今天来看看架构的演变过程
一、单体架构

从图中可以看到,所有服务耦合在一起,数据库存在单点,一旦其中一个服务出现问题时,整个工程都需要重新发布,从而导致整个业务不能提供响应
这种架构对于小项目而言是没有什么问题的,反而更加灵活,但是当业务量暴增的时候,就无法灵活应对了
二、第一次切分
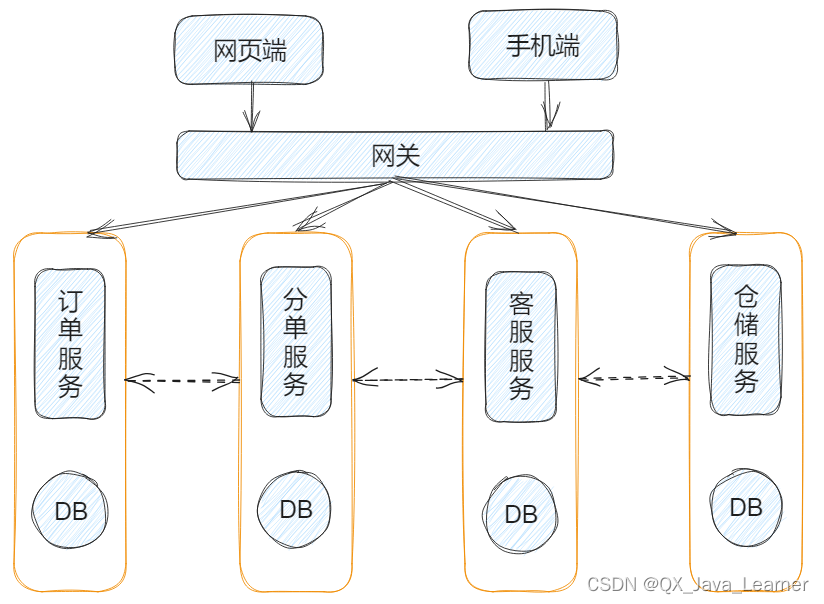
单体架构无法满足业务增长的需求,需要对数据库进行进一步的切分,以提高扩展性
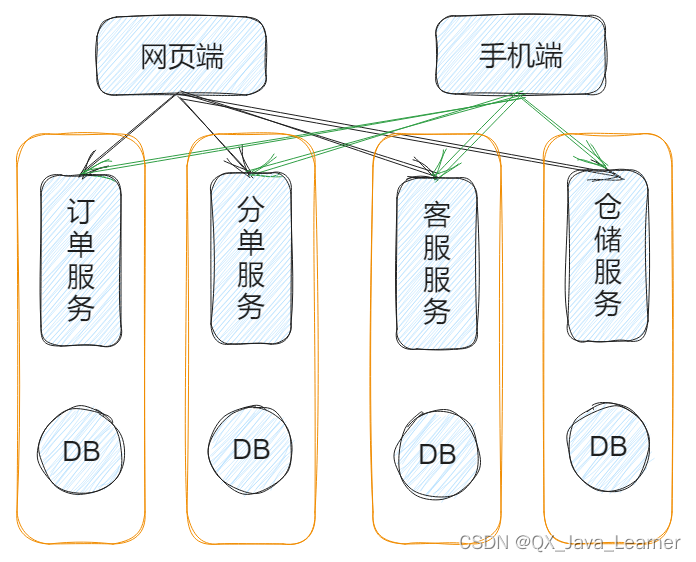
三、服务拆分带来的问题
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。