候可能匹配了多个节点,但是我们可能只需要其中的某些节点,xpath为我们提供了可以 根据索引进行取值的操作。
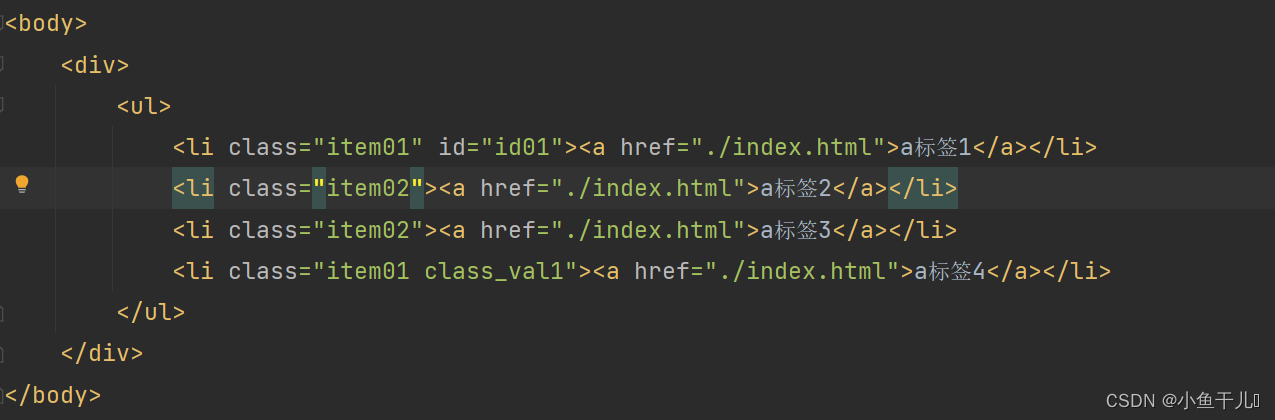
获取第一个li标签
获取前三个li标签
获取最后一个li标签
# 获取第一个`li`标签
result = tree.xpath('/html/body/div/ul/li[1]')
print(result)
# 获取前三个`li`标签
result2 = tree.xpath('/html/body/div/ul/li[position()<4]')
print(result2)
# 获取最后一个`li`标签
result3 = tree.xpath('/html/body/div/ul/li[last()]')
print(result3)
输出:

解释:
position() 返回当前正在被处理的节点的 index 位置
last() 返回所有匹配节点的最后一个的索引
节点轴选择
获取li的所有的祖先节点
result = tree.xpath('/html/body/div/ul/li/ancestor::*')
print(result)
输出:

获取li祖先节点中的div
result = tree.xpath('/html/body/div/ul/li/ancestor::div')
print(result)
输出:

获取li节点的子孙元素
result = tree.xpath('/html/body/div/ul/li/child::*')
print(result)
获取li节点的子孙元素中a标签中href="./index.html"
result = tree.xpath('/html/body/div/ul/li/child::a[@href="./index.html"]')
print(result)
解释:
ancestor、child都称作轴 ancestor轴就是相对当前节点的所有祖先节点的集合,child轴就是相对当前节点的子孙节点的集合,而后面::后面跟着是对轴节点集合的操作 *代表匹配所有的节点 div 代表取节点集中的div节点,
另外还可以使用其他的筛选条件进行筛选child::a[@href="./index.html"]:选取子孙节点中a节点中href="./index.html"的节点,上面学习的筛选方式都可以在这里使用。
类似这样的轴还有很多
| 轴名称 | 结果 |
|---|---|
| ancestor | 选取当前节点的所有先辈(父、祖父等)。 |
| ancestor-or-self | 选取当前节点的所有先辈(父、祖父等)以及当前节点本身。 |
| attribute | 选取当前节点的所有属性。 |
| child | 选取当前节点的所有子元素。 |
| descendant | 选取当前节点的所有后代元素(子、孙等)。 |
| descendant-or-self | 选取当前节点的所有后代元素(子、孙等)以及当前节点本身。 |
| following | 选取文档中当前节点的结束标签之后的所有节点。 |
| namespace | 选取当前节点的所有命名空间节点。 |
| parent | 选取当前节点的父节点。 |
| preceding | 选取文档中当前节点的开始标签之前的所有节点。 |
| preceding-sibling | 选取当前节点之前的所有同级节点。 |
| self | 选取当前节点。 |
xpath轴的使用方式都是一样的,在实际中我们只需要根据自己的需求选择合适的轴。
总结
关于lxml和xpath的教学大概就有这么多,这类教程很多用法都不便于讲解,这里只是提供一些用法,后续如果想熟练的使用xpath解析数据还需要勤加练习,结合自己的实际情况进行选择具体的xpath,
在使用一段时间后你可能会发现最常用的也就最基础的获取子节点、获取子孙节点、获取文本、获取属性值。这些也足够你解决你遇到的绝大部分问题,后面关于xpath轴的或许在实际中没等你想到就将问题解决了。但是我还是建议你学习,在我们看别人的代码的时候别人可能会用,我们平时可以不会写但是见到这样的代码的时候一定要认识。

原文地址:https://blog.csdn.net/qq_52007481/article/details/128520899
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_16433.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!